1、DCNN模型
DCNN是由Nal Kalchbrenner[1]等人于2014年提出的一种算法,其利用CNN模型将输入进行卷积操作,并利用K-MAX pooling操作,最终将变长的文本序列输出为定长的序列,这种方式能够获取短文本和长文本之间的关系。文章在4个数据集进行了测试。
DCNN模型结构如下图所示
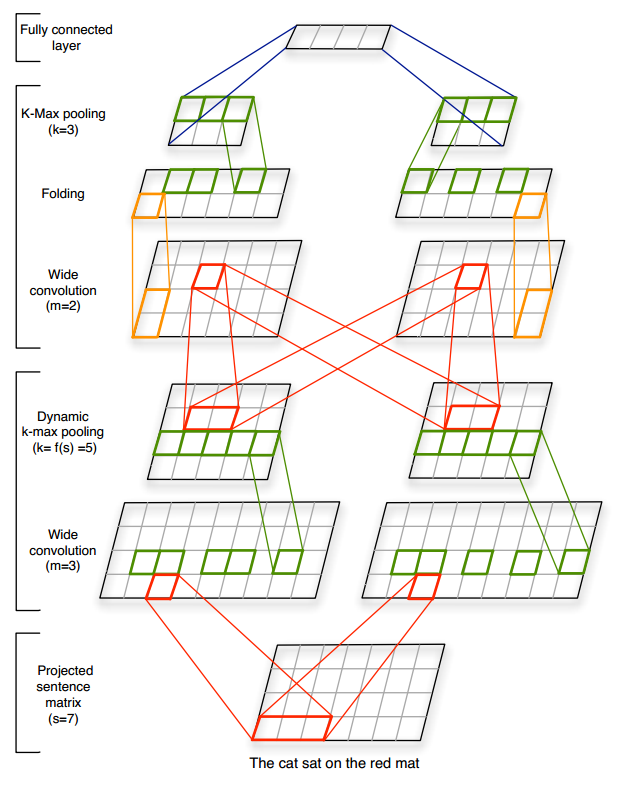
- projected sentence matrix
首先,我们将输入的单词通过embedding_lookup,得到输入单词的词向量。如图,输入为[7,4]的向量 - wide convolution
我们用两个滤波器,分别对原始的词表进行卷积操作,这里设置m=3,即每3个单词进行一次卷积操作,由图可知,滤波器的维度是3,这里会在词表前后分别加上两维的padding,这里的操作只对每3个单词的第一维进行卷积。最终我们会得到两个[9,4]的矩阵。 - dynamic k-max pooling
对每一个维度进行pooling操作,这里k=5,即取最大的5个元素,结果进行拼接,这里有两个滤波器,得到两个[5,4]的矩阵。这里的k是动态获取的,根据公式(k_{l} = max(k_{top}, lceil frac {L-l}{L} * s ceil)) 。其中(k_{top})为用户自己设定,这里(k_{top} = 3),L表示全部卷积的数量,s表示输入的长度,这里(s=18),所以,(k_{1} = max(3,((3-1)/3) * 18) = 12), (k_{2} = max(3,((3-2)/3) * 18) = 6),(k_{3} = max(3,((3-3)/3) * 18) = 3)。 - wide convolution
再次进行一次卷积操作,这里的m=2,有两个滤波器,我们用这两个滤波器 分别对上一层的输出进行卷积,并将各自的结果进行加和,得到两个[6,4]的输出, - fodding
这里的维度为4,我们将其平均分成两部分,每一部分为2,我们将各自的两维进行加和,得到两个[6,2]的矩阵 - dynamic k-max pooling
如上,再次进行pooling操作,得到两个[3,2]维矩阵 - Fully connected layer
最后,我们进行一个全连接操作,将结果维度进行固定,接下来,我们就可以利用一些softmax操作,来根据分类结果计算loss了。
2、TextCNN模型
TextCNN可以理解为是DCNN的简化版本,但是在数据集上取得了不错的效果,TextCNN是由Yoon Kim[2]提出的一种算法,提出了不同的单词embedding方法,分别是CNN-rand,CNN-static,CNN-non-static,CNN-mutichannel,其基本结构如下图所示

TextCNN的结构和DCNN基本相似,第一层,我们先得到单词的embedding,接着,用不同的滤波器进行卷积操作,然后用max-pooling方式进行池化操作,最后加上一个全连接操作,进行softmax输出。可以看到,TextCNN几乎是DCNN的简化版本。
- CNN-rand
对单词的embedding信息随机的初始化 - CNN-static
用word2vec进行训练词向量,并且在训练时固定词向量 - CNN-non-static
用word2vec进行训练词向量,词向量随着训练进行微调 - CNN-mutichannel
输入时含有两个词向量,分别成为两个通道,其中一个用word2vec进行训练并在CNN训练时进行固定,另外一个随机初始化,并在CNN训练时随着训练调整它的参数。
3、XML-CNN模型
XML-CNN主要是针对大规模多标记数据提出的一种算法,是由Jingzhou Liu[3]等人提出的,其主要贡献有三点:a、使用k-max-pooling方法来尽可能多的加入特征信息。b、在池化层和输出层加入一个全连接层,以减少参数的更新。c、输出层使用sigmoid激活函数,损失函数使用cross-entropy。其网络结构如下图所示
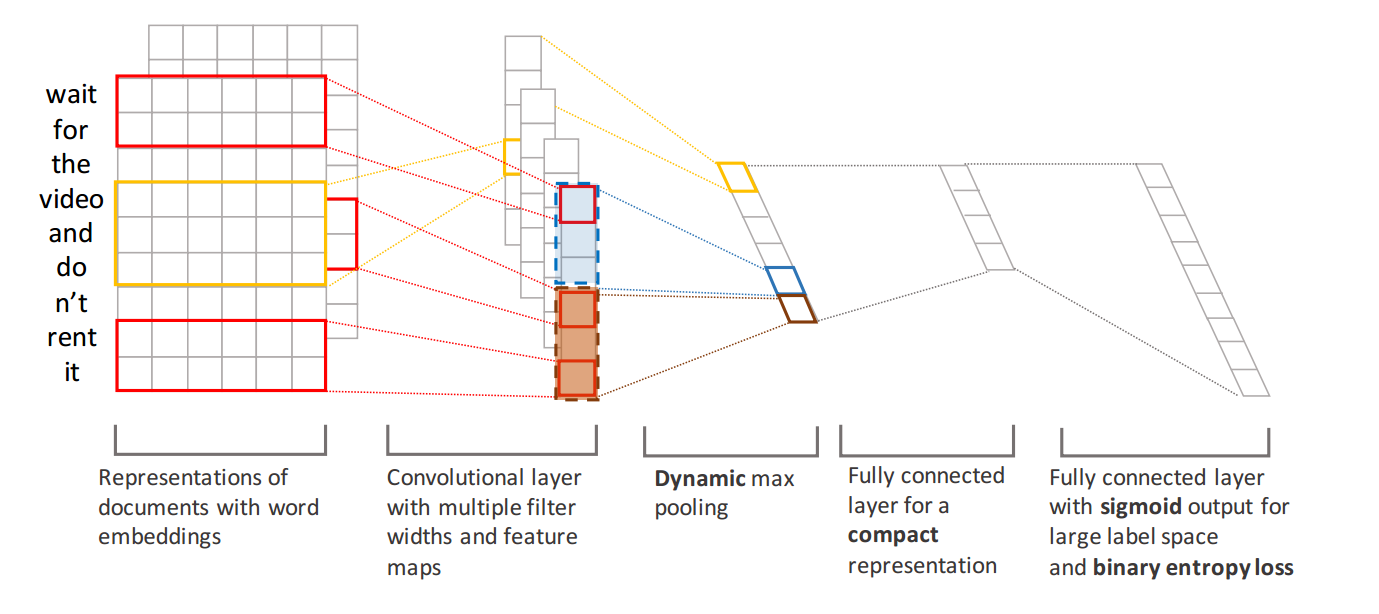
首先,输入层依然是单词的embedding信息,经过多个滤波器,进行卷积操作,接着我们使用k-max-pooling,其目的是为了更多的获取特征,有时候,往往最大的特征不能代表某个类别,所以加入最大的k个特征。接下来我们在池化层和输出层加入一个全连接层,加入这个层的目的是减少参数的更新,如果不加入这个全连接层,那么每次参数更新是k * L,k表示池化层输出节点数,L表示输出层节点数,加入了一个全连接层,参数更新就变成了k * F + F * L,F表示全连接层节点数,其中F远远小于L。最后输出层使用sigmoid激活函数,并使用cross-entropy构造损失函数。
4、Character-level CNN模型
顾名思义,Character-level CNN模型输入的并不是完整的词汇,而是字符序列,在论文中,作者输入的字符个数是70个,其中包括字母,数字和一些特殊符号等,特征的维度设置为1024,对于没有在这70个字符中的字符,用全0表示。其结构如下图所示

可以看到,输入序列经过了一次卷积和池化操作,紧接着经过了6层卷积操作,池化操作和3层全连接操作,其中卷积操作分为1个大步长和1个小步长,其参数如下图所示
卷积和池化操作

全连接操作

5、VDCNN模型
VDCNN模型是在深度上进行增加,以达到一个较好的效果,其由facebook 的Alexis Conneau[5]等人提出,模型输入是以字符为单位,输入的长度固定为s=1024。受到VGG和ResNets的启发,模型在池化操作后遵循如下原则
- 对于相同的输出特征图大小,图层有相同数量的滤波器
- 如果特征图的大小被减半,过滤器的数量增加一倍
如下是完整的模型架构图,我们分别来对每一个步骤进行讲解

输入层是一个(1024)的字符向量,经过embedding_lookup后,得到(1024 * 16)的二维矩阵,其中16为每个字符的维度。
接下来进行一步卷积操作,其中窗口大小为3,滤波器 的数量是64,在这一步,其实在矩阵的开始和结束加上了两个padding,所以输入的向量是(1026,16),这样经过一次窗口长度为3的卷积,可以得到大小为(1024 * 1)的卷积结果,由于滤波器数量为64,所以最终的结果是(1024 * 64)维的矩阵。
接下来通过两个Convolutional Block,窗口大小为3,滤波器数量为64,在每一步的卷积操作中,都在开始和结束加入了两个padding,这样做的目的是为了得到固定维度的输出,后续也都是一样的,不再做特殊的说明。
接下来进行池化操作,得到(512 * 64)的矩阵输出,根据上述原则,我们需要增加滤波器的数量,即64 * 2=128
进行卷积操作,窗口大小为3,对矩阵(512 * 64)进行卷积操作,得到(512 * 1)由于是128个滤波器,所以结果是(512 * 128)
接下来的操作和上述一样,最终会得到一个(128 * 512)的矩阵,接着进行池化操作,这里k=8,所以输出为(8 * 512)
接着,进行两个全连接层的操作,下游的任务可以根据我们的需要进行设置,比如对分类来说,输出即为标签的数量。
我们这里还有一点没有说明,就是Convolutional Block是个什么东西,其实很简单,也是一系列的卷积操作,如下图所示

[2]Yoon Kim(2014)Convolutional Neural Networks for Sentence Classification
[3]Jingzhou Liu(2015)Deep Learning for Extreme Multi-label Text Classification
[4]Xiang Zhang(2015)Character-level Convolutional Networks for Text Classification
[5]Alexis Conneau(2017)Very Deep Convolutional Networks for Text Classification