《机器学习十讲》第一讲
一、大数据:数据采集、数据清洗、数据分析和数据应用的整个流程中的理论、技术和方法。
机器学习:大数据分析的核心内容。找到将X和Y关联的模型F。
深度学习:机器学习的一部分,核心是自动找到对特定任务有效的特征,即自动完成Data到X的转换。
二、机器学习的方法
1、有监督学习
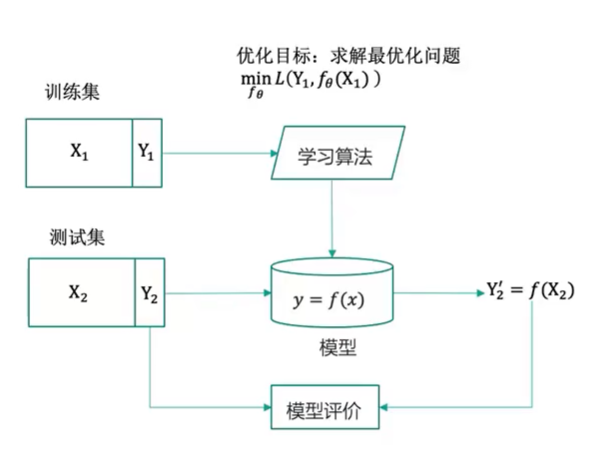
数据集中的样本带有标签(Y),有明确目标(找到最佳映射F);回归和分类。
一般流程:
2、无监督学习
数据集中的样本没有标签,没有明确目标;聚类、降维、排序、密度估计、关联规则挖掘。
3、强化学习
智慧决策的过程,通过过程模拟和观察来不断学习,提高决策能力。
智能体agent;环境environment;状态state;行动action;奖励reward。
三、模型选择
1、交叉验证:重复使用数据
2、K折交叉验证
四、数据的数学结构
1、度量结构
举例:根据词频计算文章相似度
K近邻算法
k-d树
2、网络结构
PageRank算法
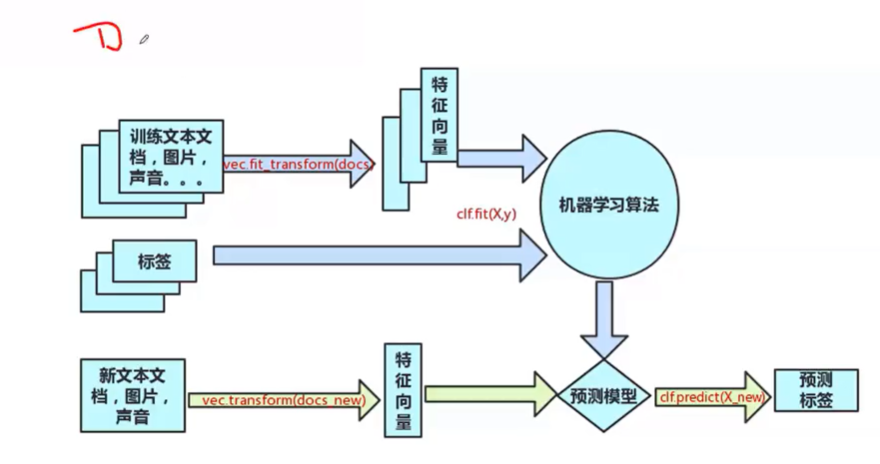
3、Scikit-learn
基本建模流程
常用函数

案例1:使用KNN对新闻主题进行自动分类
1、数据读取:pandas
2、数据分词:jieba
3、将新闻表示为向量
4、构建KNN分类器
5、测试集预测
6、效果评估:混淆矩阵
案例2:使用PageRank对全球机场进行排序
1、网络读取:networkx
2、找出最大连通子图,可视化
3、使用PageRank算法对机场排序
4、将节点大小与PageRank值关联并可视化