1.MyBatis一般使用步骤
1.1获取Configuration实例或编写配置文件

//获取Configuration实例的样例
TransactionFactory transactionFactory = new JdbcTransactionFactory();//定义事务工厂
Environment environment =
new Environment("development", transactionFactory, dataSource);
Configuration configuration = new Configuration(environment);
configuration.addMapper(BlogMapper.class);
配置文件的编写请看2
1.2生成SqlSessionFactory实例(一个数据库对应一个SqlSessionFactory)
//通过Configuration实例生成SqlSessionFactory SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration); //通过xml配置文件方式生成SqlSessionFactory String resource = "org/mybatis/example/Configuration.xml"; Reader reader = Resources.getResourceAsReader(resource); sqlSessionFactory= new SqlSessionFactoryBuilder().build(reader);
1.3生成SqlSession实例
//样例 SqlSession session = sqlSessionFactory.openSession();
1.4执行sql各种操作
//样例
try {
Blog blog = (Blog) session.selectOne(
"org.mybatis.example.BlogMapper.selectBlog", 101);
} finally {
session.close();
}
2.MyBatis的配置文件解析
2.1配置文件的基本结构
- configuration —— 根元素
- properties —— 定义配置外在化
- settings —— 一些全局性的配置
- typeAliases —— 为一些类定义别名
- typeHandlers —— 定义类型处理,也就是定义java类型与数据库中的数据类型之间的转换关系
- objectFactory
- plugins —— Mybatis的插件,插件可以修改Mybatis内部的运行规则
- environments —— 配置Mybatis的环境
- environment
- transactionManager —— 事务管理器
- dataSource —— 数据源
- environment
- databaseIdProvider
- mappers —— 指定映射文件或映射类
2.2 properties元素——定义配置外在化
<!--样例--> <properties resource="org/mybatis/example/config.properties"> <property name="username" value="dev_user"/> <property name="password" value="F2Fa3!33TYyg"/> </properties>
配置外在化的属性还可以通过SqlSessionFactoryBuilder.build()方法提供,如:
SqlSessionFactory factory = sqlSessionFactoryBuilder.build(reader, props);
配置外在化的优先级是 build方法->resource属性指定的文件->property元素
2.3 settings元素——Mybatis的一些全局配置属性
| 设置参数 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| cacheEnabled | 这个配置使全局的映射器启用或禁用 缓存。 | true | false | true |
| lazyLoadingEnabled | 全局启用或禁用延迟加载。当禁用时, 所有关联对象都会即时加载。 | true | false | true |
| aggressiveLazyLoading | 当启用时, 有延迟加载属性的对象在被 调用时将会完全加载任意属性。否则, 每种属性将会按需要加载。 | true | false | true |
| multipleResultSetsEnabled | 允许或不允许多种结果集从一个单独 的语句中返回(需要适合的驱动) | true | false | true |
| useColumnLabel | 使用列标签代替列名。 不同的驱动在这 方便表现不同。 参考驱动文档或充分测 试两种方法来决定所使用的驱动。 | true | false | true |
| useGeneratedKeys | 允许 JDBC 支持生成的键。 需要适合的 驱动。 如果设置为 true 则这个设置强制 生成的键被使用, 尽管一些驱动拒绝兼 容但仍然有效(比如 Derby) | true | false | False |
| autoMappingBehavior | 指定 MyBatis 如何自动映射列到字段/ 属性。PARTIAL 只会自动映射简单, 没有嵌套的结果。FULL 会自动映射任 意复杂的结果(嵌套的或其他情况) 。 | NONE, PARTIAL, FULL | PARTIAL |
| defaultExecutorType | 配置默认的执行器。SIMPLE 执行器没 有什么特别之处。REUSE 执行器重用 预处理语句。BATCH 执行器重用语句 和批量更新 | SIMPLE REUSE BATCH | SIMPLE |
| defaultStatementTimeout | 设置超时时间, 它决定驱动等待一个数 据库响应的时间。 | Any positive integer | Not Set (null) |
| safeRowBoundsEnabled | Allows using RowBounds on nested statements. | true | false | False |
| mapUnderscoreToCamelCase | Enables automatic mapping from classic database column names A_COLUMN to camel case classic Java property names aColumn. | true | false | False |
| localCacheScope | MyBatis uses local cache to prevent circular references and speed up repeated nested queries. By default (SESSION) all queries executed during a session are cached. If localCacheScope=STATEMENT local session will be used just for statement execution, no data will be shared between two different calls to the same SqlSession. | SESSION | STATEMENT | SESSION |
| jdbcTypeForNull | Specifies the JDBC type for null values when no specific JDBC type was provided for the parameter. Some drivers require specifying the column JDBC type but others work with generic values like NULL, VARCHAR or OTHER. | JdbcType enumeration. Most common are: NULL, VARCHAR and OTHER | OTHER |
| lazyLoadTriggerMethods | Specifies which Object's methods trigger a lazy load | A method name list separated by commas | equals,clone,hashCode,toString |
2.4 typeAliases元素——定义类别名,简化xml文件的配置,如:
<typeAliases> <typeAlias alias="Author" type="domain.blog.Author"/> <typeAlias alias="Blog" type="domain.blog.Blog"/> <typeAlias alias="Comment" type="domain.blog.Comment"/> <typeAlias alias="Post" type="domain.blog.Post"/> <typeAlias alias="Section" type="domain.blog.Section"/> <typeAlias alias="Tag" type="domain.blog.Tag"/> </typeAliases>
Mybatis还内置了一些类型别名:
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
2.5 typeHandlers元素
每当MyBatis 设置参数到PreparedStatement 或者从ResultSet 结果集中取得值时,就会使用TypeHandler 来处理数据库类型与java 类型之间转换。
2.5.1 自定义typeHandlers
- 实现TypeHandler接口

 View Code
View Code - 在配置文件中声明自定义的TypeHandler
View Code
2.5.2 Mybatis内置的TypeHandler
| 类型处理器 | Java 类型 | JDBC 类型 |
|---|---|---|
| BooleanTypeHandler | java.lang.Boolean, boolean | 任何兼容的布尔值 |
| ByteTypeHandler | java.lang.Byte, byte | 任何兼容的数字或字节类型 |
| ShortTypeHandler | java.lang.Short, short | 任何兼容的数字或短整型 |
| IntegerTypeHandler | java.lang.Integer, int | 任何兼容的数字和整型 |
| LongTypeHandler | java.lang.Long, long | 任何兼容的数字或长整型 |
| FloatTypeHandler | java.lang.Float, float | 任何兼容的数字或单精度浮点型 |
| DoubleTypeHandler | java.lang.Double, double | 任何兼容的数字或双精度浮点型 |
| BigDecimalTypeHandler | java.math.BigDecimal | 任何兼容的数字或十进制小数类型 |
| StringTypeHandler | java.lang.String | CHAR 和 VARCHAR 类型 |
| ClobTypeHandler | java.lang.String | CLOB 和 LONGVARCHAR 类型 |
| NStringTypeHandler | java.lang.String | NVARCHAR 和 NCHAR 类型 |
| NClobTypeHandler | java.lang.String | NCLOB 类型 |
| ByteArrayTypeHandler | byte[] | 任何兼容的字节流类型 |
| BlobTypeHandler | byte[] | BLOB 和 LONGVARBINARY 类型 |
| DateTypeHandler | java.util.Date | TIMESTAMP 类型 |
| DateOnlyTypeHandler | java.util.Date | DATE 类型 |
| TimeOnlyTypeHandler | java.util.Date | TIME 类型 |
| SqlTimestampTypeHandler | java.sql.Timestamp | TIMESTAMP 类型 |
| SqlDateTypeHandler | java.sql.Date | DATE 类型 |
| SqlTimeTypeHandler | java.sql.Time | TIME 类型 |
| ObjectTypeHandler | Any | 其他或未指定类型 |
| EnumTypeHandler | Enumeration Type | VARCHAR-任何兼容的字符串类型, 作为代码存储(而不是索引) |
| EnumOrdinalTypeHandler | Enumeration Type | Any compatible NUMERIC or DOUBLE, as the position is stored (not the code itself). |
2.6 objectFactory元素——用于指定结果集对象的实例是如何创建的。
下面演示了如何自定义ObjectFactory
1.继承DefaultObjectFactory
View Code
// ExampleObjectFactory.java
public class ExampleObjectFactory extends DefaultObjectFactory {
public Object create(Class type) {
return super.create(type);
}
public Object create(
2.在配置文件中配置自定义的ObjectFactory
View Code
// MapperConfig.xml <objectFactory type="org.mybatis.example.ExampleObjectFactory"> <property name="someProperty" value="100"/> </objectFactory>
2.7 plugins元素
MyBatis 允许您在映射语句执行的某些点拦截方法调用。默认情况下,MyBatis 允许插件(plugins)拦截下面的方法:
- Executor (update, query, flushStatements, commit, rollback, getTransaction, close, isClosed)
- ParameterHandler (getParameterObject, setParameters)
- ResultSetHandler (handleResultSets, handleOutputParameters)
- StatementHandler (prepare, parameterize, batch, update, query)
下面是自定义plugin示例:
- 实现Interceptor接口,并用注解声明要拦截的方法
// ExamplePlugin.java @Intercepts({@Signature( type= Executor.class, method = "update", args = {MappedStatement.class,Object.class})}) public class ExamplePlugin implements Interceptor { public Object intercept(Invocation invocation) throws Throwable { return invocation.proceed(); } public Object plugin(Object target) { return Plugin.wrap(target, this); } public void setProperties(Properties properties) { } } - 在配置文件中声明插件
View Code
2.8 Environments元素
可以配置多个运行环境,但是每个SqlSessionFactory 实例只能选择一个运行环境。
2.8.1 Environments配置示例:
View Code
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
2.8.2 transactionManager事务管理器
MyBatis 有两种事务管理类型(即type=”[JDBC|MANAGED]”):
- JDBC – 这个配置直接简单使用了 JDBC 的提交和回滚设置。 它依赖于从数据源得 到的连接来管理事务范围。
- MANAGED – 这个配置几乎没做什么。它从来不提交或回滚一个连接。而它会让 容器来管理事务的整个生命周期(比如 Spring 或 JEE 应用服务器的上下文) 默认 情况下它会关闭连接。 然而一些容器并不希望这样, 因此如果你需要从连接中停止 它,将 closeConnection 属性设置为 false。例如:
<transactionManager type="MANAGED"> <property name="closeConnection" value="false"/> </transactionManager>
自定义事务管理器:
- 实现TranscactionFactory,它的接口定义如下:
View Code
- 实现TransactionFactory,它的接口定义如下:
public interface Transaction { Connection getConnection(); void commit() throws SQLException; void rollback() throws SQLException; void close() throws SQLException; }
2.8.3 dataSource数据源
dataSource 元素使用标准的JDBC 数据源接口来配置JDBC 连接对象源。
MyBatis 内置了三种数据源类型:
UNPOOLED – 这个数据源的实现是每次被请求时简单打开和关闭连接。它有一点慢, 这是对简单应用程序的一个很好的选择, 因为它不需要及时的可用连接。 不同的数据库对这 个的表现也是不一样的, 所以对某些数据库来说配置数据源并不重要, 这个配置也是闲置的。 UNPOOLED 类型的数据源仅仅用来配置以下 5 种属性:
- driver – 这是 JDBC 驱动的 Java 类的完全限定名(如果你的驱动包含,它也不是 数据源类)。
- url – 这是数据库的 JDBC URL 地址。
- username – 登录数据库的用户名。
- password – 登录数据库的密码。
- defaultTransactionIsolationLevel – 默认的连接事务隔离级别。
作为可选项,你可以传递数据库驱动的属性。要这样做,属性的前缀是以“driver.”开 头的,例如:
- driver.encoding=UTF8
这 样 就 会 传 递 以 值 “ UTF8 ” 来 传 递 属 性 “ encoding ”, 它 是 通 过 DriverManager.getConnection(url,driverProperties)方法传递给数据库驱动。
POOLED – 这是 JDBC 连接对象的数据源连接池的实现,用来避免创建新的连接实例 时必要的初始连接和认证时间。这是一种当前 Web 应用程序用来快速响应请求很流行的方 法。
除了上述(UNPOOLED)的属性之外,还有很多属性可以用来配置 POOLED 数据源:
- poolMaximumActiveConnections – 在任意时间存在的活动(也就是正在使用)连 接的数量。默认值:10
- poolMaximumIdleConnections – 任意时间存在的空闲连接数。
- poolMaximumCheckoutTime – 在被强制返回之前,池中连接被检查的时间。默认 值:20000 毫秒(也就是 20 秒)
- poolTimeToWait – 这是给连接池一个打印日志状态机会的低层次设置,还有重新 尝试获得连接, 这些情况下往往需要很长时间 为了避免连接池没有配置时静默失 败)。默认值:20000 毫秒(也就是 20 秒)
- poolPingQuery – 发送到数据的侦测查询,用来验证连接是否正常工作,并且准备 接受请求。默认是“NO PING QUERY SET” ,这会引起许多数据库驱动连接由一 个错误信息而导致失败。
- poolPingEnabled – 这是开启或禁用侦测查询。如果开启,你必须用一个合法的 SQL 语句(最好是很快速的)设置 poolPingQuery 属性。默认值:false。
- poolPingConnectionsNotUsedFor – 这是用来配置 poolPingQuery 多次时间被用一次。 这可以被设置匹配标准的数据库连接超时时间, 来避免不必要的侦测。 默认值: 0(也就是所有连接每一时刻都被侦测-但仅仅当 poolPingEnabled 为 true 时适用)。
JNDI – 这个数据源的实现是为了使用如 Spring 或应用服务器这类的容器, 容器可以集 中或在外部配置数据源,然后放置一个 JNDI 上下文的引用。这个数据源配置只需要两个属 性:
- initial_context – 这 个 属 性 用 来 从 初 始 上 下 文 中 寻 找 环 境 ( 也 就 是 initialContext.lookup(initial——context) 。这是个可选属性,如果被忽略,那么 data_source 属性将会直接以 initialContext 为背景再次寻找。
- data_source – 这是引用数据源实例位置的上下文的路径。它会以由 initial_context 查询返回的环境为背景来查找,如果 initial_context 没有返回结果时,直接以初始 上下文为环境来查找。
和其他数据源配置相似, 它也可以通过名为 “env.” 的前缀直接向初始上下文发送属性。 比如:
- env.encoding=UTF8
在初始化之后,这就会以值“UTF8”向初始上下文的构造方法传递名为“encoding” 的属性。
2.9 mappers元素
既然 MyBatis 的行为已经由上述元素配置完了,我们现在就要定义 SQL 映射语句了。 但是, 首先我们需要告诉 MyBatis 到哪里去找到这些语句。 Java 在这方面没有提供一个很好 的方法, 所以最佳的方式是告诉 MyBatis 到哪里去找映射文件。 你可以使用相对于类路径的 资源引用,或者字符表示,或 url 引用的完全限定名(包括 file:///URLs) 。例如:
<!-- Using classpath relative resources --> <mappers> <mapper resource="org/mybatis/builder/AuthorMapper.xml"/> <mapper resource="org/mybatis/builder/BlogMapper.xml"/> <mapper resource="org/mybatis/builder/PostMapper.xml"/> </mappers>
<!-- Using url fully qualified paths --> <mappers> <mapper url="file:///var/mappers/AuthorMapper.xml"/> <mapper url="file:///var/mappers/BlogMapper.xml"/> <mapper url="file:///var/mappers/PostMapper.xml"/> </mappers>
<!-- Using mapper interface classes --> <mappers> <mapper class="org.mybatis.builder.AuthorMapper"/> <mapper class="org.mybatis.builder.BlogMapper"/> <mapper class="org.mybatis.builder.PostMapper"/> </mappers>
<!-- Register all interfaces in a package as mappers --> <mappers> <package name="org.mybatis.builder"/> </mappers>
http://www.cnblogs.com/sin90lzc/archive/2012/06/30/2570847.html
废话不多说,直接进入文章。
我们在使用mybatis的时候,会在xml中编写sql语句。
比如这段动态sql代码:
<update id="update" parameterType="org.format.dynamicproxy.mybatis.bean.User">
UPDATE users
<trim prefix="SET" prefixOverrides=",">
<if test="name != null and name != ''">
name = #{name}
</if>
<if test="age != null and age != ''">
, age = #{age}
</if>
<if test="birthday != null and birthday != ''">
, birthday = #{birthday}
</if>
</trim>
where id = ${id}
</update>mybatis底层是如何构造这段sql的?
这方面的知识网上资料不多,于是就写了这么一篇文章。
下面带着这个疑问,我们一步一步分析。
介绍MyBatis中一些关于动态SQL的接口和类
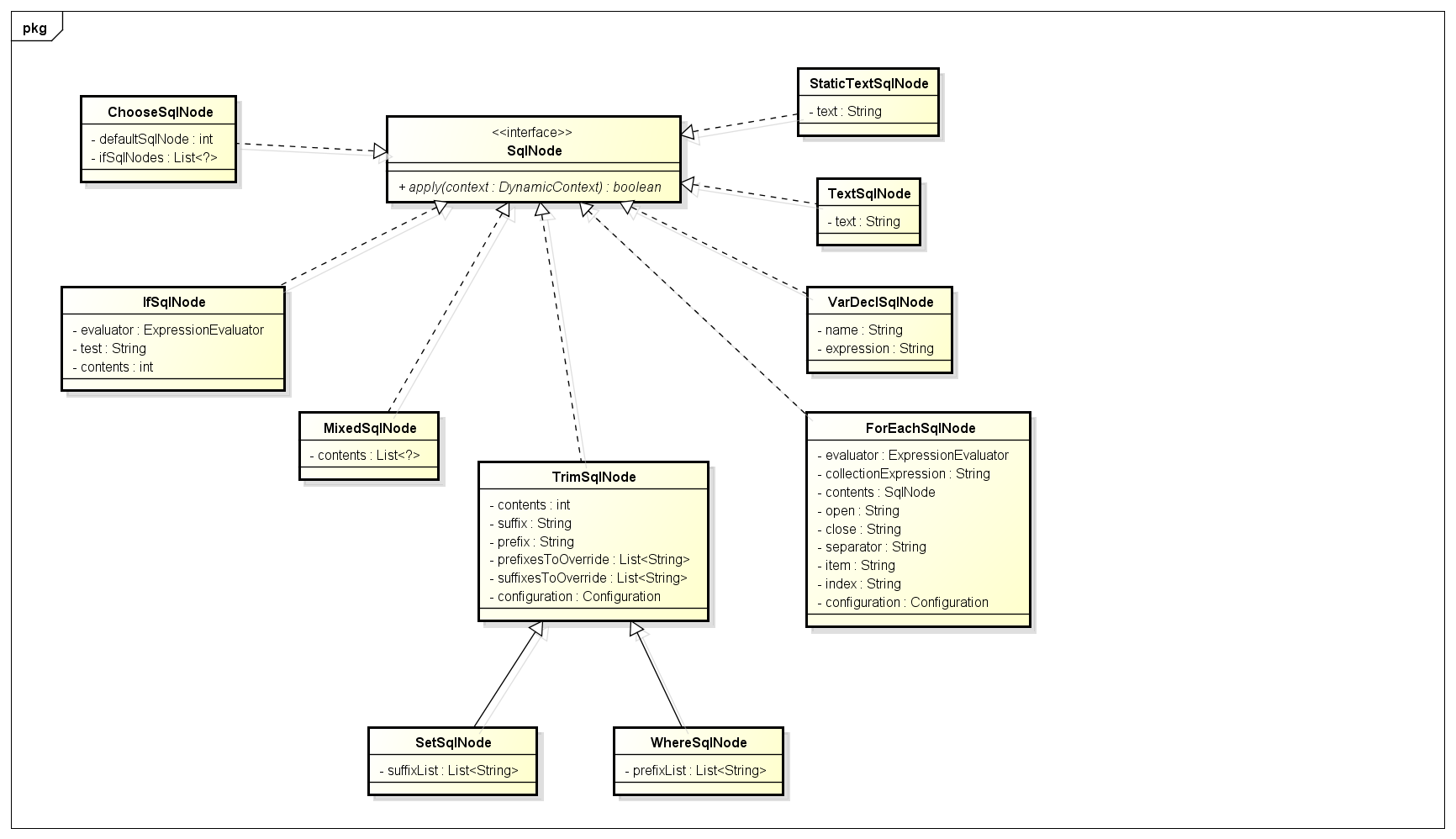
SqlNode接口,简单理解就是xml中的每个标签,比如上述sql的update,trim,if标签:
public interface SqlNode {
boolean apply(DynamicContext context);
}
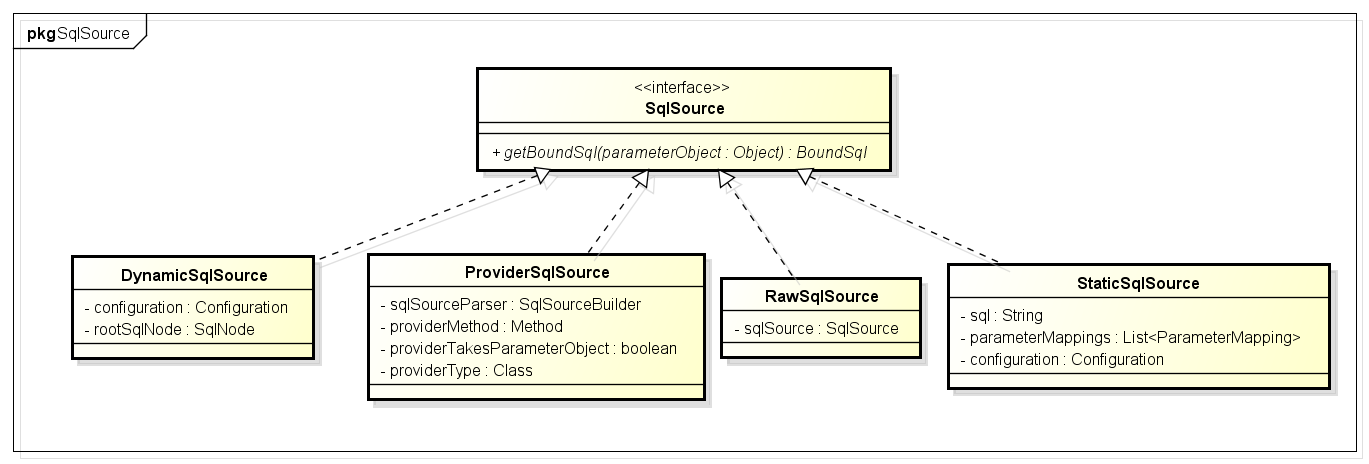
SqlSource Sql源接口,代表从xml文件或注解映射的sql内容,主要就是用于创建BoundSql,有实现类DynamicSqlSource(动态Sql源),StaticSqlSource(静态Sql源)等:
public interface SqlSource {
BoundSql getBoundSql(Object parameterObject);
}
BoundSql类,封装mybatis最终产生sql的类,包括sql语句,参数,参数源数据等参数:

XNode,一个Dom API中的Node接口的扩展类。

BaseBuilder接口及其实现类(属性,方法省略了,大家有兴趣的自己看),这些Builder的作用就是用于构造sql:

下面我们简单分析下其中4个Builder:
1 XMLConfigBuilder
解析mybatis中configLocation属性中的全局xml文件,内部会使用XMLMapperBuilder解析各个xml文件。
2 XMLMapperBuilder
遍历mybatis中mapperLocations属性中的xml文件中每个节点的Builder,比如user.xml,内部会使用XMLStatementBuilder处理xml中的每个节点。
3 XMLStatementBuilder
解析xml文件中各个节点,比如select,insert,update,delete节点,内部会使用XMLScriptBuilder处理节点的sql部分,遍历产生的数据会丢到Configuration的mappedStatements中。
4 XMLScriptBuilder
解析xml中各个节点sql部分的Builder。
LanguageDriver接口及其实现类(属性,方法省略了,大家有兴趣的自己看),该接口主要的作用就是构造sql:
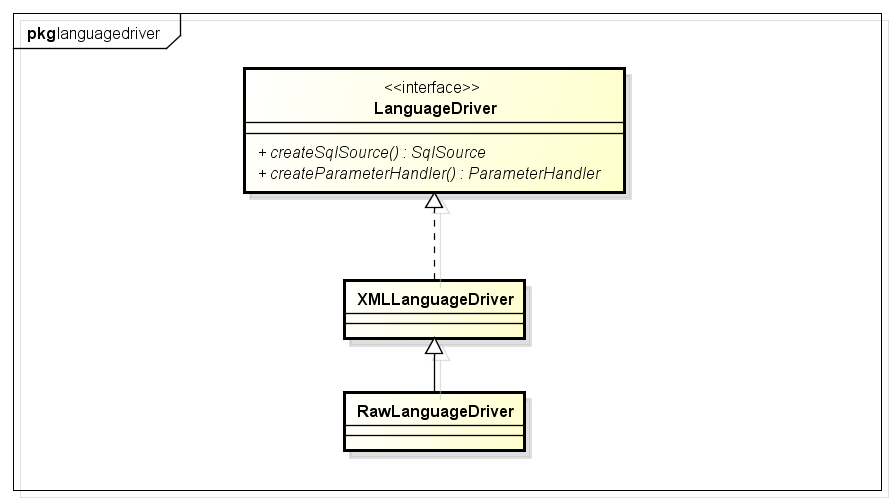
简单分析下XMLLanguageDriver(处理xml中的sql,RawLanguageDriver处理静态sql):
XMLLanguageDriver内部会使用XMLScriptBuilder解析xml中的sql部分。
ok, 大部分比较重要的类我们都已经介绍了,下面源码分析走起。
源码分析走起
Spring与Mybatis整合的时候需要配置SqlSessionFactoryBean,该配置会加入数据源和mybatis xml配置文件路径等信息:
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="configLocation" value="classpath:mybatisConfig.xml"/>
<property name="mapperLocations" value="classpath*:org/format/dao/*.xml"/>
</bean>我们就分析这一段配置背后的细节:
SqlSessionFactoryBean实现了Spring的InitializingBean接口,InitializingBean接口的afterPropertiesSet方法中会调用buildSqlSessionFactory方法
buildSqlSessionFactory方法内部会使用XMLConfigBuilder解析属性configLocation中配置的路径,还会使用XMLMapperBuilder属性解析mapperLocations属性中的各个xml文件。
部分源码如下:
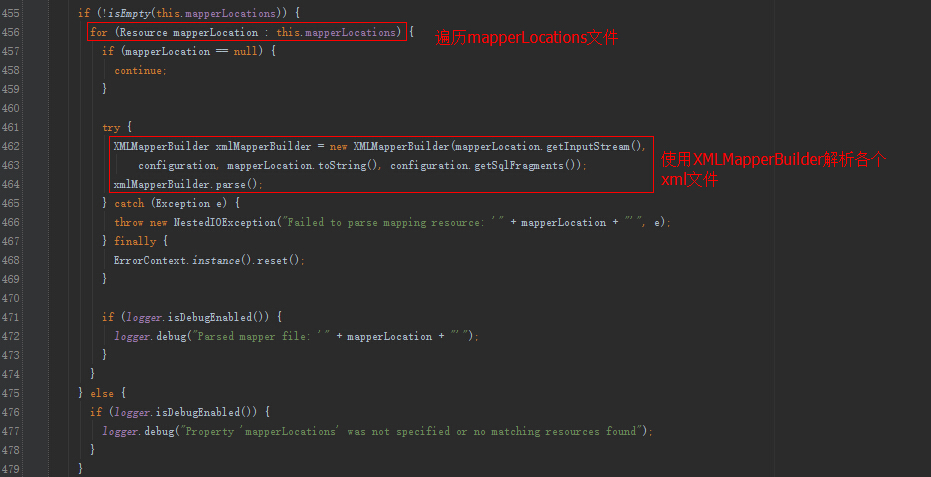
由于XMLConfigBuilder内部也是使用XMLMapperBuilder,我们就看看XMLMapperBuilder的解析细节。
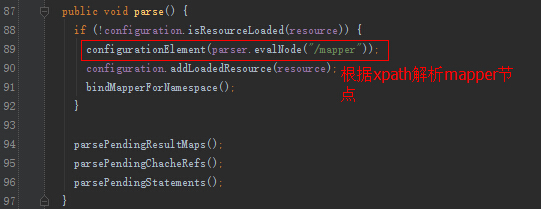
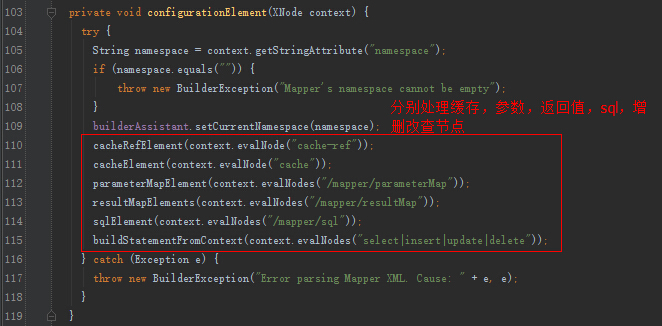
我们关注一下,增删改查节点的解析。
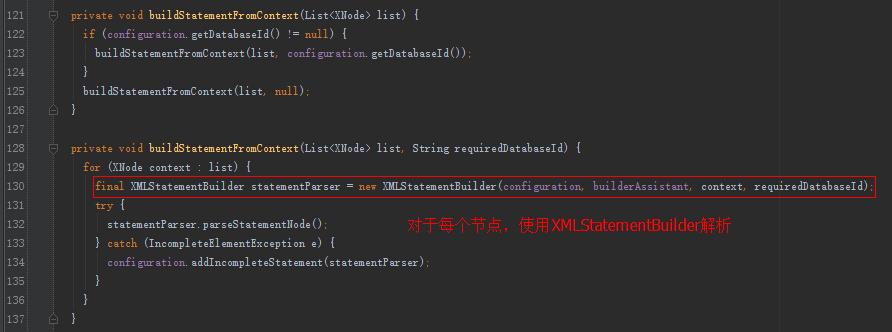
XMLStatementBuilder的解析:

默认会使用XMLLanguageDriver创建SqlSource(Configuration构造函数中设置)。
XMLLanguageDriver创建SqlSource:

XMLScriptBuilder解析sql:

得到SqlSource之后,会放到Configuration中,有了SqlSource,就能拿BoundSql了,BoundSql可以得到最终的sql。
实例分析
我以以下xml的解析大概说下parseDynamicTags的解析过程:
<update id="update" parameterType="org.format.dynamicproxy.mybatis.bean.User">
UPDATE users
<trim prefix="SET" prefixOverrides=",">
<if test="name != null and name != ''">
name = #{name}
</if>
<if test="age != null and age != ''">
, age = #{age}
</if>
<if test="birthday != null and birthday != ''">
, birthday = #{birthday}
</if>
</trim>
where id = ${id}
</update>在看这段解析之前,请先了解dom相关的知识,xml dom知识, dom博文
parseDynamicTags方法的返回值是一个List,也就是一个Sql节点集合。SqlNode本文一开始已经介绍,分析完解析过程之后会说一下各个SqlNode类型的作用。
1 首先根据update节点(Node)得到所有的子节点,分别是3个子节点
(1)文本节点 UPDATE users
(2)trim子节点 ...
(3)文本节点 where id = #{id}
2 遍历各个子节点
(1) 如果节点类型是文本或者CDATA,构造一个TextSqlNode或StaticTextSqlNode
(2) 如果节点类型是元素,说明该update节点是个动态sql,然后会使用NodeHandler处理各个类型的子节点。这里的NodeHandler是XMLScriptBuilder的一个内部接口,其实现类包括TrimHandler、WhereHandler、SetHandler、IfHandler、ChooseHandler等。看类名也就明白了这个Handler的作用,比如我们分析的trim节点,对应的是TrimHandler;if节点,对应的是IfHandler...
这里子节点trim被TrimHandler处理,TrimHandler内部也使用parseDynamicTags方法解析节点
3 遇到子节点是元素的话,重复以上步骤
trim子节点内部有7个子节点,分别是文本节点、if节点、是文本节点、if节点、是文本节点、if节点、文本节点。文本节点跟之前一样处理,if节点使用IfHandler处理
遍历步骤如上所示,下面我们看下几个Handler的实现细节。
IfHandler处理方法也是使用parseDynamicTags方法,然后加上if标签必要的属性。
private class IfHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
String test = nodeToHandle.getStringAttribute("test");
IfSqlNode ifSqlNode = new IfSqlNode(mixedSqlNode, test);
targetContents.add(ifSqlNode);
}
}TrimHandler处理方法也是使用parseDynamicTags方法,然后加上trim标签必要的属性。
private class TrimHandler implements NodeHandler {
public void handleNode(XNode nodeToHandle, List<SqlNode> targetContents) {
List<SqlNode> contents = parseDynamicTags(nodeToHandle);
MixedSqlNode mixedSqlNode = new MixedSqlNode(contents);
String prefix = nodeToHandle.getStringAttribute("prefix");
String prefixOverrides = nodeToHandle.getStringAttribute("prefixOverrides");
String suffix = nodeToHandle.getStringAttribute("suffix");
String suffixOverrides = nodeToHandle.getStringAttribute("suffixOverrides");
TrimSqlNode trim = new TrimSqlNode(configuration, mixedSqlNode, prefix, prefixOverrides, suffix, suffixOverrides);
targetContents.add(trim);
}
}以上update方法最终通过parseDynamicTags方法得到的SqlNode集合如下:
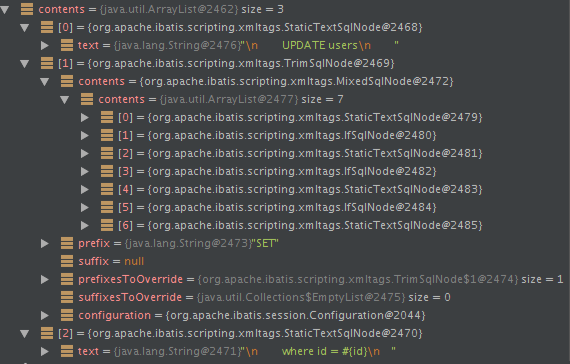
trim节点:
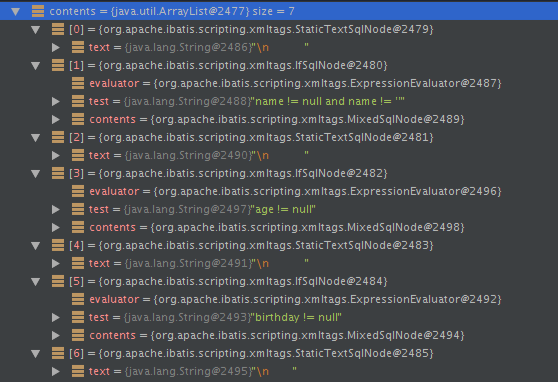
由于这个update方法是个动态节点,因此构造出了DynamicSqlSource。
DynamicSqlSource内部就可以构造sql了:
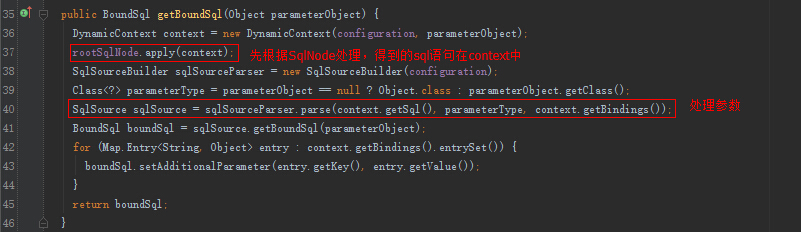
DynamicSqlSource内部的SqlNode属性是一个MixedSqlNode。
然后我们看看各个SqlNode实现类的apply方法
下面分析一下两个SqlNode实现类的apply方法实现:
MixedSqlNode:
public boolean apply(DynamicContext context) {
for (SqlNode sqlNode : contents) {
sqlNode.apply(context);
}
return true;
}MixedSqlNode会遍历调用内部各个sqlNode的apply方法。
StaticTextSqlNode:
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
}直接append sql文本。
IfSqlNode:
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}这里的evaluator是一个ExpressionEvaluator类型的实例,内部使用了OGNL处理表达式逻辑。
TrimSqlNode:
public boolean apply(DynamicContext context) {
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
boolean result = contents.apply(filteredDynamicContext);
filteredDynamicContext.applyAll();
return result;
}
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql) {
if (!prefixApplied) {
prefixApplied = true;
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
if (trimmedUppercaseSql.startsWith(toRemove)) {
sql.delete(0, toRemove.trim().length());
break;
}
}
}
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}TrimSqlNode的apply方法也是调用属性contents(一般都是MixedSqlNode)的apply方法,按照实例也就是7个SqlNode,都是StaticTextSqlNode和IfSqlNode。 最后会使用FilteredDynamicContext过滤掉prefix和suffix。
总结
大致讲解了一下mybatis对动态sql语句的解析过程,其实回过头来看看不算复杂,还算蛮简单的。 之前接触mybaits的时候遇到刚才分析的那一段动态sql的时候总是很费解。
<update id="update" parameterType="org.format.dynamicproxy.mybatis.bean.User">
UPDATE users
<trim prefix="SET" prefixOverrides=",">
<if test="name != null and name != ''">
name = #{name}
</if>
<if test="age != null and age != ''">
, age = #{age}
</if>
<if test="birthday != null and birthday != ''">
, birthday = #{birthday}
</if>
</trim>
where id = ${id}
</update>想搞明白这个trim节点的prefixOverrides到底是什么意思(从字面上理解就是前缀覆盖),而且官方文档上也没这方面知识的说明。我将这段xml改成如下:
<update id="update" parameterType="org.format.dynamicproxy.mybatis.bean.User">
UPDATE users
<trim prefix="SET" prefixOverrides=",">
<if test="name != null and name != ''">
, name = #{name}
</if>
<if test="age != null and age != ''">
, age = #{age}
</if>
<if test="birthday != null and birthday != ''">
, birthday = #{birthday}
</if>
</trim>
where id = ${id}
</update>(第二段第一个if节点多了个逗号) 结果我发现这2段xml解析的结果是一样的,非常迫切地想知道这到底是为什么,然后这也促使了我去看源码的决心。最终还是看下来了。
文章有点长,而且讲的也不是非常直观,希望对有些人有帮助。
http://www.cnblogs.com/fangjian0423/p/mybaits-dynamic-sql-analysis.html