越来越多的人开始意识到,网站即软件,而且是一种新型的软件。
这种"互联网软件"采用客户端/服务器模式,建立在分布式体系上,通过互联网通信,具有高延时(high latency)、高并发等特点。
网站开发,完全可以采用软件开发的模式。但是传统上,软件和网络是两个不同的领域,很少有交集;软件开发主要针对单机环境,网络则主要研究系统之间的通信。互联网的兴起,使得这两个领域开始融合,现在我们必须考虑,如何开发在互联网环境中使用的软件。

RESTful架构,就是目前最流行的一种互联网软件架构。它结构清晰、符合标准、易于理解、扩展方便,所以正得到越来越多网站的采用。
但是,到底什么是RESTful架构,并不是一个容易说清楚的问题。下面,我就谈谈我理解的RESTful架构。
一、起源
REST这个词,是Roy Thomas Fielding在他2000年的博士论文中提出的。

Fielding是一个非常重要的人,他是HTTP协议(1.0版和1.1版)的主要设计者、Apache服务器软件的作者之一、Apache基金会的第一任主席。所以,他的这篇论文一经发表,就引起了关注,并且立即对互联网开发产生了深远的影响。
他这样介绍论文的写作目的:
"本文研究计算机科学两大前沿----软件和网络----的交叉点。长期以来,软件研究主要关注软件设计的分类、设计方法的演化,很少客观地评估不同的设计选择对系统行为的影响。而相反地,网络研究主要关注系统之间通信行为的细节、如何改进特定通信机制的表现,常常忽视了一个事实,那就是改变应用程序的互动风格比改变互动协议,对整体表现有更大的影响。我这篇文章的写作目的,就是想在符合架构原理的前提下,理解和评估以网络为基础的应用软件的架构设计,得到一个功能强、性能好、适宜通信的架构。"
(This dissertation explores a junction on the frontiers of two research disciplines in computer science: software and networking. Software research has long been concerned with the categorization of software designs and the development of design methodologies, but has rarely been able to objectively evaluate the impact of various design choices on system behavior. Networking research, in contrast, is focused on the details of generic communication behavior between systems and improving the performance of particular communication techniques, often ignoring the fact that changing the interaction style of an application can have more impact on performance than the communication protocols used for that interaction. My work is motivated by the desire to understand and evaluate the architectural design of network-based application software through principled use of architectural constraints, thereby obtaining the functional, performance, and social properties desired of an architecture. )
二、名称
Fielding将他对互联网软件的架构原则,定名为REST,即Representational State Transfer的缩写。我对这个词组的翻译是"表现层状态转化"。
如果一个架构符合REST原则,就称它为RESTful架构。
要理解RESTful架构,最好的方法就是去理解Representational State Transfer这个词组到底是什么意思,它的每一个词代表了什么涵义。如果你把这个名称搞懂了,也就不难体会REST是一种什么样的设计。
三、资源(Resources)
REST的名称"表现层状态转化"中,省略了主语。"表现层"其实指的是"资源"(Resources)的"表现层"。
所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实体。你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
所谓"上网",就是与互联网上一系列的"资源"互动,调用它的URI。
四、表现层(Representation)
"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。
比如,文本可以用txt格式表现,也可以用HTML格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的".html"后缀名是不必要的,因为这个后缀名表示格式,属于"表现层"范畴,而URI应该只代表"资源"的位置。它的具体表现形式,应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对"表现层"的描述。
五、状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
客户端用到的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
六、综述
综合上面的解释,我们总结一下什么是RESTful架构:
(1)每一个URI代表一种资源;
(2)客户端和服务器之间,传递这种资源的某种表现层(Representation);
(3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
七、误区
RESTful架构有一些典型的设计误区。
最常见的一种设计错误,就是URI包含动词。因为"资源"表示一种实体,所以应该是名词,URI不应该有动词,动词应该放在HTTP协议中。
举例来说,某个URI是/posts/show/1,其中show是动词,这个URI就设计错了,正确的写法应该是/posts/1,然后用GET方法表示show。
如果某些动作是HTTP动词表示不了的,你就应该把动作做成一种资源。比如网上汇款,从账户1向账户2汇款500元,错误的URI是:
POST /accounts/1/transfer/500/to/2
正确的写法是把动词transfer改成名词transaction,资源不能是动词,但是可以是一种服务:
POST /transaction HTTP/1.1
Host: 127.0.0.1
from=1&to=2&amount=500.00
另一个设计误区,就是在URI中加入版本号:
http://www.example.com/app/1.0/foo
http://www.example.com/app/1.1/foo
http://www.example.com/app/2.0/foo
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URI。版本号可以在HTTP请求头信息的Accept字段中进行区分(参见Versioning REST Services):
Accept: vnd.example-com.foo+json; version=1.0
Accept: vnd.example-com.foo+json; version=1.1
Accept: vnd.example-com.foo+json; version=2.0
http://kb.cnblogs.com/page/114905/

两周前因为公司一次裁人,好几个人的活都被按在了我头上,这其中的一大部分是一系列REST API,撰写者号称基本完成,我测试了一下,发现尽管从功能的角度来说,这些API实现了spec的显式要求,但是从实际使用的角度,欠缺的东西太多(各种各样的隐式需求)。REST API是一个系统的backend和frontend(或者3rd party)打交道的通道,承前启后,有很多很多隐式需求,比如调用接口与RFC保持一致,API的内在和外在的安全性等等,并非提供几个endpoint,返回相应的json数据那么简单。仔细研究了原作者的代码,发现缺失的东西实在太多,每个API基本都在各自为战,与其修补,不如重写(并非是程序员相轻的缘故),于是我花了一整周,重写了所有的API。稍稍总结了些经验,在这篇文章里讲讲如何撰写「合格的」REST API。
RFC一致性
REST API一般用来将某种资源和允许的对资源的操作暴露给外界,使调用者能够以正确的方式操作资源。这里,在输入输出的处理上,要符合HTTP/1.1(不久的将来,要符合HTTP/2.0)的RFC,保证接口的一致性。这里主要讲输入的method/headers和输出的status code。
Methods
HTTP协议提供了很多methods来操作数据:
-
GET: 获取某个资源,GET操作应该是幂等(idempotence)的,且无副作用。
-
POST: 创建一个新的资源。
-
PUT: 替换某个已有的资源。PUT操作虽然有副作用,但其应该是幂等的。
-
PATCH(RFC5789): 修改某个已有的资源。
-
DELETE:删除某个资源。DELETE操作有副作用,但也是幂等的。
幂等在HTTP/1.1中定义如下:
Methods can also have the property of "idempotence" in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request.
简单说来就是一个操作符合幂等性,那么相同的数据和参数下,执行一次或多次产生的效果(副作用)是一样的。
现在大多的REST framwork对HTTP methods都有正确的支持,有些旧的framework可能未必对PATCH有支持,需要注意。如果自己手写REST API,一定要注意区分POST/PUT/PATCH/DELETE的应用场景。
Headers
很多REST API犯的比较大的一个问题是:不怎么理会request headers。对于REST API,有一些HTTP headers很重要:
-
Accept:服务器需要返回什么样的content。如果客户端要求返回"application/xml",而服务器端只能返回"application/json",那么最好返回status code 406 not acceptable(RFC2616),当然,返回application/json也并不违背RFC的定义。一个合格的REST API需要根据Accept头来灵活返回合适的数据。
-
If-Modified-Since/If-None-Match:如果客户端提供某个条件,那么当这条件满足时,才返回数据,否则返回304 not modified。比如客户端已经缓存了某个数据,它只是想看看有没有新的数据时,会用这两个header之一,服务器如果不理不睬,依旧做足全套功课,返回200 ok,那就既不专业,也不高效了。
-
If-Match:在对某个资源做PUT/PATCH/DELETE操作时,服务器应该要求客户端提供If-Match头,只有客户端提供的Etag与服务器对应资源的Etag一致,才进行操作,否则返回412 precondition failed。这个头非常重要,下文详解。
Status Code
很多REST API犯下的另一个错误是:返回数据时不遵循RFC定义的status code,而是一律200 ok + error message。这么做在client + API都是同一公司所为还凑合可用,但一旦把API暴露给第三方,不但贻笑大方,还会留下诸多互操作上的隐患。
以上仅仅是最基本的一些考虑,要做到完全符合RFC,除了参考RFC本身以外,erlang社区的webmachine或者clojure下的liberator都是不错的实现,是目前为数不多的REST API done right的library/framework。

(liberator的decision tree,沿袭了webmachine的思想,请自行google其文档查看大图)
安全性
前面说过,REST API承前启后,是系统暴露给外界的接口,所以,其安全性非常重要。安全并单单不意味着加密解密,而是一致性(integrity),机密性(confidentiality)和可用性(availibility)。
请求数据验证
我们从数据流入REST API的第一步 —— 请求数据的验证 —— 来保证安全性。你可以把请求数据验证看成一个巨大的漏斗,把不必要的访问统统过滤在第一线:
-
Request headers是否合法:如果出现了某些不该有的头,或者某些必须包含的头没有出现或者内容不合法,根据其错误类型一律返回4xx。比如说你的API需要某个特殊的私有头(e.g. X-Request-ID),那么凡是没有这个头的请求一律拒绝。这可以防止各类漫无目的的webot或crawler的请求,节省服务器的开销。
-
Request URI和Request body是否合法:如果请求带有了不该有的数据,或者某些必须包含的数据没有出现或内容不合法,一律返回4xx。比如说,API只允许querystring中含有query,那么"?sort=desc"这样的请求需要直接被拒绝。有不少攻击会在querystring和request body里做文章,最好的对应策略是,过滤所有含有不该出现的数据的请求。
数据完整性验证
REST API往往需要对backend的数据进行修改。修改是个很可怕的操作,我们既要保证正常的服务请求能够正确处理,还需要防止各种潜在的攻击,如replay。数据完整性验证的底线是:保证要修改的数据和服务器里的数据是一致的 —— 这是通过Etag来完成。
Etag可以认为是某个资源的一个唯一的版本号。当客户端请求某个资源时,该资源的Etag一同被返回,而当客户端需要修改该资源时,需要通过"If-Match"头来提供这个Etag。服务器检查客户端提供的Etag是否和服务器同一资源的Etag相同,如果相同,才进行修改,否则返回412 precondition failed。
使用Etag可以防止错误更新。比如A拿到了Resource X的Etag X1,B也拿到了Resource X的Etag X1。B对X做了修改,修改后系统生成的新的Etag是X2。这时A也想更新X,由于A持有旧的Etag,服务器拒绝更新,直至A重新获取了X后才能正常更新。
Etag类似一把锁,是数据完整性的最重要的一道保障。Etag能把绝大多数integrity的问题扼杀在摇篮中,当然,race condition还是存在的:如果B的修改还未进入数据库,而A的修改请求正好通过了Etag的验证时,依然存在一致性问题。这就需要在数据库写入时做一致性写入的前置检查。
访问控制
REST API需要清晰定义哪些操作能够公开访问,哪些操作需要授权访问。一般而言,如果对REST API的安全性要求比较高,那么,所有的API的所有操作均需得到授权。
在HTTP协议之上处理授权有很多方法,如HTTP BASIC Auth,OAuth,HMAC Auth等,其核心思想都是验证某个请求是由一个合法的请求者发起。Basic Auth会把用户的密码暴露在网络之中,并非最安全的解决方案,OAuth的核心部分与HMAC Auth差不多,只不过多了很多与token分发相关的内容。这里我们主要讲讲HMAC Auth的思想。
回到Security的三个属性:一致性,机密性,和可用性。HMAC Auth保证一致性:请求的数据在传输过程中未被修改,因此可以安全地用于验证请求的合法性。
HMAC主要在请求头中使用两个字段:Authorization和Date(或X-Auth-Timestamp)。Authorization字段的内容由":"分隔成两部分,":"前是access-key,":"后是HTTP请求的HMAC值。在API授权的时候一般会为调用者生成access-key和access-secret,前者可以暴露在网络中,后者必须安全保存。当客户端调用API时,用自己的access-secret按照要求对request的headers/body计算HMAC,然后把自己的access-key和HMAC填入Authorization头中。服务器拿到这个头,从数据库(或者缓存)中取出access-key对应的secret,按照相同的方式计算HMAC,如果其与Authorization header中的一致,则请求是合法的,且未被修改过的;否则不合法。
GET /photos/puppy.jpg HTTP/1.1
Host: johnsmith.s3.amazonaws.com
Date: Mon, 26 Mar 2007 19:37:58 +0000
Authorization: AWS AKIAIOSFODNN7EXAMPLE:frJIUN8DYpKDtOLCwo//yllqDzg=
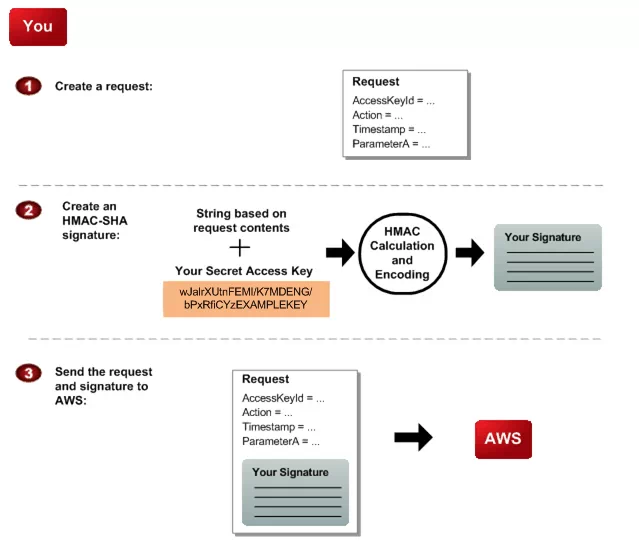
(Amazon HMAC图示)
在做HMAC的时候,request headers中的request method,request URI,Date/X-Auth-Timestamp等header会被计算在HMAC中。将时间戳计算在HMAC中的好处是可以防止replay攻击。客户端和服务器之间的UTC时间正常来说偏差很小,那么,一个请求携带的时间戳,和该请求到达服务器时服务器的时间戳,中间差别太大,超过某个阈值(比如说120s),那么可以认为是replay,服务器主动丢弃该请求。
使用HMAC可以很大程度上防止DOS攻击 —— 无效的请求在验证HMAC阶段就被丢弃,最大程度保护服务器的计算资源。
HTTPS
HMAC Auth尽管在保证请求的一致性上非常安全,可以用于鉴别请求是否由合法的请求者发起,但请求的数据和服务器返回的响应都是明文传输,对某些要求比较高的API来说,安全级别还不够。这时候,需要部署HTTPS。在其之上再加一层屏障。
其他
做到了接口一致性(符合RFC)和安全性,REST API可以算得上是合格了。当然,一个实现良好的REST API还应该有如下功能:
-
rate limiting:访问限制。
-
metrics:服务器应该收集每个请求的访问时间,到达时间,处理时间,latency,便于了解API的性能和客户端的访问分布,以便更好地优化性能和应对突发请求。
-
docs:丰富的接口文档 —— API的调用者需要详尽的文档来正确调用API,可以用swagger来实现。
-
hooks/event propogation:其他系统能够比较方便地与该API集成。比如说添加了某资源后,通过kafka或者rabbitMQ向外界暴露某个消息,相应的subscribers可以进行必要的处理。不过要注意的是,hooks/event propogation可能会破坏REST API的幂等性,需要小心使用。
各个社区里面比较成熟的REST API framework/library:
-
Python: django-rest-framework(django),eve(flask)。各有千秋。可惜python没有好的类似webmachine的实现。
-
Erlang/Elixir: webmachine/ewebmachine。
-
Ruby: webmachine-ruby。
-
Clojure:liberator。
其它语言接触不多,就不介绍了。可以通过访问该语言在github上相应的awesome repo(google awesome XXX,如awesome python),查看REST API相关的部分。
http://kb.cnblogs.com/page/521718/