最近学校让我们选课,每天都有不同的课需要选。。。。然后突发奇想试试用python爬学校选课系统的课程信息
先把自己的浏览器缓存清空,然后在登陆界面按f12 如图:
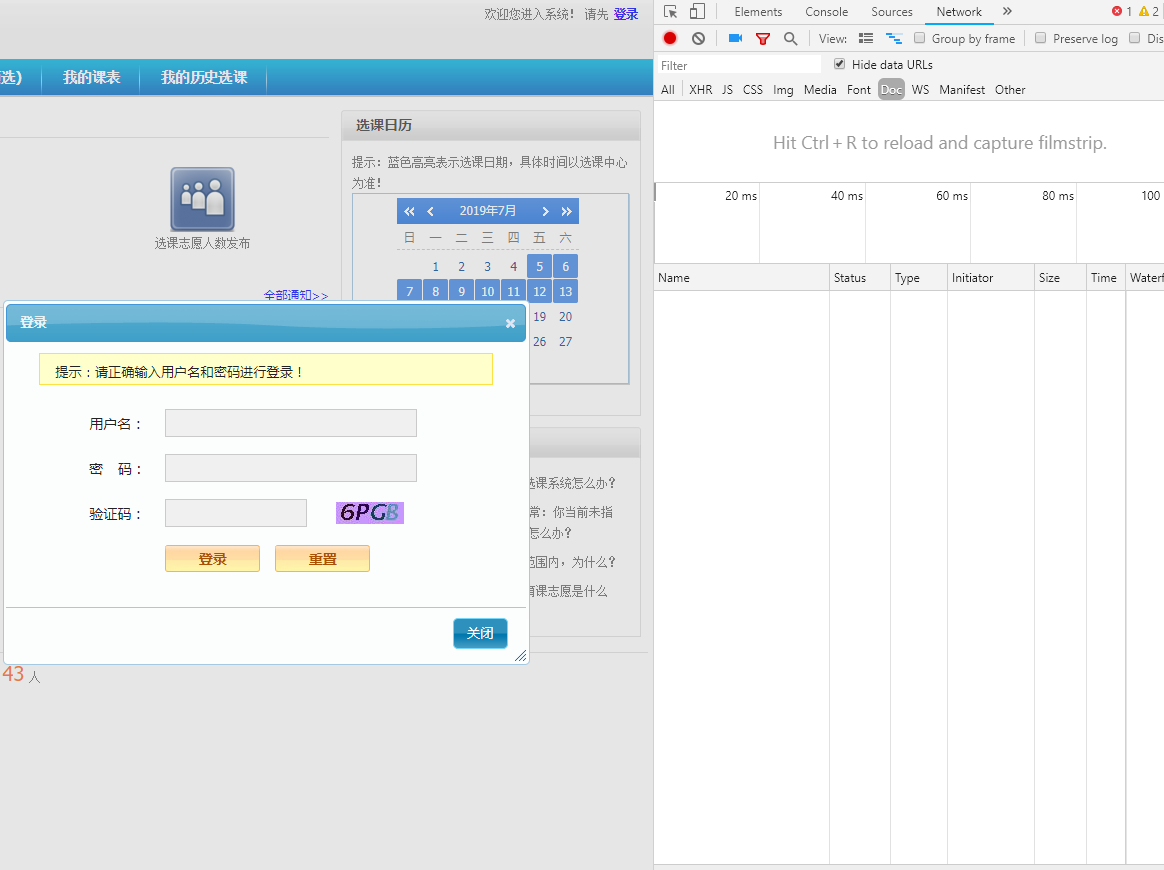
可以看到登陆时候是需要验证码的,验证码图标打算用方法把它存在桌面,手动输入验证码。
或者可以买一个自动输入验证码的平台1快钱可以帮自动识别100到200次验证码,如果这样做
大概过程就是:
1.找到自动输入验证码的平台
2.阅读该平台的API或者手册
3.用编程语言把验证码图片保存到自己电脑后根据平台格式要求打包,通过url发送过去
4.用返回的数字输入到验证码窗口
这次我就简单做一个需要自己手动输入验证码的模拟登陆脚本算了
回到正题
由于我清除了缓存,所以现在相当于第一次登陆,然后我没有登陆而是直接点了f5刷新,浏览器捕捉到的这个请求
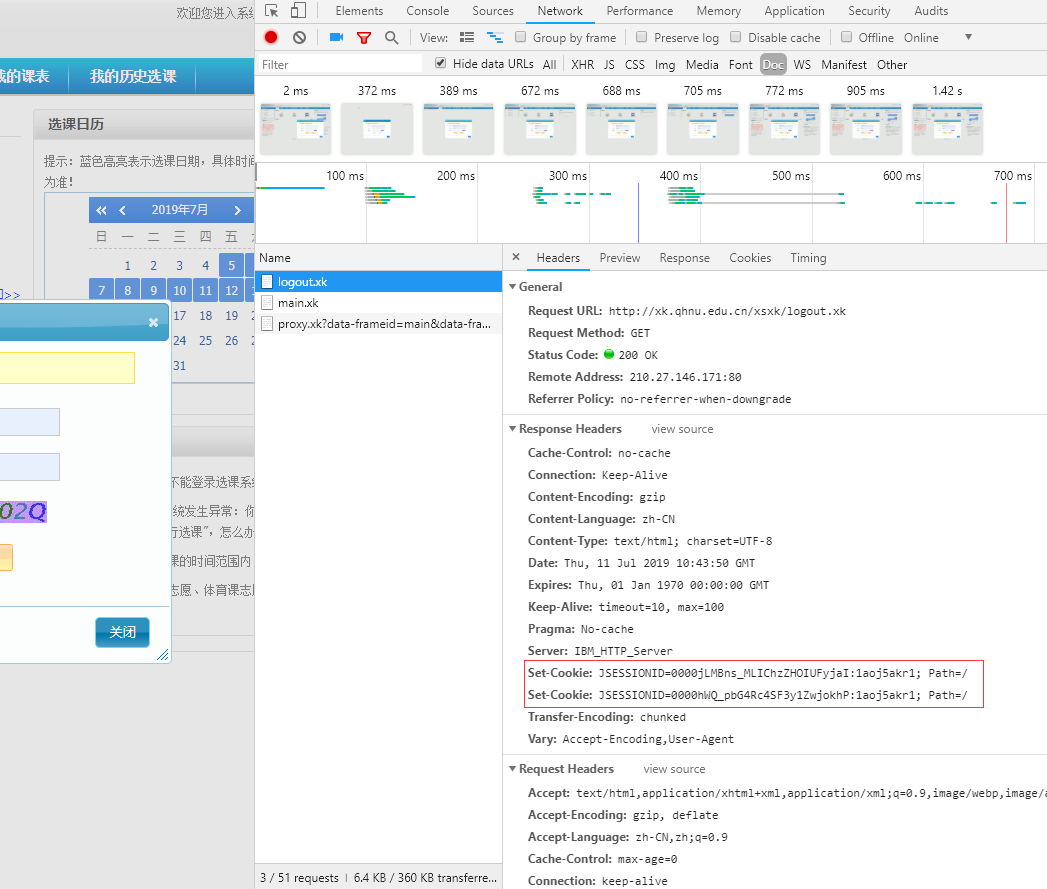
可以看到这个是get请求并且请求头是两个Cookie。
Cookie就是我这台电脑我唯一标识符,当我下次访问这个网页时候它会用这个东西来进一步做一下操作,比如:进一步验证我的身份或者可以利用Cookie无需账号密码直接登陆
这里有两个cookie测试看看需用哪个 下面我再清一次缓存

首先上面有两个cookie下面没 。下面是我这边发送给学校的http请求,当我再刷新一次时候

可以看到 下面箭头 发送给学校的http请求中多了一个cookie而且是最开始的set-cookie中的第二个,接着我再刷新一次
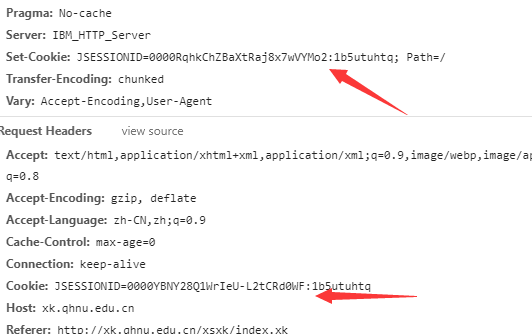
可以看到发给学校的cookie变成了上次的set-cooki。
那么可以看到图中的 http://xk.qhnu.edu.cn/xsxk/logout.xk 这个网址是用于生成和发送cookie码的
那么如果我们不用浏览器登陆改成用代码登陆那么cookie应该是有用的,毕竟是用来标识我这台电脑的。
虽然不知道这个cookie码有没有用 先获取下来再说吧
这里需要用到python的request库
电脑安装好python后(在官网可以下载python并安装)
在配置好环境变量后可以输入win+r键 后输入cmd 调出cmd命令窗口
然后输入 pip install requests 后会自动安装requests库
接下来 我们需要在桌面新建文件并把后缀名改成 .py
源代码如下:
1 import requests 2 3 get_cookie_url='http://xk.qhnu.edu.cn/xsxk/logout.xk' 4 r = requests.get(get_cookie_url) 5 cookie=r.cookies.get_dict() 6 print(cookie)# 输出cookie
这里调用了requests的get方法,因为刚才看图片上的这个网址用的就是get请求
把结果保存在r里,然后用
.cookies.get_dict()得到cookie值
测试结果如下:

可以看到拿到了cookie码
:前面的是cookie ID 后面是cookie的值
登陆
接下来使用抓包工具Wireshark 监听经过这个网页的流量,也可以用刚才的f12看
输入账号密码和验证码后点击登陆 抓取到以下数据
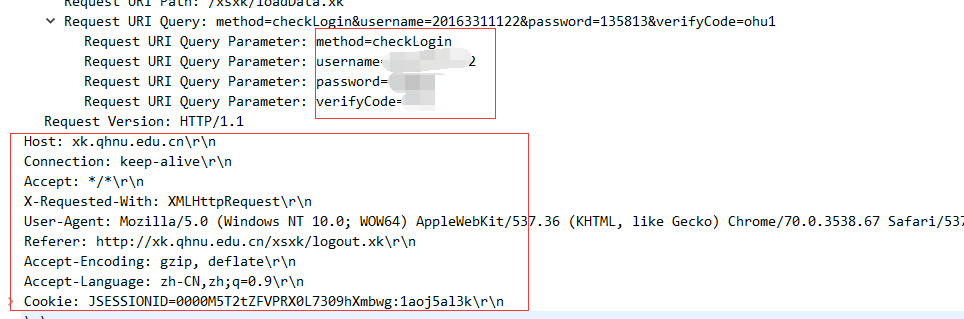
登陆的时候时候给 http://xk.qhnu.edu.cn/xsxk/loadData.xk(没有截图到,可以自己抓包看到) 这个网址发送了数据并且发送头包含cookie等信息
并且发送给这个网页用的方法是get(没有截图到,可以自己抓包看到)
发送的数据变量有
method
username
password
verifcode
那么后面三个就应该是账号密码验证码了
通过上面提供的信息,我们可以伪造一个发给这个网址的请求
代码如下
check_header={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36', 'Host': 'xk.qhnu.edu.cn', } params={ 'method':'checkLogin', 'username':自己的学号, 'password':自己的账号, } check_url='http://xk.qhnu.edu.cn/xsxk/loadData.xk' r = requests.get(check_url,params=params,cookies=cookie) #cookie由之前的代码获得
但是可以看到我们缺少了一个verifcode变量用来存放所输入的正确验证码值,因为我还要想办法把验证码的图片保存到桌面,方便看到。
这里我用谷歌浏览器f12的定位功能定位到验证码图片,并且显示了相对应的html代码

从图中可以看到 这个验证码是由src中的网址生成的,而且d=后面是一串数字,当我再刷新时候这串数字也发生变化
看这串数字不难发现它是一串格林尼治时间,也就是说我们要获得验证码就需要访问src中的网页,并且这个网址需要传递
一串数字,这串数字是格林尼治时间。我猜是为了做随机生成的吧
那么我们用get方法来访问这个网址并且将访问的数据保存到桌面
代码:
1 import time 2 3 jpg_url = 'http://xk.qhnu.edu.cn/xsxk/servlet/ImageServlet?d='+str(int(time.time())*1000) 4 5 content = requests.get(jpg_url,cookies=cookie).content 6 with open('demo.jpg', 'wb') as fp: 7 fp.write(content)
运行后桌面生成了验证码的图片

在获取这个验证码之前我用抓包工具看了一下 往这个地址发送的数据中又包括了cookie,所以我加上cookie了
在不加cookie的话 就算获取到了验证码图片 在进行模拟登陆时候根据桌面上的图登陆总是验证码错误
在折腾了一段时间后发现验证码的生成会和我的cookie相关联,也就是说,验证码的生成不仅用到格林尼治时间还用到我的cooki
并将验证码与我的cookie绑定,一一对应
然后通过
while(True): code = input('请输入验证码:') datacode= str(code) params['verifyCode']=datacode r = requests.get(check_url,params=params,cookies=cookie) if re.search('true',r.text): print ('验证码正确......') break else: print ('验证码错误,请重新输入......') date['verifyCode']=datacode
将验证码加入到前面的date中,发送给/xsxk/loadData.xk,在发送成功后查看返回信息发现验会有true字符串或者false,那么我就可以利用这个来验证我是不是正确
这样用到的re库 需要导入
回到刚才的登陆
继续看抓包的数据,发现了post方法,一般来说post方法是真正的登陆窗口

post方法前面的 get /xsxk/loadDate...... 就是我们前面实现的get,现应该实现post真正的登陆了
在查看post发送的数据中包含了头信息,其中包括cookie 和账号密码所以我们用requests的post方法继续伪造请求
在post结束后学校服务器会返回一个302 found的http状态码 这表示浏览器将我的数据发送后,会重新跳转到另外一个网页
不过requests是可以自动跳转的,不需要担心
代码
log_header={ 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Origin':'http://xk.qhnu.edu.cn',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36',
'Referer':'http://xk.qhnu.edu.cn/xsxk/logout.xk',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
'Host': 'xk.qhnu.edu.cn',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1'
}
date={
'username':自己的学号,
'password':自己的密码,
}
log_url='http://xk.qhnu.edu.cn/xsxk/login.xk'
r=requests.post(log_url,data=date,headers=log_header,cookies=cookie)
#传递的参数cooki由之前的代码获得
其中的 date和log_header都是通过抓包看到的 这个网页需要哪些数据。
代码写好后 运行并且抓包发现 与用网页登陆抓取的包大致相同,通过多次修改可以总结如下
通过用网页登陆抓包发现登陆学校的网址有一下步骤
1.在清空缓存,刷新时(即第一次登陆时),会先向xsxk/logout.xk发送cookie
2.在get验证码的所需要的数据中 通过抓包发现需要用到第一步的cookie
3.在登陆前需要向xsxk/loadData.xk发送自己的账号密码和验证码和cookie
4.登陆时用的是post方法,并且还需要将自己的账号密码和之前的验证码和cookie发送一次 如果没有完成第三步那么无论怎么登陆都失败
完整代码如下
import time import requests import re from bs4 import BeautifulSoup #获取解析网页的库 username=input("账号") password=input("密码") get_cookie_url='http://xk.qhnu.edu.cn/xsxk/logout.xk' jpg_url = 'http://xk.qhnu.edu.cn/xsxk/servlet/ImageServlet?d='+str(int(time.time())*1000) check_url='http://xk.qhnu.edu.cn/xsxk/loadData.xk' log_url='http://xk.qhnu.edu.cn/xsxk/login.xk' get_cookie_header={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36' } check_header={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36', 'Host': 'xk.qhnu.edu.cn', } params={ 'method':'checkLogin', 'username':username, 'password':password, } log_header={ 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'Origin':'http://xk.qhnu.edu.cn', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36', 'Referer':'http://xk.qhnu.edu.cn/xsxk/logout.xk', 'Accept-Encoding':'gzip, deflate', 'Accept-Language':'zh-CN,zh;q=0.9', 'Host': 'xk.qhnu.edu.cn', 'Cache-Control': 'max-age=0', 'Upgrade-Insecure-Requests': '1' } date={ 'username':username, 'password':password, } r = requests.get(get_cookie_url) cookie=r.cookies.get_dict() #print(cookie) 输出cookie content = requests.get(jpg_url,cookies=cookie).content with open('demo.jpg', 'wb') as fp: fp.write(content) while(True): code = input('请输入验证码:') datacode= str(code) params['verifyCode']=datacode r = requests.get(check_url,params=params,cookies=cookie) if re.search('true',r.text): print ('验证码正确......') break else: print ('验证码错误,请重新输入......') date['verifyCode']=datacode r=requests.post(log_url,data=date,headers=log_header,cookies=cookie) #print(r.text)获得网址的源代码 html=BeautifulSoup(r.text,'lxml') tagList=html.find('b') print('#############################################################') print('进入选课系统成功:') print(tagList.get_text()) print('#############################################################')
在这里用了另外一个库 用于解析所获取的登陆后网页源代码
总的来说就是 先用浏览器和抓包工具,浏览器多次登陆,用抓包工具和浏览器的f12查看登陆前经历了哪些步骤,哪些网页,每个网页分别发送了哪些数据,用的是get方法还是post方法
在知道后,用代码将所需要的数据写出来并保存后用requests库的get方法post方法模拟发送数据给学校服务器。最后获得登陆后的网页源代码
不过。。。我在获得源代码后发现html中的iframe标签显示的是选课的内容,但是我用于分析网页代码的库是BeautifulSoup
它不支持分析iframe内容。。。白忙活了那么久。
通过在网上查找信息发现selenium这个库支持分析iframe标签的内容
所以接下来就去学习用这个库去获取学习的选课信息并且自动选课
下次就放用selenium做爬虫的过程