转载
GAN阶段性小结(损失函数、收敛性分析、训练技巧、应用“高分辨率、domain2domain”、研究方向)
对于GAN的研究已经有了一段时间,有以下感觉:
1.感觉赶了一个晚班车,新思路很难找到了,再往下研究就需要很深入了
2.在图像领域已经有了大量的工作,效果很不错;而在自然语言领域,目前来说效果并不显著(当然目前CV本来发展就领先于NLP)
3.接下来会结合实验室的优势,在与强化学习的结合、对话生成、VQA上做进一步研究
4.我会对GAN领域的各个方面逐步写总结,做一个类似tutorial的文档,帮助大家快速了解GAN,感觉它已经是一个基本的组件一样,不用那么高大上
以前看论文总是在PDF上草草总结,时间一久基本就都忘了,只能记个大概,这是做研究的大忌,也是老师经常强调的一点,接下来我们定期把看过的论文总结发布在知乎专栏,用来督促自己
总结的时候,我会把别人的总结精简,再加上我自己的理解,这样站在巨人的肩膀上速度会快一些,分析也会更加深入一些,同时该有的引用和参考我都把原作者的链接放在下面
希望可以交流分享,督促自己,方便别人
GAN相对RBMs、DBMs、DBMs、VAE的优势
RBMs, DBNs and DBMs all have the difficulties of intractable partition functions or intractable posterior distributions, which thus use the approximation methods to learn the models.
Variational Autoencoders (VAE), a directed model, which can be trained with gradient-based optimization methods. But VAEs are trained by maximizing the variational lower bound, which may lead to the blurry problem of generated images.
GAN为何备受关注
第一,从理论上来讲,生成模型是用来逼近真实数据分布,传统的生成模型如贝叶斯模型、变分自动编码器等,但在过去十多年,这些技术还是没办法逼近真实的、维度很高的数据分布,图像生成仍是一个很难的任务,一直到 GAN 的出现。
第二个影响就是让研究人员在研究 AI 时有了更新的思路,“它教育了我们这一批研究者,是不是在一系列深度学习算法的设计中考虑引入对抗式思想、怎么引入、又该如何适当的引入,进而提高传统 AI 算法执行任务的表现。”
第三个就是可以基于少量数据进行半监督的学习。大家都知道要训练神经网络需要庞大的数据量,GAN 提供了一个新的思路—训练GAN 来模拟真实数据分布。在有些情况下,研究人员会遇到真实数据不够,或是难以取得数据的情况,此时可以试图训练 GAN 来模拟真实数据分布,如果模拟得够好,GAN 就可以生成更多的训练数据,这有助于解决深度学习小数据量的难题
GAN的应用
一是完全从无到有的生成:输入随机产生的噪声变量,输出人、动物等各种图像,这类应用难度较高;另一个则是利用 GAN 来改进已有或传统的 AI 应用,例如超分辨率、照片自动美化、机器翻译等,难度相对较低,效果也很实用。
参考:
GAN在2017年实现四大突破,未来可能对计算机图形学产生冲击mp.weixin.qq.com
1.GAN的损失函数(或称目标函数)
[1] Generative adversarial network. NIPS 2014
[2] f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization. NIPS 2016
[3] Least Squares Generative Adversarial Networks. ICCV 2017
[4] Towards Principled Methods for Training Generative Adversarial Networks. ICLR 2017
[5] Improved Training of Wasserstein GANs. NIPS 2017
[6] Energy-based Generative Adversarial Network. ICLR 2017
[7] MAGAN: Margin Adaptation for Generative Adversarial Networks. Arxiv 2017
[8] Loss-Sensitive Generative Adversarial Networks on Lipschitz Densities. Arxiv 2017
[9] BEGAN: Boundary Equilibrium Generative Adversarial Networks. Arxiv 2017
GAN:
由定义的判别器loss可得到最优判别器,而在最优判别器下,生成器loss可等价变化为最小化真实分布Pr和生成分布Pg之间的JS散度。当我们越训练判别器的时候,它就越接近最优,最小化生成器loss就越接近于最小化两个分布之间的JS散度。GAN就是通过这种方式使生成器生成的样本更加接近真实样本,无论在真实性上还是多样性上。
JS散度存在一个问题:当两个分布有所重叠且重叠不可忽略时,两个分布越接近,它们之间的JS散度越小。当它们之间完全没有重叠部分或者重叠部分可以忽略不计的时候,它们的JS散度是一个固定常数log2。而两个分布都是高维数据,不重叠或者重叠部分可以忽略不计的可能性很大,这就导致无论它们相距多远,JS散度都是常数log2,最终导致生成器的梯度近似为0,梯度消失。【注:此处需要一些测度论、拓扑学知识】
这就说明判别器训练的太好,准确地说一开始训练的太好会导致梯度为0问题, Ian goodfellow之后提出一个新的损失函数公式:Ex~Pg[-logD(x)],为得是避免判别器一开始就训练地太好导致生成器的更新梯度为0,但是通过分析,在最优判别器下,生成器loss是KL(Pg||Pr)-2JS(Pr||Pg),由此带来两个问题:一是两个散度一个要拉近分布,一个要拉远分布,导致梯度很不稳定;二是KL散度不对称,KL(Pg||Pr)和KL(Pr||Pg)重视的损失不一致,前者更加重视准确性轻视多样性,后者更加重视多样性而轻视准确性,这就说明KL散度本身对多样性和准确性惩罚不平衡,前一种KL散度会导致mode collapse问题。
参考:
郑华滨:令人拍案叫绝的Wasserstein GANzhuanlan.zhihu.com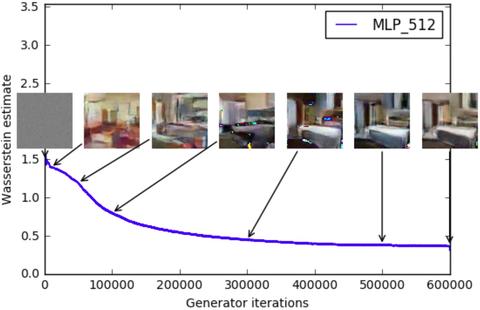
f-GAN:
证明生成对抗网络是变分散度估计方法(variational divergence estimation)的一种特例,任何f-divergence都可以用来训练基于神经网络的生成模型。分析了各种散度在训练复杂度和生成样本质量的情况。
参考:
深度学习笔记十:生成对抗网络再思考f-GAN - CSDN博客blog.csdn.net

LS-GAN(least square GAN):
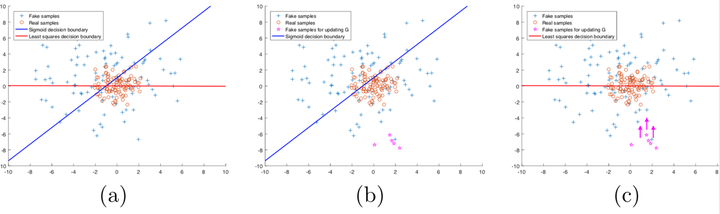
The relation between LSGANs and f-divergence:在最优判别器下,生成器loss的优化相当于最小化Pd + Pg和2Pg的the Pearson X2 divergence(if a, b, and c satisfy the condtions of b - c = 1 and b - a = 2.此处a、b、c是生成器loss公式中的常量)。
本文认为普通GAN使用sigmoid cross entropy loss function作为判别器loss,得到的决策边界会使一些生成样本处于决策边界positive side,而这些生成样本其实仍旧离真实样本存在比较远的距离,所以用这些被判别器判别为真实样本的生成样本更新生成器会产生梯度弥散。本文通过引入the least square loss function,可以移动生成样本到决策边界,因为the least square loss function会惩罚那些处于决策边界positive side且距离决策边界很远的生成样本,即使是正确分类到negative side,但是如果距离决策边界远,仍旧会往被决策边界拉。主要贡献:通过引入the least square loss function来减弱梯度弥散,但是并未解决mode collapse问题。
Towards Principled Methods for Training Generative Adversarial Networks:
解释了以下四个问题(是WGAN、WGAN-GP的前作):
- Why do updates get worse as the discriminator gets better? Both in the original and the new cost function.
- Why is GAN training massively unstable?
- Is the new cost function following a similar divergence to the JSD? If so, what are its properties?
- Is there a way to avoid some of these issues?
WGAN-GP:
Wasserstein距离又叫Earth-Mover(EM)距离,相对于KL散度、JS散度的优越性在于,即使两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL散度和JS散度既反映不了远近,也提供不了梯度,但是Wasserstein距离却可以提供有意义的梯度。
根据Wasserstein距离推导出来的公式如下:
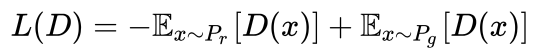
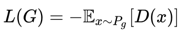
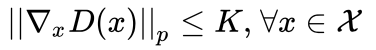
通过gradient penalty来实现对判别器进行Lipschitz限制(体现为在整个样本空间上,要求判别器函数D(x)梯度的Lp- Norm不大于一个有限的常数K,但是整个样本空间上采样,由于所谓的维度灾难问题,如果要通过采样的方式在图片或自然语言这样的高维样本空间中估计期望值,所需样本量是指数级的,实际上没法做到。论文作者提出,其实没必要在整个样本空间上施加Lipschitz限制,只要重点抓住生成样本集中区域、真实样本集中区域以及夹在它们中间的区域就行了),得到如下公式(简单取K为1):
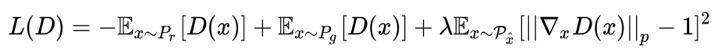
解决的问题:
- 极大的“在数值上”减弱了梯度消失的问题,而且其损失函数的值可以用来指示训练过程(此处我说“在数值上”是因为在考虑是否可以做“探索梯度组成和意义的研究,进而想到新的梯度来源和更精细、更准确的梯度更新机制,比如哪层更新哪层”);
- 虽然在同样的架构下WGAN-GP与DCGAN生成的图片效果差不多,但是WGAN-GP更具健壮性,别的距离产生的损失函数针对不同的数据集需要精心设计架构、使用技巧和G-D训练比例,否则会崩溃,但是WGAN-GP基本上都可以训练好,这个也是WGAN-GP在工程实现上更加流行的原因,相比于其他论文结果复现能力和泛化能力更加强大;
- 至于mode collapse,论文中作者仅仅提及根据实验结果应该是解决了
注意:
- 判别器最后一层去掉sigmoid函数。因为原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN-GP中的判别器做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。
- 判别器的模型架构中不能使用Batch Normalization,由于我们是对每个样本独立地施加梯度惩罚,Batch Normalization会引入同个batch中不同样本的相互依赖关系。如果需要的话,可以选择其他normalization方法,如Layer Normalization、Weight Normalization和Instance Normalization,这些方法就不会引入样本之间的依赖。论文推荐的是Layer Normalization。
参考:
生成式对抗网络GAN有哪些最新的发展,可以实际应用到哪些场景中?www.zhihu.com
Energy-based GAN:
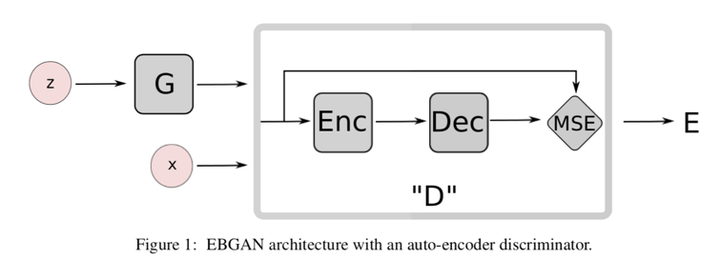
Energy-based GAN将Discriminator视作一个energy function(negative evaluation function),即这个函数值越小代表data越真实。利用自编码器AE作为discriminator(energy function)。
EBGAN的generator与其他gan网络都一样,不同的是其discriminator是一个AE。EBGAN将discriminator的输入输出求一个rescontruction error,那这个error就是discriminator的输出,也即所说的energy。我们希望对于真实data的重建误差小,即energy小,即discriminator的输出小,而同时希望由generaor生成的图片的energy小。这与之前的gan的判别器希望真图输出大,假图大正好相反。
损失函数公式如下:
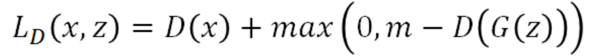
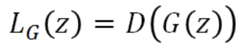
D的损失函数要最大化D(G(z)), 也就是要抬高下图中的蓝色点对应的曲线,但是如果没有margin的约束,可以无限制的抬高,所以我们需要一个m,即margin,就是当抬高到m这个距离后就没有惩罚了,所以此时loss就将不再忙着抬高,而是去将real对应的曲线也即D(x)拉小。generator做的事情就很好理解了,因为real对应的energy是小的,所以希望生成的图片的energy也是小的。
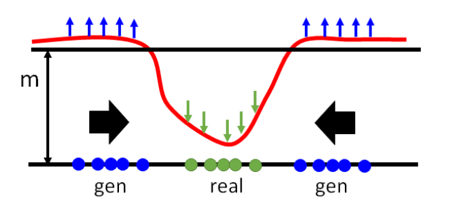
Pulling-away(用于训练生成器,希望它可以生成多样性的样本)。具体来说对于一个batch中的样本xi和xj,我们将其带入discriminator的编码器得到编码后的结果ei和ej,然后比较其余弦相似度,希望这个相似性越小越好。
解决的问题:
- 从能量函数角度对GAN做了解释,文章指出如此解释,基于能量函数的理论和技巧就可以引入过来,但是就实验结果来看生成的图片质量相对于DCGAN并没有提升,尤其指出可生成高清图片,但是高清图片内容不具辨识性
- 提出了度量样本多样性的指标,进而促进生成器生成的样本更具多样性,解决mode collapse问题
MAGAN:
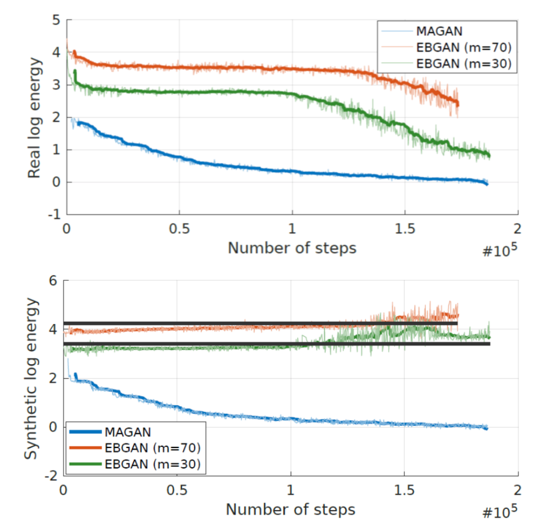
红、绿线分别表示EBGAN中m取值为70和30的情况。横轴为迭代次数,纵轴为energy取对数。上面图为真实图片energy,下面图为生成图片energy。生成图中上下两条黑线分别为m=log70和m=log30结果。Discriminator希望生成图的energy高,而从生成图看出EBGAN确实做到了这件事,使得生成图的energy在黑线的上下游走。然后观察真实图在前面几个epoch中energy并没有下降太多。
从能量函数角度解释,参照energy-based GAN,使m变为一个浮动的值,作用:随着m的逐步减小,无论真实图片还是生成图片的能量函数值都在减小。
LSGAN:
同样从能量函数角度解释,希望真实图片能力小,生成图片能量大,如下图所示,当真实图片和生成图片差异大的时候(可以用hidden layer来量相似度),就需要训练判别器使生成图片的能量大,当真实图片和生成图片差异小的时候,判别器输出生成图片的能量就需要小一些。
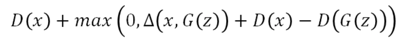
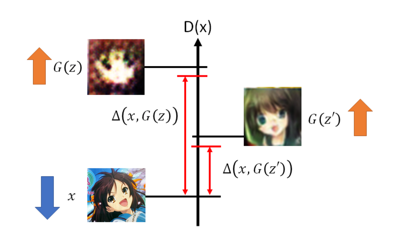
BE-GAN:
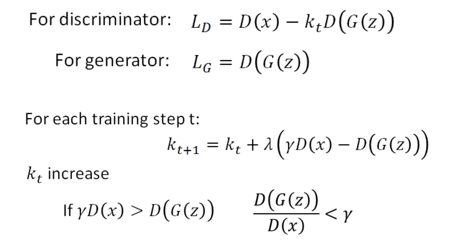
最开始Kt 为0,模型只想把真图的energy下降,那什么时候想把生成图的energy拉高呢?即当
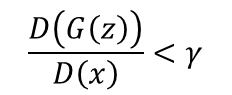
的时候,γ是一个超参数。就是说当生成图的energy / 真实图的energy 小于γ时,Discriminator才想要将生成图的energy变大。所以不会一直考虑生成图的reconstruction error,而是当生成图的reconstruction error太小的时候,discriminator才考虑将生成图的reconstruction error变大。γ调整如下:

参考:
Hung-yi Lee2.收敛的理论分析及训练技巧
[10] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. DCGAN
[11] Improved Techniques for Training GANs. NIPS 2016
[12] Unrolled Generative Adversarial Networks. ICLR 2017
[13] Mode Regularized Generative Adversarial Networks. ICLR 2017
[14] Generalization and Equilibrium in Generative Adversarial Nets (GANs). ICML 2017
[15] Gradient descent GAN optimization is locally stable. NIPS 2017
[16] Approximation and Convergence Properties of Generative Adversarial Learning. NIPS 2017
[17] Stabilizing Training of Generative Adversarial Networks through Regularization. NIPS 2017
[18] Spectral Normalization for Generative Adversarial Networks. ICLR 2018
DCGAN:
对判别器和生成器的激活函数、架构进行大量实验,最终找到一组效果好、训练稳定的设置来提升训练效果,但是实际上是治标不治本,没有彻底解决问题。如添加batchnorm、修改生成器和判别器的激活函数等
Improved Techniques for training GANs:
Feature matching:利用中间层feature map增加了一个新的损失函数,加速了平衡的收敛
minibatch discrimination:解决mode collapse问题
historical averaging:使参数更新时候不会忘了之前由其他样本得出的经验
one-sided label smoothing:reduce the vulnerability of neural networks to adversarial examples
virtual batch normalization:batch normalization的缺陷是造成神经网络对于输入样本的输出值极大依赖于在同一个batch中的其他样本,该技巧选择了固定的batch生成statistics来normalize输入样本
Unrolled GAN:
这篇论文做的更加理论一点,它们提出了一种新的 loss。这种 loss 并不是通过改变模型 architecture 来引入的,也不是一种新的 metric,而是一种 gradient-based loss。如果说我们过去做 gradient descent training 时候,是让 gradient 进行改变,让其他模型参数保持不变的话;那么他们提出的这种 loss,被叫做 surrogate loss,则是要能基于一阶 gradient 改变后的其他模型参数的变化再去改变二阶甚至高阶 gradient——从而是一种 gradient dynamics 信息。这件事其实并不是很常见,因为在我们大部分神经网络和机器学习的训练中,我们都只会用到一阶导数信息。然而,二阶或者高阶导数的出发点其实是我们真正的不 approximate 的求解就应该是不断的 unroll 出 gradient 的或者是 exact solution 的。而这件事就是非常难算的。所以可以认为,这篇论文提出的这种 loss 是一种中间态,tradeoff。所以这篇论文我认为最重要的贡献就是,它指出了也强调了高阶信息在神经网络或者在机器学习中的重要性(主要是神经网络)。顺着这个思路思考下去,应该也能为其他模型和其他任务带来一些新的解决方法。
Mode regularized GAN:
主要贡献是提出了两种 regularizers 去提高训练稳定性和解决 missing modes。这两种 regularizers 可以很方便地用在任何 GAN 网络中(不比如 DCGAN,或者 Goodfellow 原版的 MLP GAN)。
第一个 regularizer 是:与其让生成网络 G 直接从 noise vector z 映射到样本空间,我们可以让 z 从一个样本空间先映射过来,也就是有一个 z = encoder(X) 的过程,从而再,G(encoder(X))。这样的好处是,reconstruction 过程会增加额外的学习信息,使得生成网络生成出来的 fake data(generated sample)不再那样容易被判别网络 D 一下子识别出来。这样 D 和 G 就都能一直有 loss/gradient 去将训练过程较为稳定地进行下去,从而达到了让 GAN 训练更加稳定的效果。另一方面,因为 encoder(X) 保证了 X 和映射后的 X 的空间的对应性,也就可以保证了生成网络能覆盖所有样本空间的样本 modes,也就理论上保证了 missing modes 问题的减少。
第二个 regularizer 是在此基础上,我们提出了一种 manifold-diffusion GAN(MDGAN),它将 reconstruction loss 提取成单独的一步去训练——第一步 manifold step 就是去做 G(Enc(X)) 和 X 的训练,减少这两者之间的差别;第二步 diffusion 就是让 G(Enc(X)) 再和 G(z) 做拉近。这样从模型训练的过程,形象的理解就是,先把两个分布的 “形状” 调整好,再把两个分布的距离拉近。
为了能评价我们的 regularizers 的效果,我们在 inception score 的基础上提出了一种 MODE score。我们发现,Inception score 有一种很不好的现象是,即使 GAN 的网络训练塌了(即会产生完全是噪音,肉眼根本不 perceptual 的图片),inception score 的分数也会很高(很高应该代表的是图片非常像真实样本)。这是不 make sense 的。而我们提出的 MODE score,将塌了的情况用一种额外的 metric 衡量进来——从而使得最终的 MODE score 是基于样本质量和样本 mode(塌了的话,mode 就非常差),两个角度。
以上两篇参考:
ICLR 2017 有什么值得关注的亮点?
3.GAN图像领域的应用(构建适应应用的神经网络结构)
3.1 图像超分辨率
[19] Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. NIPS 2015
[20] Stacked Generative Adversarial Networks. CVPR 2017 (该论文未读,之后再总结)
[21] Progressive growing of GANs for improved quality,stability,and variation. ICLR 2018
LAPGAN:
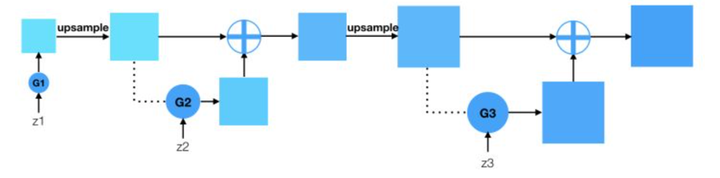
从低分辨率起步,通过不断生成高分辨率下的残差,累加得到高分辨率。图中z1,z2,z3是不同分辨率的输入。网络结构图如下:
PG-GAN:
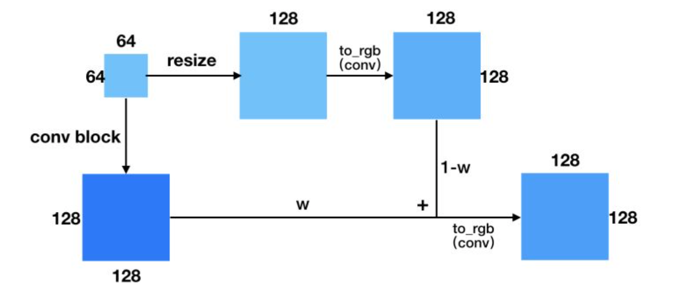
先训一个小分辨率的图像生成,训好了之后再逐步过渡到更高分辨率的图像。然后稳定训练当前分辨率,再逐步过渡到下一个更高的分辨率。更具体点来说,当处于fade in(或者说progressive growing)阶段的时候,上一分辨率(4*4)会通过resize+conv操作得到跟下一分辨率(8*8)同样大小的输出,然后两部分做加权,再通过to_rgb操作得到最终的输出。这样做的一个好处是它可以充分利用上个分辨率训练的结果,通过缓慢的过渡(w逐渐增大),使得训练生成下一分辨率的网络更加稳定。网络结构图如下:
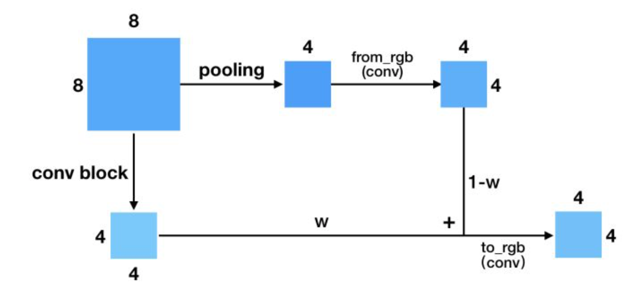
上面展示的是Generator的growing阶段。下图是Discriminator的growing,它跟Generator的类似,差别在于一个是上采样,一个是下采样。
解决的问题:除了解决了分辨率的问题,还提出了一些不引入新参数的tricks(如解决mode collapse、normalization增加训练稳定性)
参考:
Gapeng:Progressive Growing GANs简介+PyTorch复现zhuanlan.zhihu.com
3.2 Domain2Domian (隐变量、标签、短句、图像)
[22] InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. NIPS 2016
[23] Coupled Generative Adversarial Networks. NIPS 2016
[24] Unsupervised Image-to-Image Translation Networks. NIPS 2017 CoupleGANVAE
Domain2DomainPDF百度网盘链接:
链接:https://pan.baidu.com/s/1Pm-MeZKNprczhO17ZiP9dA 密码:c32p
InfoGAN:
Domain2domain的PDF中
CoupleGAN:
Domain2domain的PDF中
CoupleGANVAE:
Domain2domain的PDF中
[25] Image-to-Image Translation with Conditional Adversarial Networks. CVPR 2017 Pix2Pix
[26] Conditional Image Synthesis with Auxiliary Classifier GANs. ICML 2017
[27] CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training. ICCV 2017
[28] CGANS with projection discriminator. ICLR 2018
pix2pix:
Domain2domain的PDF中
CVAE-GAN:
未写待续
[29] Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. ICCV 2017
[30] Unsupervised Dual Learning for Image-to-Image Translation. ICCV 2017
[31] Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. ICML 2017 DiscoGAN
CycleGAN、DualGAN、DiscoGAN是一套网络结构和思想:
Domain2domain的PDF中
[32] Generative Semantic Manipulation with Contrasting GAN. CMU. Eric. Xing
[33] High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. Nvidia. Arxiv. 2017
Contrasting GAN:
做到了实例替换(替换前后实例动作不变),但是存在诸多问题,比如替换后的实例大小无法改变、替换后的实例边缘有十分明显的切割痕迹,这是由于文章采用的方法造成的,无法避免
HR-CGAN:
这篇文章采用multi-scale的Discriminator和coarse2fine的Generator能够有效帮助提升生成的质量,同时增加instance map解决同类object之间边缘不清晰的问题
[34] Adversarially learned inference. ICLR 2017
[35] Adversarial feature learning. ICLR 2017
AIL、BiGAN是一套网络结构和思想
Domain2domain的PDF中
[36] Tag Disentangled Generative Adversarial Network for Object Image Re-rendering. IJCAI 2017
[37] StackGAN: Text to Photo-Realistic Image Synthesis with Stacked Generative Adversarial Networks. ICCV 2017
[38] Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space. CVPR 2017
[39] Triple Generative Adversarial Nets. NIPS 2017
[40] Triangle Generative Adversarial Networks. NIPS 2017
TD-GAN:
Domain2domain的PDF中
PPGAN:
未完待续
TripleGAN:
Domain2domain的PDF中
TriangleGAN:
Domain2domain的PDF中
参考:
Gapeng:GAN做图像翻译的一点总结zhuanlan.zhihu.com
4. GAN的对抗思想被其他深度学习应用引入(目标检测、对抗攻击、信息检索、贝叶斯理论、Capsule、强化学习、离散输出“NLP”、自编码器、半监督学习。上学期主要研究的方向是domain2domain,以下方向尚未涉猎)
[41] Perceptual Generative Adversarial Networks for Small Object Detection. CVPR 2017
[42] Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. Arxiv. 2018.2.26
[43] IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models. SIGIR 2017
[44] Bayesian GAN. NIPS 2017
[45] CapsuleGAN: Generative Adversarial Capsule Network. Arxiv. 2018.2.17
[46] Generative Adversarial Imitation Learning. NIPS 2016
[47] SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. AAAI 2017
[48] Boundary Seeking GANs. ICLR 2018