一、MHA简介
MHA(Master High Availability)目前在mysql高可用方面比较成熟。是一套优秀的作为 mysql高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA 能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA 能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。管理节点可以单独部署在一台独立的机器上来管理多个master-slave集群,也可以部署在一台slave节点上。数据节点运行在每台mysql服务器上。Manager会定期检查master,若出现故障时,会自动将最新数据的slave提升为新的master,然后将其他的slave指向新的master。整个故障转移程序完全透明。
二、架构
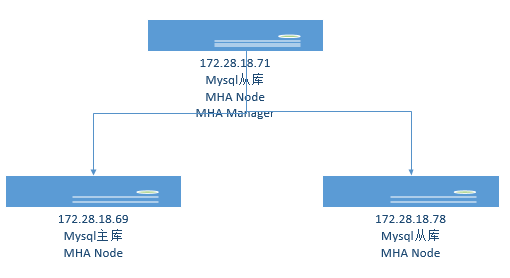
172.28.18.71作为MHA管理节点,负责管理Mysql主从集群,172.28.18.69为Mysql主库 ,172.28.18.78为Mysql从库,172.28.18.71也是mysql的一个从库,172.28.18.70为虚拟IP
二、三台服务器均安装mysql5.7,并设置好主从GTID复制模式
参照:https://www.cnblogs.com/sky-cheng/p/10955054.html
三、设置3台服务器ssh免密登陆
1、在172.28.18.71上操作生成ssh key
[root@localhost /]# cd [root@localhost ~]# pwd /root
进入root目录,执行下面命令,生成ssh key
[root@localhost ~]# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:wesmi4cYtji2OdL2cBpIpnEAITXtNmCg6MYvYyrKSFw root@localhost.localdomain The key's randomart image is: +---[RSA 2048]----+ |=+o. | |= o.. . | |+. o o | |o. + o | |.*.E . S | |*+= . | |oXo=... o | |@oO=...+ | |O*+.o.. | +----[SHA256]-----+
2、此时在 /root/.ssh/下面生成一个id_rsa.pub文件,复制为authorized_keys
[root@localhost .ssh]# cp id_rsa.pub authorized_keys [root@localhost .ssh]# ll 总用量 12 -rw-r--r-- 1 root root 408 6月 4 14:06 authorized_keys -rw------- 1 root root 1679 6月 4 14:02 id_rsa -rw-r--r-- 1 root root 408 6月 4 14:02 id_rsa.pub
3、将.ssh目录复制到另外两个节点的/root下
[root@localhost ~]# scp -P25601 -r /root/.ssh/ root@172.28.18.69:/root/ The authenticity of host '[172.28.18.69]:25601 ([172.28.18.69]:25601)' can't be established. ECDSA key fingerprint is SHA256:u5esiwOe7+3IGRBM9BOWYFMqe873DqimVeGBT2+nHdg. ECDSA key fingerprint is MD5:d3:05:0a:9d:92:46:7d:1c:ab:74:24:4b:cd:ae:81:b5. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '[172.28.18.69]:25601' (ECDSA) to the list of known hosts. root@172.28.18.69's password: id_rsa 100% 1679 152.5KB/s 00:00 id_rsa.pub 100% 408 80.3KB/s 00:00 authorized_keys 100% 408 51.6KB/s 00:00 known_hosts 100% 182 35.6KB/s 00:00
[root@localhost ~]# scp -P25601 -r /root/.ssh/ root@172.28.18.78:/root/ The authenticity of host '[172.28.18.78]:25601 ([172.28.18.78]:25601)' can't be established. ECDSA key fingerprint is SHA256:zsVfyGQ5sza1SvWg/2wCqf4SVHMsLKXYkt4QlxE+sU4. ECDSA key fingerprint is MD5:78:13:37:ab:18:a9:b0:67:3d:0f:22:53:e6:ac:b5:62. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '[172.28.18.78]:25601' (ECDSA) to the list of known hosts. root@172.28.18.78's password: id_rsa 100% 1679 190.0KB/s 00:00 id_rsa.pub 100% 408 55.0KB/s 00:00 authorized_keys 100% 408 53.2KB/s 00:00 known_hosts 100% 364 378.8KB/s 00:00 [root@localhost ~]#
4、ssh免密登陆测试
[root@localhost ~]# ssh 172.28.18.69 -p 25601 Last login: Tue Jun 4 14:13:32 2019 from 172.28.18.71 [root@server-1 ~]# exit 登出 Connection to 172.28.18.69 closed. [root@localhost ~]# ssh 172.28.18.78 -p 25601 Last login: Tue Jun 4 14:13:39 2019 from 172.28.18.71 [root@server-2 ~]# exit 登出 Connection to 172.28.18.78 closed. [root@localhost ~]#
四、三台服务器均安装MHA的node节点
1、下载mha的node源码包
[root@localhost ~]# mkdir /usr/local/src/mha4mysql-node [root@localhost ~]# cd /usr/local/src/mha4mysql-node
[root@localhost mha4mysql-node]# wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58.tar.gz
--2019-06-04 14:28:19-- https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58.tar.gz
正在解析主机 github.com (github.com)... 13.250.177.223
正在连接 github.com (github.com)|13.250.177.223|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 302 Found
位置:https://github-production-release-asset-2e65be.s3.amazonaws.com/2093258/9d78fb60-2de4-11e8-8f0c-bac507a4e54f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20190604%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20190604T062830Z&X-Amz-Expires=300&X-Amz-Signature=ed981fb367ad8bde9852881a5336f8af1a8927afcb797a6c9eddf41f5678fd75&X-Amz-SignedHeaders=host&actor_id=0&response-content-disposition=attachment%3B%20filename%3Dmha4mysql-node-0.58.tar.gz&response-content-type=application%2Foctet-stream [跟随至新的 URL]
--2019-06-04 14:28:30-- https://github-production-release-asset-2e65be.s3.amazonaws.com/2093258/9d78fb60-2de4-11e8-8f0c-bac507a4e54f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIWNJYAX4CSVEH53A%2F20190604%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20190604T062830Z&X-Amz-Expires=300&X-Amz-Signature=ed981fb367ad8bde9852881a5336f8af1a8927afcb797a6c9eddf41f5678fd75&X-Amz-SignedHeaders=host&actor_id=0&response-content-disposition=attachment%3B%20filename%3Dmha4mysql-node-0.58.tar.gz&response-content-type=application%2Foctet-stream
正在解析主机 github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)... 52.216.18.168
正在连接 github-production-release-asset-2e65be.s3.amazonaws.com (github-production-release-asset-2e65be.s3.amazonaws.com)|52.216.18.168|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:56220 (55K) [application/octet-stream]
正在保存至: “mha4mysql-node-0.58.tar.gz”
100%[===========================================================================>] 56,220 47.8KB/s 用时 1.1s
2019-06-04 14:28:32 (47.8 KB/s) - 已保存 “mha4mysql-node-0.58.tar.gz” [56220/56220])
2、安装perl-DBD-MySQL
[root@localhost mha4mysql-node]# yum install perl-DBD-MySQL -y [root@localhost mha4mysql-node]# yum install perl-DBI -y [root@localhost mha4mysql-node]# yum install mysql-libs -y
3、解压、编译
[root@localhost mha4mysql-node]# tar -zxvf mha4mysql-node-0.58.tar.gz drwxr-xr-x 2 zabbix zabbix 49 3月 23 2018 t [root@localhost mha4mysql-node-0.58]# perl Makefile.PL Can't locate ExtUtils/MakeMaker.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/Install/Can.pm line 5.
报错,不能定位ExtUtils,怎安装ExtUtils-MakeMaker
[root@localhost src]# mkdir /usr/local/src/ExtUtils-MakeMaker [root@localhost src]# cd ExtUtils-MakeMaker/ [root@localhost ExtUtils-MakeMaker]# wget http://files.directadmin.com/services/9.0/ExtUtils-MakeMaker-6.31.tar.gz
[root@localhost ExtUtils-MakeMaker]# tar -zxvf ExtUtils-MakeMaker-6.31.tar.gz [root@localhost ExtUtils-MakeMaker]# cd ExtUtils-MakeMaker-6.31 [root@localhost ExtUtils-MakeMaker-6.31]# perl Makefile.PL Checking if your kit is complete... Looks good Could not open '': 没有那个文件或目录 at lib/ExtUtils/MM_Unix.pm line 2697.
报错,则安装perl-ExtUtils-MakeMaker
[root@localhost ExtUtils-MakeMaker-6.31]# yum install perl-ExtUtils-MakeMaker
再次编译
[root@localhost ExtUtils-MakeMaker-6.31]# perl Makefile.PL Checking if your kit is complete... Looks good Writing Makefile for ExtUtils::MakeMaker [root@localhost ExtUtils-MakeMaker-6.31]#
成功,继续make make install
[root@localhost ExtUtils-MakeMaker-6.31]# make && make install
ExtUtils-MakeMaker安装成功后,再次编译mha4mysql-node
[root@localhost mha4mysql-node-0.58]# cd /usr/local/src/mha4mysql-node/mha4mysql-node-0.58 [root@localhost mha4mysql-node-0.58]# perl Makefile.PL *** Module::AutoInstall version 1.06 *** Checking for Perl dependencies... Can't locate CPAN.pm in @INC (@INC contains: inc /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at inc/Module/AutoInstall.pm line 304.
提示找不到CPAN.pm,则安装CPAN模块
[root@localhost mha4mysql-node-0.58]# mkdir /usr/local/src/CPAN [root@localhost mha4mysql-node-0.58]# cd /usr/local/src/CPAN/ [root@localhost CPAN]# wget http://search.cpan.org/CPAN/authors/id/A/AN/ANDK/CPAN-1.9205.tar.gz [root@localhost CPAN]# tar -zxvf CPAN-1.9205.tar.gz [root@localhost CPAN]# cd CPAN-1.9205 [root@localhost CPAN-1.9205]# perl Makefile.PL Importing PAUSE public key into your GnuPG keychain... gpg: 新的配置文件‘/root/.gnupg/gpg.conf’已建立 gpg: 警告:在‘/root/.gnupg/gpg.conf’里的选项于此次运行期间未被使用 done! (You may wish to trust it locally with 'gpg --lsign-key 450F89EC') WARNING: EXTRA_META is not a known parameter. Checking if your kit is complete... Looks good Warning: prerequisite Test::More 0 not found. 'EXTRA_META' is not a known MakeMaker parameter name. Writing Makefile for CPAN [root@localhost CPAN-1.9205]# make && make install
再次编译mha4mysql-node
[root@server-1 CPAN-1.9205]# cd /usr/local/src/mha4mysql-node/mha4mysql-node-0.58
[root@localhost mha4mysql-node-0.58]# perl Makefile.PL *** Module::AutoInstall version 1.06 *** Checking for Perl dependencies... [Core Features] - DBI ...loaded. (1.627) - DBD::mysql ...loaded. (4.023) *** Module::AutoInstall configuration finished. Checking if your kit is complete... Looks good Writing Makefile for mha4mysql::node [root@localhost mha4mysql-node-0.58]#
成功,继续make && make install
[root@localhost mha4mysql-node-0.58]# make && make install
另外两台服务器也同样安装mha4mysql-node
五、管理节点安装mha4mysql-manager
[root@localhost mha4mysql-node-0.58] yum install -y perl-Mail-Sender perl-Email-Date-Format perl-MIME-Types perl-MIME-Lite perl-Parallel-ForkManager perl-Mail-Sendmail
[root@localhost mha4mysql-node-0.58] yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-YAML-Tiny perl-PAR-Dist perl-Module-ScanDeps perl-Module-CoreList perl-Module-Build perl-CPAN perl-YAML perl-CPANPLUS perl-File-Remove perl-Module-Install
[root@localhost masterha]# cpan Module::Install
[root@localhost src]# perl -MCPAN -e "install Class::Load"
[root@localhost mha4mysql-node-0.58]# mkdir /usr/local/src/mha4mysql-manager [root@localhost mha4mysql-node-0.58]# cd /usr/local/src/mha4mysql-manager [root@localhost mha4mysql-manager]# wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58.tar.gz [root@localhost mha4mysql-manager]# tar -zxvf mha4mysql-manager-0.58.tar.gz [root@localhost mha4mysql-manager]# cd mha4mysql-manager-0.58
[root@localhost mha4mysql-manager-0.58]# perl Makefile.PL
*** Module::AutoInstall version 1.06
*** Checking for Perl dependencies...
[Core Features]
- DBI ...loaded. (1.627)
- DBD::mysql ...loaded. (4.023)
- Time::HiRes ...loaded. (1.9725)
- Config::Tiny ...loaded. (2.14)
- Log::Dispatch ...loaded. (2.41)
- Parallel::ForkManager ...loaded. (2.02)
- MHA::NodeConst ...loaded. (0.58)
*** Module::AutoInstall configuration finished.
Writing Makefile for mha4mysql::manager
Writing MYMETA.yml and MYMETA.json
[root@localhost mha4mysql-manager-0.58]#
make && make install
[root@server-1 mha4mysql-node-0.58]# make && make install
查看结果
[root@localhost bin]# ll /usr/local/bin/masterha_* -r-xr-xr-x 1 root root 1995 6月 4 16:26 /usr/local/bin/masterha_check_repl -r-xr-xr-x 1 root root 1779 6月 4 16:26 /usr/local/bin/masterha_check_ssh -r-xr-xr-x 1 root root 1865 6月 4 16:26 /usr/local/bin/masterha_check_status -r-xr-xr-x 1 root root 3201 6月 4 16:26 /usr/local/bin/masterha_conf_host -r-xr-xr-x 1 root root 2517 6月 4 16:26 /usr/local/bin/masterha_manager -r-xr-xr-x 1 root root 2165 6月 4 16:26 /usr/local/bin/masterha_master_monitor -r-xr-xr-x 1 root root 2373 6月 4 16:26 /usr/local/bin/masterha_master_switch -r-xr-xr-x 1 root root 5172 6月 4 16:26 /usr/local/bin/masterha_secondary_check -r-xr-xr-x 1 root root 1739 6月 4 16:26 /usr/local/bin/masterha_stop
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_manger 启动MHA
masterha_check_status 检测当前MHA运行状态
masterha_master_monitor 检测master是否宕机
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
六、编写管理节点配置文件
[root@localhost ~]# mkdir /etc/masterha [root@localhost ~]# cd /etc/masterha/ [root@localhost masterha]# vim app1.cnf [server default] manager_workdir=/etc/mha manager_log=/etc/mha/manager.log
#mysql用户和密码 password=Zaq1xsw@ user=root
#监控主库,发送ping包的时间间隔,默认是3秒,尝试3次不成功,则自动进行切换操作 ping_interval=1
#复制用户 repl_password=Zaq1xsw@ repl_user=repl #report_script=/usr/local/send_report
#通过第三方机器确认目标主库是否存活,不是必须的,就算没有也是能用#secondary_check_script=masterha_secondary_check -s 172.28.18.71 -s 172.28.18.69 -s 172.28.18.78
#故障自动切换VIP调用脚本,不是必须的,就算没有也是能用,master_ip_failover_script=/etc/masterha/scripts/master_ip_failover
#ssh用户 ssh_user=root ssh_port=25601
[server1]
hostname=172.28.18.71
candidate_master=1
[server2]
hostname=172.28.18.69
candidate_master=1
[server3]
hostname=172.28.18.78
candidate_master=1
七、检查ssh连接
root@localhost ~]
[root@localhost mysql-5.7.26]# masterha_check_ssh --conf=/etc/masterha/app1.cnf Thu Jun 6 14:11:16 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Jun 6 14:11:16 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Thu Jun 6 14:11:16 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Thu Jun 6 14:11:16 2019 - [info] Starting SSH connection tests.. Thu Jun 6 14:11:19 2019 - [debug] Thu Jun 6 14:11:16 2019 - [debug] Connecting via SSH from root@172.28.18.71(172.28.18.71:25601) to root@172.28.18.69(172.28.18.69:25601).. Thu Jun 6 14:11:18 2019 - [debug] ok. Thu Jun 6 14:11:18 2019 - [debug] Connecting via SSH from root@172.28.18.71(172.28.18.71:25601) to root@172.28.18.78(172.28.18.78:25601).. Thu Jun 6 14:11:18 2019 - [debug] ok. ^[[AThu Jun 6 14:11:29 2019 - [debug] Thu Jun 6 14:11:17 2019 - [debug] Connecting via SSH from root@172.28.18.78(172.28.18.78:25601) to root@172.28.18.71(172.28.18.71:25601).. Thu Jun 6 14:11:23 2019 - [debug] ok. Thu Jun 6 14:11:23 2019 - [debug] Connecting via SSH from root@172.28.18.78(172.28.18.78:25601) to root@172.28.18.69(172.28.18.69:25601).. Thu Jun 6 14:11:28 2019 - [debug] ok. Thu Jun 6 14:11:29 2019 - [debug] Thu Jun 6 14:11:17 2019 - [debug] Connecting via SSH from root@172.28.18.69(172.28.18.69:25601) to root@172.28.18.71(172.28.18.71:25601).. Thu Jun 6 14:11:22 2019 - [debug] ok. Thu Jun 6 14:11:22 2019 - [debug] Connecting via SSH from root@172.28.18.69(172.28.18.69:25601) to root@172.28.18.78(172.28.18.78:25601).. Thu Jun 6 14:11:28 2019 - [debug] ok. Thu Jun 6 14:11:29 2019 - [info] All SSH connection tests passed successfully.
测试成功
八、检查复制
[root@localhost mysql-5.7.26]# masterha_check_repl --conf=/etc/masterha/app1.cnf Thu Jun 6 13:54:14 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Jun 6 13:54:14 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Thu Jun 6 13:54:14 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Thu Jun 6 13:54:14 2019 - [info] MHA::MasterMonitor version 0.58. Thu Jun 6 13:54:15 2019 - [error][/usr/local/share/perl5/MHA/ServerManager.pm, ln301] install_driver(mysql) failed: Attempt to reload DBD/mysql.pm aborted. Compilation failed in require at (eval 55) line 3. at /usr/local/share/perl5/MHA/DBHelper.pm line 208. at /usr/local/share/perl5/MHA/Server.pm line 166. Thu Jun 6 13:54:15 2019 - [error][/usr/local/share/perl5/MHA/ServerManager.pm, ln301] install_driver(mysql) failed: Attempt to reload DBD/mysql.pm aborted. Compilation failed in require at (eval 55) line 3. at /usr/local/share/perl5/MHA/DBHelper.pm line 208. at /usr/local/share/perl5/MHA/Server.pm line 166. Thu Jun 6 13:54:16 2019 - [error][/usr/local/share/perl5/MHA/ServerManager.pm, ln309] Got fatal error, stopping operations Thu Jun 6 13:54:16 2019 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. at /usr/local/share/perl5/MHA/MasterMonitor.pm line 329. Thu Jun 6 13:54:16 2019 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers. Thu Jun 6 13:54:16 2019 - [info] Got exit code 1 (Not master dead). MySQL Replication Health is NOT OK!
报错,此时检查是否安装了perl-DBD-mysql
[root@localhost mysql-5.7.26]# yum install perl-DBD-MySQL 已加载插件:fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.huaweicloud.com * epel: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com 正在解决依赖关系 --> 正在检查事务 ---> 软件包 perl-DBD-MySQL.x86_64.0.4.023-6.el7 将被 安装 --> 正在处理依赖关系 libmysqlclient.so.18(libmysqlclient_18)(64bit),它被软件包 perl-DBD-MySQL-4.023-6.el7.x86_64 需要 --> 正在处理依赖关系 libmysqlclient.so.18()(64bit),它被软件包 perl-DBD-MySQL-4.023-6.el7.x86_64 需要 --> 正在检查事务 ---> 软件包 mariadb-libs.x86_64.1.5.5.60-1.el7_5 将被 安装 Removing mariadb-libs.x86_64 1:5.5.60-1.el7_5 - u due to obsoletes from installed mysql-community-libs-5.7.26-1.el7.x86_64 base/7/x86_64/filelists_db | 7.1 MB 00:00:03 --> 正在使用新的信息重新解决依赖关系 --> 正在检查事务 ---> 软件包 mariadb-libs.x86_64.1.5.5.60-1.el7_5 将被 安装 --> 正在处理依赖关系 libmysqlclient.so.18(libmysqlclient_18)(64bit),它被软件包 perl-DBD-MySQL-4.023-6.el7.x86_64 需要 --> 正在处理依赖关系 libmysqlclient.so.18(libmysqlclient_18)(64bit),它被软件包 2:postfix-2.10.1-7.el7.x86_64 需要 --> 正在处理依赖关系 libmysqlclient.so.18()(64bit),它被软件包 perl-DBD-MySQL-4.023-6.el7.x86_64 需要 --> 正在处理依赖关系 libmysqlclient.so.18()(64bit),它被软件包 2:postfix-2.10.1-7.el7.x86_64 需要 --> 解决依赖关系完成 错误:软件包:perl-DBD-MySQL-4.023-6.el7.x86_64 (base) 需要:libmysqlclient.so.18(libmysqlclient_18)(64bit) 错误:软件包:2:postfix-2.10.1-7.el7.x86_64 (@anaconda) 需要:libmysqlclient.so.18(libmysqlclient_18)(64bit) 错误:软件包:2:postfix-2.10.1-7.el7.x86_64 (@anaconda) 需要:libmysqlclient.so.18()(64bit) 错误:软件包:perl-DBD-MySQL-4.023-6.el7.x86_64 (base) 需要:libmysqlclient.so.18()(64bit) 您可以尝试添加 --skip-broken 选项来解决该问题 ** 发现 2 个已存在的 RPM 数据库问题, 'yum check' 输出如下: 2:postfix-2.10.1-7.el7.x86_64 有缺少的需求 libmysqlclient.so.18()(64bit) 2:postfix-2.10.1-7.el7.x86_64 有缺少的需求 libmysqlclient.so.18(libmysqlclient_18)(64bit) [root@localhost mysql-5.7.26]# rpm -ivh mysql-community-libs-compat-5.7.18-1.el7.x86_64.rpm 错误:打开 mysql-community-libs-compat-5.7.18-1.el7.x86_64.rpm 失败: 没有那个文件或目录 [root@localhost mysql-5.7.26]# ll
安装perl-DBD-MySQL报错没有找到libmysqlclient.so.18()(64bit),此时需要安装mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm包
[root@localhost mysql-5.7.26]# wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm --2019-06-06 14:00:09-- https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm 正在解析主机 dev.mysql.com (dev.mysql.com)... 137.254.60.11 正在连接 dev.mysql.com (dev.mysql.com)|137.254.60.11|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 302 Found 位置:https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm [跟随至新的 URL] --2019-06-06 14:00:15-- https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm 正在解析主机 cdn.mysql.com (cdn.mysql.com)... 23.41.87.110 正在连接 cdn.mysql.com (cdn.mysql.com)|23.41.87.110|:443... 已连接。 已发出 HTTP 请求,正在等待回应... 200 OK 长度:2118444 (2.0M) [application/x-redhat-package-manager] 正在保存至: “mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm” 100%[===================================================================================>] 2,118,444 11.4KB/s 用时 2m 50s 2019-06-06 14:03:09 (12.1 KB/s) - 已保存 “mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm” [2118444/2118444]) [root@localhost mysql-5.7.26]# rpm -ivh mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm 警告:mysql-community-libs-compat-5.7.26-1.el7.x86_64.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY 准备中... ################################# [100%] 正在升级/安装... 1:mysql-community-libs-compat-5.7.2################################# [100%]
再次安装perl-DBD-MySQL
[root@localhost mysql-5.7.26]# yum install perl-DBD-MySQL 已加载插件:fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.huaweicloud.com * epel: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com 正在解决依赖关系 --> 正在检查事务 ---> 软件包 perl-DBD-MySQL.x86_64.0.4.023-6.el7 将被 安装 --> 解决依赖关系完成 依赖关系解决 ============================================================================================================================= Package 架构 版本 源 大小 ============================================================================================================================= 正在安装: perl-DBD-MySQL x86_64 4.023-6.el7 base 140 k 事务概要 ============================================================================================================================= 安装 1 软件包 总下载量:140 k 安装大小:323 k Is this ok [y/d/N]: y Downloading packages: perl-DBD-MySQL-4.023-6.el7.x86_64.rpm | 140 kB 00:00:00 Running transaction check Running transaction test Transaction test succeeded Running transaction 警告:RPM 数据库已被非 yum 程序修改。 正在安装 : perl-DBD-MySQL-4.023-6.el7.x86_64 1/1 验证中 : perl-DBD-MySQL-4.023-6.el7.x86_64 1/1 已安装: perl-DBD-MySQL.x86_64 0:4.023-6.el7 完毕!
再次测试repl
[root@localhost mysql-5.7.26]# masterha_check_repl --conf=/etc/masterha/app1.cnf Thu Jun 6 14:13:05 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Jun 6 14:13:05 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Thu Jun 6 14:13:05 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Thu Jun 6 14:13:05 2019 - [info] MHA::MasterMonitor version 0.58. Thu Jun 6 14:13:06 2019 - [info] GTID failover mode = 1 Thu Jun 6 14:13:06 2019 - [info] Dead Servers: Thu Jun 6 14:13:06 2019 - [info] Alive Servers: Thu Jun 6 14:13:06 2019 - [info] 172.28.18.71(172.28.18.71:3306) Thu Jun 6 14:13:06 2019 - [info] 172.28.18.69(172.28.18.69:3306) Thu Jun 6 14:13:06 2019 - [info] 172.28.18.78(172.28.18.78:3306) Thu Jun 6 14:13:06 2019 - [info] Alive Slaves: Thu Jun 6 14:13:06 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Thu Jun 6 14:13:06 2019 - [info] GTID ON Thu Jun 6 14:13:06 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Thu Jun 6 14:13:06 2019 - [info] Primary candidate for the new Master (candidate_master is set) Thu Jun 6 14:13:06 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Thu Jun 6 14:13:06 2019 - [info] GTID ON Thu Jun 6 14:13:06 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Thu Jun 6 14:13:06 2019 - [info] Primary candidate for the new Master (candidate_master is set) Thu Jun 6 14:13:06 2019 - [info] Current Alive Master: 172.28.18.69(172.28.18.69:3306) Thu Jun 6 14:13:06 2019 - [info] Checking slave configurations.. Thu Jun 6 14:13:06 2019 - [info] read_only=1 is not set on slave 172.28.18.71(172.28.18.71:3306). Thu Jun 6 14:13:06 2019 - [info] read_only=1 is not set on slave 172.28.18.78(172.28.18.78:3306). Thu Jun 6 14:13:06 2019 - [info] Checking replication filtering settings.. Thu Jun 6 14:13:06 2019 - [info] binlog_do_db= , binlog_ignore_db= Thu Jun 6 14:13:06 2019 - [info] Replication filtering check ok. Thu Jun 6 14:13:06 2019 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. Thu Jun 6 14:13:06 2019 - [info] Checking SSH publickey authentication settings on the current master.. Thu Jun 6 14:13:11 2019 - [warning] HealthCheck: Got timeout on checking SSH connection to 172.28.18.69! at /usr/local/share/perl5/MHA/HealthCheck.pm line 343. Thu Jun 6 14:13:11 2019 - [info] 172.28.18.69(172.28.18.69:3306) (current master) +--172.28.18.71(172.28.18.71:3306) +--172.28.18.78(172.28.18.78:3306) Thu Jun 6 14:13:11 2019 - [info] Checking replication health on 172.28.18.71.. Thu Jun 6 14:13:11 2019 - [info] ok. Thu Jun 6 14:13:11 2019 - [info] Checking replication health on 172.28.18.78.. Thu Jun 6 14:13:11 2019 - [info] ok. Thu Jun 6 14:13:11 2019 - [warning] master_ip_failover_script is not defined. Thu Jun 6 14:13:11 2019 - [warning] shutdown_script is not defined. Thu Jun 6 14:13:11 2019 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK.
测试成功,信息显示:
Alive Slaves: 172.28.18.78 172.28.18.71 ---- 活动从库为172.28.18.78,
GTID ON--GTID复制模式开启
Replicating from 172.28.18.69 ----从172.28.18.69主库复制
Current Alive Master: 172.28.18.69(172.28.18.69:3306) --当前活动主库为172.28.18.69
九、后台启动MHA
[root@localhost bin]# masterha_manager --conf=/etc/masterha/app1.cnf & [1] 12822 [root@localhost bin]# Thu Jun 6 10:25:43 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Jun 6 10:25:43 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Thu Jun 6 10:25:43 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf.. ^C [root@localhost bin]#
查看进程
[root@localhost ~]# ps -ef|grep masterha root 12822 10037 2 10:25 pts/3 00:00:00 perl /usr/local/bin/masterha_manager --conf=/etc/masterha/app1.cnf root 12863 31965 0 10:25 pts/2 00:00:00 grep --color=auto masterha
十、查看MHA状态
[root@localhost bin]# masterha_check_status --conf=/etc/masterha/app1.cnf app1 (pid:12822) is running(0:PING_OK), master:172.28.18.69
十一、停止MHA
[root@localhost bin]# masterha_stop --conf=/etc/masterha/app1.cnf Stopped app1 successfully. [1]+ 退出 1 masterha_manager --conf=/etc/masterha/app1.cnf
十二、编写VIP切换脚本
[root@localhost /]# mkdir /etc/masterha/scripts [root@localhost /]# cd /etc/masterha/scripts/[root@localhost scripts]# vim master_ip_failover
#!/usr/bin/env perl use strict; use warnings FATAL => 'all'; use Getopt::Long; my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port ); my $vip = '172.28.18.70/24'; # Virtual IP my $key = "1"; my $int = "em1"; my $ssh_start_vip = "/user/sbin/ifconfig $int:$key $vip"; my $ssh_stop_vip = "/user/sbin/ifconfig $int:$key down"; $ssh_user = "root"; GetOptions( 'command=s' => $command, 'ssh_user=s' => $ssh_user, 'orig_master_host=s' => $orig_master_host, 'orig_master_ip=s' => $orig_master_ip, 'orig_master_port=i' => $orig_master_port, 'new_master_host=s' => $new_master_host, 'new_master_ip=s' => $new_master_ip, 'new_master_port=i' => $new_master_port, ); exit &main(); sub main { print " IN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip=== "; if ( $command eq "stop" || $command eq "stopssh" ) { # $orig_master_host, $orig_master_ip, $orig_master_port are passed. # If you manage master ip address at global catalog database, # invalidate orig_master_ip here. my $exit_code = 1; eval { print "Disabling the VIP on old master: $orig_master_host "; &stop_vip(); $exit_code = 0; }; if ($@) { warn "Got Error: $@ "; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { # all arguments are passed. # If you manage master ip address at global catalog database, # activate new_master_ip here. # You can also grant write access (create user, set read_only=0, etc) here. my $exit_code = 10; eval { print "Enabling the VIP - $vip on the new master - $new_master_host "; &start_vip(); $exit_code = 0; }; if ($@) { warn $@; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { print "Checking the Status of the script.. OK "; #`ssh $ssh_user@cluster1 " $ssh_start_vip "`; &status(); exit 0; } else { &usage(); exit 1; } } # A simple system call that enable the VIP on the new master sub start_vip() { `ssh $ssh_user@$new_master_host " $ssh_start_vip "`; `ssh $ssh_user@$new_master_host " $arp_effect "`; # `ssh $ssh_user@$new_master_host " $test "`; } # A simple system call that disable the VIP on the old_master sub stop_vip() { `ssh $ssh_user@$orig_master_host " $ssh_stop_vip "`; } sub status() { print `ssh $ssh_user@$orig_master_host " ip add show $int "`; } sub usage { print "Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port ";
}
十三、测试VIP切换脚本
1、首先使用start参数设置master服务器的VIP
[root@localhost scripts]# ./master_ip_failover --command=start --new_master_host=172.28.18.71 IN SCRIPT TEST====/usr/sbin/ifconfig em1:1 down==/usr/sbin/ifconfig em1:1 172.28.18.70/24=== Enabling the VIP - 172.28.18.70/24 on the new master - 172.28.18.71
查看VIP
[root@localhost scripts]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 84:2b:2b:5c:dc:15 brd ff:ff:ff:ff:ff:ff inet 172.28.18.71/28 brd 172.28.18.79 scope global noprefixroute em1 valid_lft forever preferred_lft forever inet 172.28.18.70/24 brd 172.28.18.255 scope global em1:1 valid_lft forever preferred_lft forever inet6 fe80::e0b8:7d61:e043:692/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: em2: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:17 brd ff:ff:ff:ff:ff:ff 4: em3: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:19 brd ff:ff:ff:ff:ff:ff 5: em4: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:1b brd ff:ff:ff:ff:ff:ff 6: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0
设置成功,
2、删除VIP
[root@localhost scripts]# ./master_ip_failover --command=stop --orig_master_host=172.28.18.71 IN SCRIPT TEST====/usr/sbin/ifconfig em1:1 down==/usr/sbin/ifconfig em1:1 172.28.18.70/24=== Disabling the VIP on old master: 172.28.18.71
查看结果
[root@localhost scripts]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 84:2b:2b:5c:dc:15 brd ff:ff:ff:ff:ff:ff inet 172.28.18.71/28 brd 172.28.18.79 scope global noprefixroute em1 valid_lft forever preferred_lft forever inet6 fe80::e0b8:7d61:e043:692/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: em2: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:17 brd ff:ff:ff:ff:ff:ff 4: em3: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:19 brd ff:ff:ff:ff:ff:ff 5: em4: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:1b brd ff:ff:ff:ff:ff:ff 6: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0
172.28.18.70的VIP已经被移除
3、查看目前VIP状态
[root@localhost scripts]# ./master_ip_failover --command=status --orig_master_host=172.28.18.71 IN SCRIPT TEST====/usr/sbin/ifconfig em1:1 down==/usr/sbin/ifconfig em1:1 172.28.18.70/24=== Checking the Status of the script.. OK 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 84:2b:2b:5c:dc:15 brd ff:ff:ff:ff:ff:ff inet 172.28.18.71/28 brd 172.28.18.79 scope global noprefixroute em1 valid_lft forever preferred_lft forever inet 172.28.18.70/24 brd 172.28.18.255 scope global em1:1 valid_lft forever preferred_lft forever inet6 fe80::e0b8:7d61:e043:692/64 scope link noprefixroute valid_lft forever preferred_lft forever
到此,整个环境搭建完毕,下一步测试故障转移
十四、测试故障转移
1、另开一个窗口,查看实时日志输出
[root@localhost ~]# tail -f /etc/masterha/manager.log
2、启动MHA
[root@localhost ~]# masterha_manager --conf=/etc/masterha/app1.cnf & [1] 28459 [root@localhost ~]# Mon Jun 10 16:05:12 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Mon Jun 10 16:05:12 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Mon Jun 10 16:05:12 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf..
3、查看日志
Mon Jun 10 16:05:12 2019 - [info] MHA::MasterMonitor version 0.58. Mon Jun 10 16:05:14 2019 - [info] GTID failover mode = 1 Mon Jun 10 16:05:14 2019 - [info] Dead Servers: Mon Jun 10 16:05:14 2019 - [info] Alive Servers: Mon Jun 10 16:05:14 2019 - [info] 172.28.18.71(172.28.18.71:3306) Mon Jun 10 16:05:14 2019 - [info] 172.28.18.69(172.28.18.69:3306) Mon Jun 10 16:05:14 2019 - [info] 172.28.18.78(172.28.18.78:3306) Mon Jun 10 16:05:14 2019 - [info] Alive Slaves: Mon Jun 10 16:05:14 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Mon Jun 10 16:05:14 2019 - [info] GTID ON Mon Jun 10 16:05:14 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Mon Jun 10 16:05:14 2019 - [info] Primary candidate for the new Master (candidate_master is set) Mon Jun 10 16:05:14 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Mon Jun 10 16:05:14 2019 - [info] GTID ON Mon Jun 10 16:05:14 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Mon Jun 10 16:05:14 2019 - [info] Primary candidate for the new Master (candidate_master is set) Mon Jun 10 16:05:14 2019 - [info] Current Alive Master: 172.28.18.69(172.28.18.69:3306) Mon Jun 10 16:05:14 2019 - [info] Checking slave configurations.. Mon Jun 10 16:05:14 2019 - [info] read_only=1 is not set on slave 172.28.18.71(172.28.18.71:3306). Mon Jun 10 16:05:14 2019 - [info] Checking replication filtering settings.. Mon Jun 10 16:05:14 2019 - [info] binlog_do_db= , binlog_ignore_db= Mon Jun 10 16:05:14 2019 - [info] Replication filtering check ok. Mon Jun 10 16:05:14 2019 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. Mon Jun 10 16:05:14 2019 - [info] Checking SSH publickey authentication settings on the current master.. Mon Jun 10 16:05:14 2019 - [info] HealthCheck: SSH to 172.28.18.69 is reachable. Mon Jun 10 16:05:14 2019 - [info] 172.28.18.69(172.28.18.69:3306) (current master) +--172.28.18.71(172.28.18.71:3306) +--172.28.18.78(172.28.18.78:3306) Mon Jun 10 16:05:14 2019 - [info] Checking master_ip_failover_script status: Mon Jun 10 16:05:14 2019 - [info] /etc/masterha/scripts/master_ip_failover --command=status --ssh_user=root --orig_master_host=172.28.18.69 --orig_master_ip=172.28.18.69 --orig_master_port=3306 --orig_master_ssh_port=25601 Unknown option: orig_master_ssh_port IN SCRIPT TEST====/usr/sbin/ifconfig em1:1 down==/usr/sbin/ifconfig em1:1 172.28.18.70/24=== Checking the Status of the script.. OK 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 14:fe:b5:dc:2c:77 brd ff:ff:ff:ff:ff:ff inet 172.28.18.69/28 brd 172.28.18.79 scope global noprefixroute em1 valid_lft forever preferred_lft forever inet 172.28.18.70/32 scope global em1 valid_lft forever preferred_lft forever inet6 fe80::b3e8:e3b2:2242:a2ed/64 scope link noprefixroute valid_lft forever preferred_lft forever Mon Jun 10 16:05:14 2019 - [info] OK. Mon Jun 10 16:05:14 2019 - [warning] shutdown_script is not defined. Mon Jun 10 16:05:14 2019 - [info] Set master ping interval 1 seconds. Mon Jun 10 16:05:14 2019 - [info] Set secondary check script: masterha_secondary_check -s 172.28.18.71 -s 172.28.18.69 -s 172.28.18.78 Mon Jun 10 16:05:14 2019 - [info] Starting ping health check on 172.28.18.69(172.28.18.69:3306).. Mon Jun 10 16:05:14 2019 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
日志中可以看出
172.28.18.69(172.28.18.69:3306) (current master) +--172.28.18.71(172.28.18.71:3306) +--172.28.18.78(172.28.18.78:3306)
172.28.18.69为主库, 172.28.18.71 ,172.28.18.78为从库
2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 14:fe:b5:dc:2c:77 brd ff:ff:ff:ff:ff:ff inet 172.28.18.69/28 brd 172.28.18.79 scope global noprefixroute em1 valid_lft forever preferred_lft forever inet 172.28.18.70/32 scope global em1 valid_lft forever preferred_lft forever inet6 fe80::b3e8:e3b2:2242:a2ed/64 scope link noprefixroute valid_lft forever preferred_lft forever172.28.18.69上已经设置了172.28.18.70的VIP
4、将172.28.18.69服务器主库mysqld关掉,模拟故障
[root@server-1 ~]# killall mysqld [root@server-1 ~]# ps -ef|grep mysqld root 8188 29237 0 17:05 pts/0 00:00:00 grep --color=auto mysqld
5、观察172.28.18.71上的manager.log日志
Mon Jun 10 17:26:52 2019 - [warning] Got error on MySQL select ping: 2013 (Lost connection to MySQL server during query) Mon Jun 10 17:26:52 2019 - [info] Executing secondary network check script: masterha_secondary_check -s 172.28.18.71 -s 172.28.18.69 -s 172.28.18.78 --user=root --master_host=172.28.18.69 --master_ip=172.28.18.69 --master_port=3306 --master_user=root --master_password=Zaq1xsw@ --ping_type=SELECT Mon Jun 10 17:26:52 2019 - [info] Executing SSH check script: exit 0 Mon Jun 10 17:26:52 2019 - [info] HealthCheck: SSH to 172.28.18.69 is reachable. Monitoring server 172.28.18.71 is reachable, Master is not reachable from 172.28.18.71. OK. Monitoring server 172.28.18.69 is reachable, Master is not reachable from 172.28.18.69. OK. Mon Jun 10 17:26:53 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.28.18.69' (111)) Mon Jun 10 17:26:53 2019 - [warning] Connection failed 2 time(s).. Monitoring server 172.28.18.78 is reachable, Master is not reachable from 172.28.18.78. OK. Mon Jun 10 17:26:53 2019 - [info] Master is not reachable from all other monitoring servers. Failover should start. Mon Jun 10 17:26:54 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.28.18.69' (111)) Mon Jun 10 17:26:54 2019 - [warning] Connection failed 3 time(s).. Mon Jun 10 17:26:55 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.28.18.69' (111)) Mon Jun 10 17:26:55 2019 - [warning] Connection failed 4 time(s).. Mon Jun 10 17:26:55 2019 - [warning] Master is not reachable from health checker! Mon Jun 10 17:26:55 2019 - [warning] Master 172.28.18.69(172.28.18.69:3306) is not reachable! Mon Jun 10 17:26:55 2019 - [warning] SSH is reachable. Mon Jun 10 17:26:55 2019 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/masterha/app1.cnf again, and trying to connect to all servers to check server status.. Mon Jun 10 17:26:55 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Mon Jun 10 17:26:55 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Mon Jun 10 17:26:55 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Mon Jun 10 17:26:56 2019 - [info] GTID failover mode = 1 Mon Jun 10 17:26:56 2019 - [info] Dead Servers: Mon Jun 10 17:26:56 2019 - [info] 172.28.18.69(172.28.18.69:3306) Mon Jun 10 17:26:56 2019 - [info] Alive Servers: Mon Jun 10 17:26:56 2019 - [info] 172.28.18.71(172.28.18.71:3306) Mon Jun 10 17:26:56 2019 - [info] 172.28.18.78(172.28.18.78:3306) Mon Jun 10 17:26:56 2019 - [info] Alive Slaves: Mon Jun 10 17:26:56 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Mon Jun 10 17:26:56 2019 - [info] GTID ON Mon Jun 10 17:26:56 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Mon Jun 10 17:26:56 2019 - [info] Primary candidate for the new Master (candidate_master is set) Mon Jun 10 17:26:56 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Mon Jun 10 17:26:56 2019 - [info] GTID ON Mon Jun 10 17:26:56 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Mon Jun 10 17:26:56 2019 - [info] Primary candidate for the new Master (candidate_master is set) Mon Jun 10 17:26:56 2019 - [info] Checking slave configurations.. Mon Jun 10 17:26:56 2019 - [info] read_only=1 is not set on slave 172.28.18.71(172.28.18.71:3306). Mon Jun 10 17:26:56 2019 - [info] Checking replication filtering settings.. Mon Jun 10 17:26:56 2019 - [info] Replication filtering check ok. Mon Jun 10 17:26:56 2019 - [info] Master is down! Mon Jun 10 17:26:56 2019 - [info] Terminating monitoring script. Mon Jun 10 17:26:56 2019 - [info] Got exit code 20 (Master dead). Mon Jun 10 17:26:56 2019 - [info] MHA::MasterFailover version 0.58. Mon Jun 10 17:26:56 2019 - [info] Starting master failover. Mon Jun 10 17:26:56 2019 - [info] Mon Jun 10 17:26:56 2019 - [info] * Phase 1: Configuration Check Phase.. Mon Jun 10 17:26:56 2019 - [info] Mon Jun 10 17:26:57 2019 - [info] GTID failover mode = 1 Mon Jun 10 17:26:57 2019 - [info] Dead Servers: Mon Jun 10 17:26:57 2019 - [info] 172.28.18.69(172.28.18.69:3306) Mon Jun 10 17:26:57 2019 - [info] Checking master reachability via MySQL(double check)... Mon Jun 10 17:26:57 2019 - [info] ok. Mon Jun 10 17:26:57 2019 - [info] Alive Servers: Mon Jun 10 17:26:57 2019 - [info] 172.28.18.71(172.28.18.71:3306) Mon Jun 10 17:26:57 2019 - [info] 172.28.18.78(172.28.18.78:3306) Mon Jun 10 17:26:57 2019 - [info] Alive Slaves: Mon Jun 10 17:26:57 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Mon Jun 10 17:26:57 2019 - [info] GTID ON Mon Jun 10 17:26:57 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Mon Jun 10 17:26:57 2019 - [info] Primary candidate for the new Master (candidate_master is set) Mon Jun 10 17:26:57 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Mon Jun 10 17:26:57 2019 - [info] GTID ON Mon Jun 10 17:26:57 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Mon Jun 10 17:26:57 2019 - [info] Primary candidate for the new Master (candidate_master is set) Mon Jun 10 17:26:57 2019 - [error][/usr/local/share/perl5/MHA/MasterFailover.pm, ln310] Last failover was done at 2019/06/10 14:15:44. Current time is too early to do failover again. If you want to do failover, manually remove /etc/masterha//app1.failover.complete and run this script again. Mon Jun 10 17:26:57 2019 - [error][/usr/local/share/perl5/MHA/ManagerUtil.pm, ln177] Got ERROR: at /usr/local/bin/masterha_manager line 65.
报错:Current time is too early to do failover again,manually remove /etc/masterha/app1.failover.complete and run this script again
提示删除/etc/masterha//app1.failover.complete这个文件
[root@localhost scripts]# rm -rf /etc/masterha/app1.failover.complete [root@localhost scripts]#
再次启动MHA,再次模拟172.28.18.69主库mysql故障
[root@server-1 ~]# mysqladmin -uroot -p -S /home/mysql-5.7.26/run/mysql.sock shutdown Enter password: 2019-06-11T01:49:32.127585Z mysqld_safe mysqld from pid file /home/mysql-5.7.26/run/mysqld.pid ended [1]+ 完成 mysqld_safe --defaults-file=/etc/my.cnf --user=mysql
查看172.28.18.71上的manager.log日志
Tue Jun 11 09:49:22 2019 - [warning] Got error on MySQL select ping: 2013 (Lost connection to MySQL server during query) Tue Jun 11 09:49:22 2019 - [info] Executing secondary network check script: masterha_secondary_check -s 172.28.18.71 -s 172.28.18.69 -s 172.28.18.78 --user=root --master_host=172.28.18.69 --master_ip=172.28.18.69 --master_port=3306 --master_user=root --master_password=Zaq1xsw@ --ping_type=SELECT Tue Jun 11 09:49:22 2019 - [info] Executing SSH check script: exit 0 Tue Jun 11 09:49:23 2019 - [info] HealthCheck: SSH to 172.28.18.69 is reachable. Tue Jun 11 09:49:23 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.28.18.69' (111)) Tue Jun 11 09:49:23 2019 - [warning] Connection failed 2 time(s).. Monitoring server 172.28.18.71 is reachable, Master is not reachable from 172.28.18.71. OK. Monitoring server 172.28.18.69 is reachable, Master is not reachable from 172.28.18.69. OK. Tue Jun 11 09:49:24 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.28.18.69' (111)) Tue Jun 11 09:49:24 2019 - [warning] Connection failed 3 time(s).. Monitoring server 172.28.18.78 is reachable, Master is not reachable from 172.28.18.78. OK. Tue Jun 11 09:49:24 2019 - [info] Master is not reachable from all other monitoring servers. Failover should start. Tue Jun 11 09:49:25 2019 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '172.28.18.69' (111)) Tue Jun 11 09:49:25 2019 - [warning] Connection failed 4 time(s).. Tue Jun 11 09:49:25 2019 - [warning] Master is not reachable from health checker! Tue Jun 11 09:49:25 2019 - [warning] Master 172.28.18.69(172.28.18.69:3306) is not reachable! Tue Jun 11 09:49:25 2019 - [warning] SSH is reachable. Tue Jun 11 09:49:25 2019 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/masterha/app1.cnf again, and trying to connect to all servers to check server status.. Tue Jun 11 09:49:25 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Tue Jun 11 09:49:25 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Tue Jun 11 09:49:25 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Tue Jun 11 09:49:26 2019 - [info] GTID failover mode = 1 Tue Jun 11 09:49:26 2019 - [info] Dead Servers: Tue Jun 11 09:49:26 2019 - [info] 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:26 2019 - [info] Alive Servers: Tue Jun 11 09:49:26 2019 - [info] 172.28.18.71(172.28.18.71:3306) Tue Jun 11 09:49:26 2019 - [info] 172.28.18.78(172.28.18.78:3306) Tue Jun 11 09:49:26 2019 - [info] Alive Slaves: Tue Jun 11 09:49:26 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:26 2019 - [info] GTID ON Tue Jun 11 09:49:26 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:26 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:26 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:26 2019 - [info] GTID ON Tue Jun 11 09:49:26 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:26 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:26 2019 - [info] Checking slave configurations.. Tue Jun 11 09:49:26 2019 - [info] read_only=1 is not set on slave 172.28.18.71(172.28.18.71:3306). Tue Jun 11 09:49:26 2019 - [info] Checking replication filtering settings.. Tue Jun 11 09:49:26 2019 - [info] Replication filtering check ok. Tue Jun 11 09:49:26 2019 - [info] Master is down! Tue Jun 11 09:49:26 2019 - [info] Terminating monitoring script. Tue Jun 11 09:49:26 2019 - [info] Got exit code 20 (Master dead). Tue Jun 11 09:49:26 2019 - [info] MHA::MasterFailover version 0.58. Tue Jun 11 09:49:26 2019 - [info] Starting master failover. Tue Jun 11 09:49:26 2019 - [info] Tue Jun 11 09:49:26 2019 - [info] * Phase 1: Configuration Check Phase.. Tue Jun 11 09:49:26 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] GTID failover mode = 1 Tue Jun 11 09:49:28 2019 - [info] Dead Servers: Tue Jun 11 09:49:28 2019 - [info] 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Checking master reachability via MySQL(double check)... Tue Jun 11 09:49:28 2019 - [info] ok. Tue Jun 11 09:49:28 2019 - [info] Alive Servers: Tue Jun 11 09:49:28 2019 - [info] 172.28.18.71(172.28.18.71:3306) Tue Jun 11 09:49:28 2019 - [info] 172.28.18.78(172.28.18.78:3306) Tue Jun 11 09:49:28 2019 - [info] Alive Slaves: Tue Jun 11 09:49:28 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:28 2019 - [info] GTID ON Tue Jun 11 09:49:28 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:28 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:28 2019 - [info] GTID ON Tue Jun 11 09:49:28 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:28 2019 - [info] Starting GTID based failover. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] ** Phase 1: Configuration Check Phase completed. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] * Phase 2: Dead Master Shutdown Phase.. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] Forcing shutdown so that applications never connect to the current master.. Tue Jun 11 09:49:28 2019 - [info] Executing master IP deactivation script: Tue Jun 11 09:49:28 2019 - [info] /etc/masterha/scripts/master_ip_failover --orig_master_host=172.28.18.69 --orig_master_ip=172.28.18.69 --orig_master_port=3306 --command=stopssh --ssh_user=root --orig_master_ssh_port=25601 Unknown option: orig_master_ssh_port IN SCRIPT TEST====/usr/sbin/ifconfig em1:1 down==/usr/sbin/ifconfig em1:1 172.28.18.70/24=== Disabling the VIP on old master: 172.28.18.69 Tue Jun 11 09:49:28 2019 - [info] done. Tue Jun 11 09:49:28 2019 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. Tue Jun 11 09:49:28 2019 - [info] * Phase 2: Dead Master Shutdown Phase completed. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] * Phase 3: Master Recovery Phase.. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] * Phase 3.1: Getting Latest Slaves Phase.. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] The latest binary log file/position on all slaves is master.000006:194 Tue Jun 11 09:49:28 2019 - [info] Latest slaves (Slaves that received relay log files to the latest): Tue Jun 11 09:49:28 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:28 2019 - [info] GTID ON Tue Jun 11 09:49:28 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:28 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:28 2019 - [info] GTID ON Tue Jun 11 09:49:28 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:28 2019 - [info] The oldest binary log file/position on all slaves is master.000006:194 Tue Jun 11 09:49:28 2019 - [info] Oldest slaves: Tue Jun 11 09:49:28 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:28 2019 - [info] GTID ON Tue Jun 11 09:49:28 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:28 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:28 2019 - [info] GTID ON Tue Jun 11 09:49:28 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] * Phase 3.3: Determining New Master Phase.. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] Searching new master from slaves.. Tue Jun 11 09:49:28 2019 - [info] Candidate masters from the configuration file: Tue Jun 11 09:49:28 2019 - [info] 172.28.18.71(172.28.18.71:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:28 2019 - [info] GTID ON Tue Jun 11 09:49:28 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:28 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 09:49:28 2019 - [info] GTID ON Tue Jun 11 09:49:28 2019 - [info] Replicating from 172.28.18.69(172.28.18.69:3306) Tue Jun 11 09:49:28 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 09:49:28 2019 - [info] Non-candidate masters: Tue Jun 11 09:49:28 2019 - [info] Searching from candidate_master slaves which have received the latest relay log events.. Tue Jun 11 09:49:28 2019 - [info] New master is 172.28.18.71(172.28.18.71:3306) Tue Jun 11 09:49:28 2019 - [info] Starting master failover.. Tue Jun 11 09:49:28 2019 - [info] From: 172.28.18.69(172.28.18.69:3306) (current master) +--172.28.18.71(172.28.18.71:3306) +--172.28.18.78(172.28.18.78:3306) To: 172.28.18.71(172.28.18.71:3306) (new master) +--172.28.18.78(172.28.18.78:3306) Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] * Phase 3.3: New Master Recovery Phase.. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] Waiting all logs to be applied.. Tue Jun 11 09:49:28 2019 - [info] done. Tue Jun 11 09:49:28 2019 - [info] Getting new master's binlog name and position.. Tue Jun 11 09:49:28 2019 - [info] slave-71.000005:194 Tue Jun 11 09:49:28 2019 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.28.18.71', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx'; Tue Jun 11 09:49:28 2019 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: slave-71.000005, 194, d24d8a53-880d-11e9-b1f3-842b2b5cdc15:1-6, ee3e292b-866b-11e9-9df8-14feb5dc2c77:1-15 Tue Jun 11 09:49:28 2019 - [info] Executing master IP activate script: Tue Jun 11 09:49:28 2019 - [info] /etc/masterha/scripts/master_ip_failover --command=start --ssh_user=root --orig_master_host=172.28.18.69 --orig_master_ip=172.28.18.69 --orig_master_port=3306 --new_master_host=172.28.18.71 --new_master_ip=172.28.18.71 --new_master_port=3306 --new_master_user='root' --orig_master_ssh_port=25601 --new_master_ssh_port=25601 --new_master_password=xxx Unknown option: new_master_user Unknown option: orig_master_ssh_port Unknown option: new_master_ssh_port Unknown option: new_master_password IN SCRIPT TEST====/usr/sbin/ifconfig em1:1 down==/usr/sbin/ifconfig em1:1 172.28.18.70/24=== Enabling the VIP - 172.28.18.70/24 on the new master - 172.28.18.71 Tue Jun 11 09:49:28 2019 - [info] OK. Tue Jun 11 09:49:28 2019 - [info] ** Finished master recovery successfully. Tue Jun 11 09:49:28 2019 - [info] * Phase 3: Master Recovery Phase completed. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] * Phase 4: Slaves Recovery Phase.. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] * Phase 4.1: Starting Slaves in parallel.. Tue Jun 11 09:49:28 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] -- Slave recovery on host 172.28.18.78(172.28.18.78:3306) started, pid: 20990. Check tmp log /etc/masterha//172.28.18.78_3306_20190611094926.log if it takes time.. Tue Jun 11 09:49:35 2019 - [info] Tue Jun 11 09:49:35 2019 - [info] Log messages from 172.28.18.78 ... Tue Jun 11 09:49:35 2019 - [info] Tue Jun 11 09:49:28 2019 - [info] Resetting slave 172.28.18.78(172.28.18.78:3306) and starting replication from the new master 172.28.18.71(172.28.18.71:3306).. Tue Jun 11 09:49:29 2019 - [info] Executed CHANGE MASTER. Tue Jun 11 09:49:35 2019 - [info] Slave started. Tue Jun 11 09:49:35 2019 - [info] gtid_wait(d24d8a53-880d-11e9-b1f3-842b2b5cdc15:1-6, ee3e292b-866b-11e9-9df8-14feb5dc2c77:1-15) completed on 172.28.18.78(172.28.18.78:3306). Executed 0 events. Tue Jun 11 09:49:35 2019 - [info] End of log messages from 172.28.18.78. Tue Jun 11 09:49:35 2019 - [info] -- Slave on host 172.28.18.78(172.28.18.78:3306) started. Tue Jun 11 09:49:35 2019 - [info] All new slave servers recovered successfully. Tue Jun 11 09:49:35 2019 - [info] Tue Jun 11 09:49:35 2019 - [info] * Phase 5: New master cleanup phase.. Tue Jun 11 09:49:35 2019 - [info] Tue Jun 11 09:49:35 2019 - [info] Resetting slave info on the new master.. Tue Jun 11 09:49:35 2019 - [info] 172.28.18.71: Resetting slave info succeeded. Tue Jun 11 09:49:35 2019 - [info] Master failover to 172.28.18.71(172.28.18.71:3306) completed successfully. Tue Jun 11 09:49:35 2019 - [info] ----- Failover Report ----- app1: MySQL Master failover 172.28.18.69(172.28.18.69:3306) to 172.28.18.71(172.28.18.71:3306) succeeded Master 172.28.18.69(172.28.18.69:3306) is down! Check MHA Manager logs at localhost.localdomain:/etc/masterha/manager.log for details. Started automated(non-interactive) failover. Invalidated master IP address on 172.28.18.69(172.28.18.69:3306) Selected 172.28.18.71(172.28.18.71:3306) as a new master. 172.28.18.71(172.28.18.71:3306): OK: Applying all logs succeeded. 172.28.18.71(172.28.18.71:3306): OK: Activated master IP address. 172.28.18.78(172.28.18.78:3306): OK: Slave started, replicating from 172.28.18.71(172.28.18.71:3306) 172.28.18.71(172.28.18.71:3306): Resetting slave info succeeded. Master failover to 172.28.18.71(172.28.18.71:3306) completed successfully.
此时日志显示主库172.28.18.69故障,将172.28.18.71升级为主库,将VIP172.28.18.70漂移到172.28.18.71上
在172.28.18.71上查看IP
[root@localhost scripts]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 84:2b:2b:5c:dc:15 brd ff:ff:ff:ff:ff:ff inet 172.28.18.71/28 brd 172.28.18.79 scope global noprefixroute em1 valid_lft forever preferred_lft forever inet 172.28.18.70/24 brd 172.28.18.255 scope global em1:1 valid_lft forever preferred_lft forever inet6 fe80::e0b8:7d61:e043:692/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: em2: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:17 brd ff:ff:ff:ff:ff:ff 4: em3: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:19 brd ff:ff:ff:ff:ff:ff 5: em4: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 84:2b:2b:5c:dc:1b brd ff:ff:ff:ff:ff:ff 6: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0
IP 已经漂移,在172.28.18.69上查看IP
[root@server-1 ~]# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 14:fe:b5:dc:2c:77 brd ff:ff:ff:ff:ff:ff inet 172.28.18.69/28 brd 172.28.18.79 scope global noprefixroute em1 valid_lft forever preferred_lft forever inet6 fe80::b3e8:e3b2:2242:a2ed/64 scope link noprefixroute valid_lft forever preferred_lft forever 3: em2: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 14:fe:b5:dc:2c:79 brd ff:ff:ff:ff:ff:ff 4: em3: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 14:fe:b5:dc:2c:7b brd ff:ff:ff:ff:ff:ff 5: em4: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc mq state DOWN group default qlen 1000 link/ether 14:fe:b5:dc:2c:7d brd ff:ff:ff:ff:ff:ff
VIP已经删除
十四、将故障服务器重新启动加入集群
1、首先启动故障服务器的MYSQL
[root@server-1 ~]# mysqld_safe --defaults-file=/etc/my.cnf --user=mysql & [1] 32453 [root@server-1 ~]# 2019-06-11T02:09:02.264893Z mysqld_safe Logging to '/home/mysql-5.7.26/log/mysqld.log'. 2019-06-11T02:09:02.317370Z mysqld_safe Starting mysqld daemon with databases from /home/mysql-5.7.26/data
2、手动设置将172.28.18.69故障服务器的mysql作为新的主库172.28.18.71的从库
首先在172.28.18.71上的MHA日志 manager.log里查找CHANGE 语句
[root@localhost ~]# cat /etc/masterha/manager.log |grep CHANGE Tue Jun 11 09:49:28 2019 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='172.28.18.71', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx'; Tue Jun 11 09:49:29 2019 - [info] Executed CHANGE MASTER. [root@localhost ~]#
在172.28.18.69上的mysql里执行上面的语句使172.28.18.69成为172.28.18.71的从库
mysql> CHANGE MASTER TO MASTER_HOST='172.28.18.71', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxxxxxxx'; ERROR 2006 (HY000): MySQL server has gone away No connection. Trying to reconnect... Connection id: 2 Current database: test Query OK, 0 rows affected, 2 warnings (0.16 sec) mysql> start slave; Query OK, 0 rows affected (0.01 sec)
查看从库状态
mysql> show slave statusG; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.28.18.71 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: slave-71.000005 Read_Master_Log_Pos: 194 Relay_Log_File: server-1-relay-bin.000002 Relay_Log_Pos: 365 Relay_Master_Log_File: slave-71.000005 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 194 Relay_Log_Space: 575 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 71 Master_UUID: d24d8a53-880d-11e9-b1f3-842b2b5cdc15 Master_Info_File: /home/mysql-5.7.26/data/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: d24d8a53-880d-11e9-b1f3-842b2b5cdc15:1-6, ee3e292b-866b-11e9-9df8-14feb5dc2c77:1-15 Auto_Position: 1 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: 1 row in set (0.00 sec) ERROR: No query specified
此时,已经成为172.28.18.71的从库了
3、将172.28.18.71上的MHA启动
因为MHA在做故障切换后,会自动退出,所以每次故障恢复后,需要重新启动MHA
[root@localhost ~]# masterha_manager --conf=/etc/masterha/app1.cnf & [2] 22275 [1] 完成 masterha_manager --conf=/etc/masterha/app1.cnf [root@localhost ~]# Tue Jun 11 10:15:25 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Tue Jun 11 10:15:25 2019 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Tue Jun 11 10:15:25 2019 - [info] Reading server configuration from /etc/masterha/app1.cnf..
查看MHA状态
[root@localhost ~]# masterha_check_status --conf=/etc/masterha/app1.cnf & [3] 22318 [root@localhost ~]# app1 (pid:22275) is running(0:PING_OK), master:172.28.18.71
运行中,再查看manager.log日志
Tue Jun 11 10:15:25 2019 - [info] MHA::MasterMonitor version 0.58. Tue Jun 11 10:15:30 2019 - [info] GTID failover mode = 1 Tue Jun 11 10:15:30 2019 - [info] Dead Servers: Tue Jun 11 10:15:30 2019 - [info] Alive Servers: Tue Jun 11 10:15:30 2019 - [info] 172.28.18.71(172.28.18.71:3306) Tue Jun 11 10:15:30 2019 - [info] 172.28.18.69(172.28.18.69:3306) Tue Jun 11 10:15:30 2019 - [info] 172.28.18.78(172.28.18.78:3306) Tue Jun 11 10:15:30 2019 - [info] Alive Slaves: Tue Jun 11 10:15:30 2019 - [info] 172.28.18.69(172.28.18.69:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 10:15:30 2019 - [info] GTID ON Tue Jun 11 10:15:30 2019 - [info] Replicating from 172.28.18.71(172.28.18.71:3306) Tue Jun 11 10:15:30 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 10:15:30 2019 - [info] 172.28.18.78(172.28.18.78:3306) Version=5.7.26-log (oldest major version between slaves) log-bin:enabled Tue Jun 11 10:15:30 2019 - [info] GTID ON Tue Jun 11 10:15:30 2019 - [info] Replicating from 172.28.18.71(172.28.18.71:3306) Tue Jun 11 10:15:30 2019 - [info] Primary candidate for the new Master (candidate_master is set) Tue Jun 11 10:15:30 2019 - [info] Current Alive Master: 172.28.18.71(172.28.18.71:3306) Tue Jun 11 10:15:30 2019 - [info] Checking slave configurations.. Tue Jun 11 10:15:30 2019 - [info] read_only=1 is not set on slave 172.28.18.69(172.28.18.69:3306). Tue Jun 11 10:15:30 2019 - [info] Checking replication filtering settings.. Tue Jun 11 10:15:30 2019 - [info] binlog_do_db= , binlog_ignore_db= Tue Jun 11 10:15:30 2019 - [info] Replication filtering check ok. Tue Jun 11 10:15:30 2019 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. Tue Jun 11 10:15:30 2019 - [info] Checking SSH publickey authentication settings on the current master.. Tue Jun 11 10:15:31 2019 - [info] HealthCheck: SSH to 172.28.18.71 is reachable. Tue Jun 11 10:15:31 2019 - [info] 172.28.18.71(172.28.18.71:3306) (current master) +--172.28.18.69(172.28.18.69:3306) +--172.28.18.78(172.28.18.78:3306) Tue Jun 11 10:15:31 2019 - [info] Checking master_ip_failover_script status: Tue Jun 11 10:15:31 2019 - [info] /etc/masterha/scripts/master_ip_failover --command=status --ssh_user=root --orig_master_host=172.28.18.71 --orig_master_ip=172.28.18.71 --orig_master_port=3306 --orig_master_ssh_port=25601 Unknown option: orig_master_ssh_port IN SCRIPT TEST====/usr/sbin/ifconfig em1:1 down==/usr/sbin/ifconfig em1:1 172.28.18.70/24=== Checking the Status of the script.. OK 2: em1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 84:2b:2b:5c:dc:15 brd ff:ff:ff:ff:ff:ff inet 172.28.18.71/28 brd 172.28.18.79 scope global noprefixroute em1 valid_lft forever preferred_lft forever inet 172.28.18.70/24 brd 172.28.18.255 scope global em1:1 valid_lft forever preferred_lft forever inet6 fe80::e0b8:7d61:e043:692/64 scope link noprefixroute valid_lft forever preferred_lft forever Tue Jun 11 10:15:31 2019 - [info] OK. Tue Jun 11 10:15:31 2019 - [warning] shutdown_script is not defined. Tue Jun 11 10:15:31 2019 - [info] Set master ping interval 1 seconds. Tue Jun 11 10:15:31 2019 - [info] Set secondary check script: masterha_secondary_check -s 172.28.18.71 -s 172.28.18.69 -s 172.28.18.78 Tue Jun 11 10:15:31 2019 - [info] Starting ping health check on 172.28.18.71(172.28.18.71:3306).. Tue Jun 11 10:15:31 2019 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
172.28.18.71(172.28.18.71:3306) (current master) +--172.28.18.69(172.28.18.69:3306) +--172.28.18.78(172.28.18.78:3306)
此时172.28.18.71为新的主库,172.28.18.69、172.28.18.78为从库