1.hadoop环境搭建成功以后 用hadoop下自带的示例对hadoop进行了测试
创建a.txt文件 并输入如下内容:
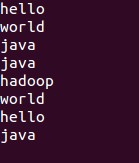
2.进入到Hadoop路径下将该文件复制到hadoop分布式文件系统下
bin/hadoop fs -copyFromLocal usr/data/a.txt /data/
3.执行hadoop自带的examples示例
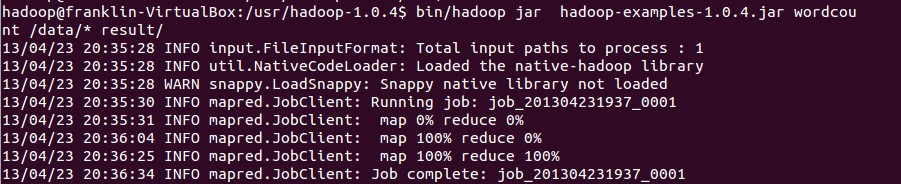
bin/hadoop jar hadoop-examples-1.0.4.jar wordcount /data/* result/
/data/* 指定wordcount进行分析的文件的路径 result/指定分析结构的输出路径
通过localhost:50070可以看到jobtracker运行的状态 以及map和reduce进行的进度
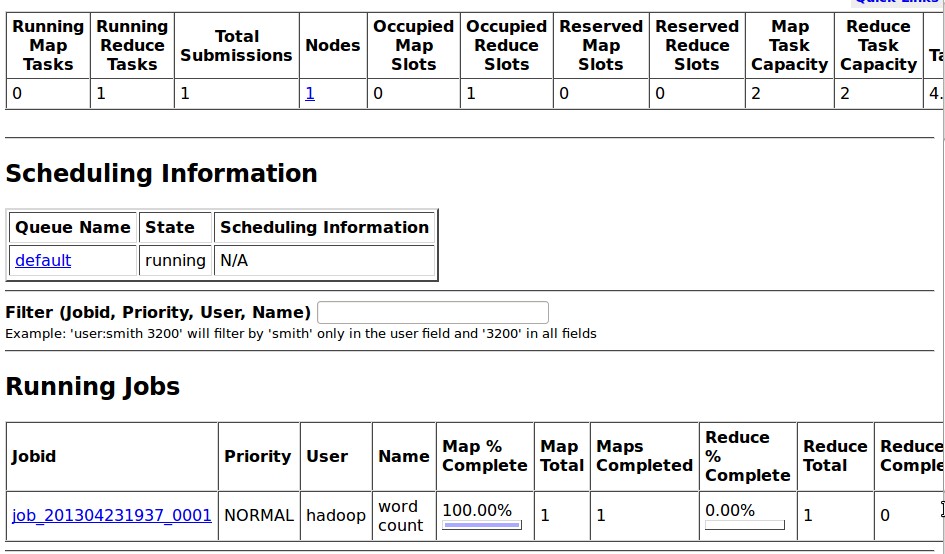
任务成功结束
在hadoop文件系统下可以看到输出的结果:

