目的:通过fiddler在电脑上对手机版斗鱼主播进行抓包,爬取所有主播的昵称和图片链接
关于使用fiddler抓取手机包的设置:
把手机和装有fiddler的电脑处在同一个网段(同一个wifi),手机连接好wifi后,点击手机wifi的连接,把代理改为手动,主机地址设置为fiddler所在的电脑ip,端口号为8888(fiddler默认使用的端口号),就可以对手机进行抓包
1 创建爬虫项目douyumeinv
scrapy startproject douyumeinv
2 设置items.py文件,对要爬取数据设置字段名字及类型进行保存
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DouyumeinvItem(scrapy.Item):
# 主播昵称
nickname = scrapy.Field()
# 主播房间的图片链接
roomSrc = scrapy.Field()
# 照片在本地保存的位置
imagesPath = scrapy.Field()
3 在spiders文件夹内创建爬虫文件douyuspider.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from douyumeinv.items import DouyumeinvItem
import json
class DouyuSpider(scrapy.Spider):
# 爬虫名字,终端执行命令时使用。如scrapy crawl douyu
name = 'douyu'
# 指定爬取的域范围
allowed_domains = ['douyu.com']
# 要爬取的页码
num = 1
# 主播个数
n = 0
# 实际有主播的页码
pageCount = 0
url = 'https://m.douyu.com/api/room/mixList?page=' + str(num) + '&type=qmxx'
# 爬取的url列表
start_urls = [url]
def parse(self, response):
'''解析函数'''
# 把获取的json数据转换为python字典
data = json.loads(response.text)['data']
# 获取实际具有主播的页码
self.pageCount = int(data['pageCount'])
for each in data['list']:
self.n += 1
item = DouyumeinvItem()
# 主播房间图片链接
item['roomSrc'] = each['roomSrc'].encode('utf-8')
# 主播昵称
item['nickname'] = each['nickname'].encode('utf-8')
# print(item)
# 返回数据给管道
yield item
# 重新发送请求
self.num += 1
# 只对有主播的页码,进行发送请求
if self.num <= self.pageCount:
self.url = 'https://m.douyu.com/api/room/mixList?page=' + str(self.num) + '&type=qmxx'
yield scrapy.Request(self.url, callback=self.parse)
print '
已爬完第%d页,共%d页,共爬取%d个主播
'%(self.num - 1,self.pageCount,self.n)
4 设置pipelines.py管道文件,利用images.ImagesPipeline类来请求图片链接并处理下载好的图片
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# class DouyumeinvPipeline(object):
# def process_item(self, item, spider):
# return item
import scrapy
from scrapy.pipelines import images
from scrapy.utils.project import get_project_settings
import os
class DouyumeinvPipeline(object):
def process_item(self, item, spider):
return item
class ImagesPipeline(images.ImagesPipeline):
images_store = get_project_settings().get('IMAGES_STORE')
# count用来统计实际下载并改名成功的图片个数
count = 0
def get_media_requests(self, item, info):
'''
get_media_requests的作用就是为每一个图片链接生成一个Request对象,这个方法的输出将作为item_completed的输入中的results
'''
# return [Request(x) for x in item.get(self.images_urls_field, [])]
image_url = item['roomSrc']
# print('='*60)
# print(image_url)
# print(item['nickname'])
# print('='*60)
yield scrapy.Request(image_url)
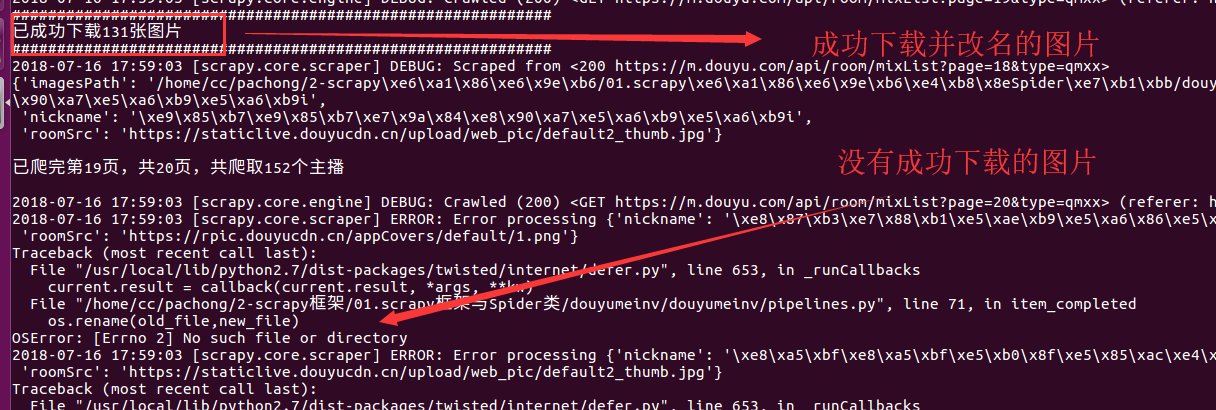
def item_completed(self, results, item, info):
# results是一个元组,每个元组包括(success, imageinfoorfailure)。
# 如果success=true,imageinfoor_failure是一个字典,包括url/path/checksum三个key。
image_path = [x["path"] for ok,x in results if ok]
# print('*'*60)
# 由于yield的原因,image_path的值为每次输出一个列表['full/0c1c1f78e7084f5e3b07fd1b0a066c6c49dd30e0.jpg']
# print(image_path[0])
# print(item['nickname'])
# print('*'*60)
# 此处发现,不用再创建相应的文件夹,直接使用下面的字符串拼接,就可以生成一个文件夹
old_file = self.images_store + '/' + image_path[0]
new_file = self.images_store + '/full/' + item['nickname'] + '.jpg'
# print('
' + '-'*60)
# print(old_file)
# print(new_file)
# print('
')
# print(os.path.exists(old_file))
# 判断该文件及路径是否存在
# 如果图片下载成功,则计数加1
if os.path.exists(old_file):
self.count += 1
# print('
')
# print('-'*60 + '
')
os.rename(old_file,new_file)
item['imagesPath'] = self.images_store + '/full/' + item['nickname']
# print(os.listdir('/home/cc/pachong/2-scrapy框架/01.scrapy框架与Spider类/douyumeinv/douyumeinv/images/full/'))
print('#'*60)
print('已成功下载%d张图片'%(self.count))
print('#'*60)
return item
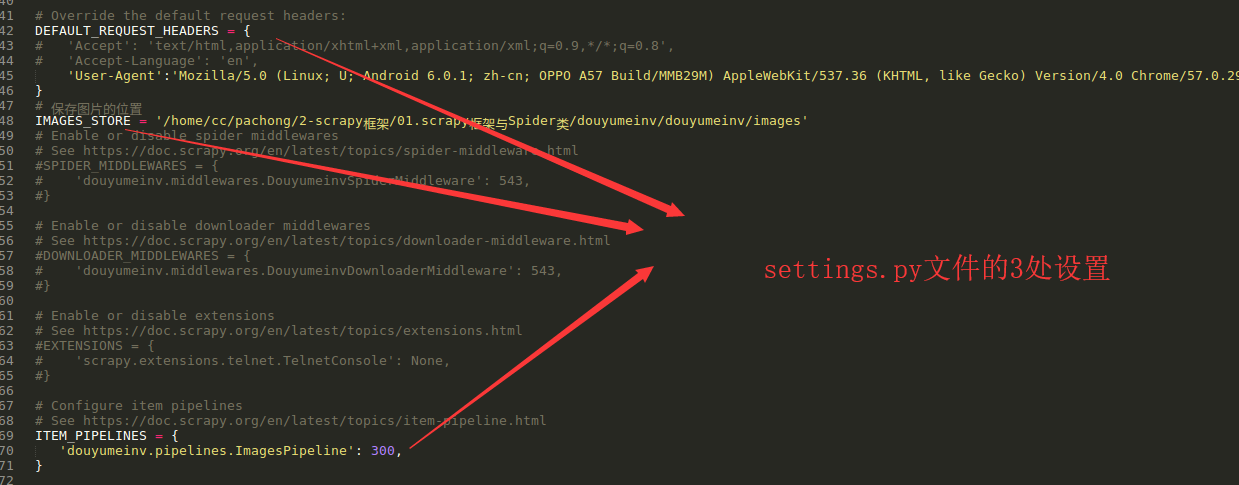
5 设置settings.py文件
6 测试结果如下: