TensorFlow——CNN实现MNIST手写体识别
文章目录
TensorFlowCNN实现MNIST
官方文档 —— MNIST 入门 | Softmax 相关
官方文档 —— MNIST 进阶 | CNN 相关
CNN-卷积神经网络相关
1,数据集
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片: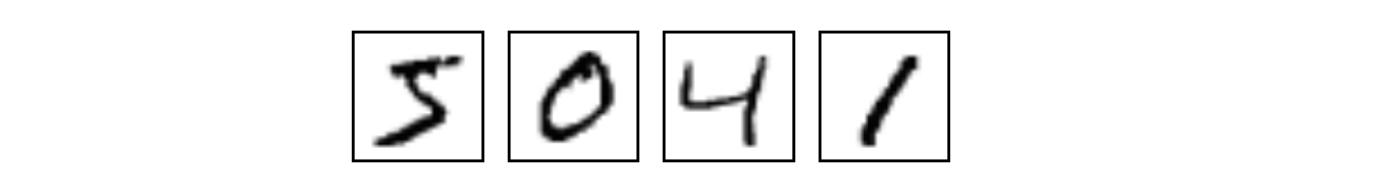
这份Python代码是官方网站上提供给我们下载和安装数据集的,然后可以使用下面的代码导入到你的项目里面:
import input_data
mnist = input_data.read_data-sets("MNIST_data/", one_hot=True)
- 1
- 2
下载下来是一个60000行的训练数据集(mnist.train)和一个10000行的测试数据集(mnist.test)。
数据集的每个数据单元包含:
- 一张手写数字的图片(28x28=784)
- 对应的标签[1x10]
在训练数据集中,mnsit.train.images是一个形状为[60000, 784]的一个张量,第一个维度是图片索引也就是样本序号,第二个维度是图片像素点,也就是相对于每张28x28=784的图片转换为一个1x784的向量来处理,总共是60000x784。
对用的标签是介于0到9的数字,用一个向量表示,例如0的标签为:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],也就是第0位为1,其他为0的1x10的向量,来表示标签0。因此mnist.train.labels是一个[60000, 10]的张量
2,回归模型——Softmax
我们针对每个数字,给出每个数字对应的28x28=784个像素不同的权值,与这个数字相关程度较大的像素,我们给予相对更高的权重(正值),反之给予较低的权重(负值),如下图所示,红色为负值,蓝色为正值,黑色表示我们对这部分像素不关心:
对每一张图片,根据相应的数字 iii 所对应的每个像素xjx_{j}xj的权重Wi, jW_{i, j}Wi, j,求出乘积和在加上一个偏置量(因为输入往往会有干扰),得到一个证据值,它描述的是我们能够认为这张图片是对应数字 iii 的把握的大小:
evidencei=∑jWi, jxj+bi(0)evidence_{i} = sum_{j}W_{i, j}x_{j} + b_{i} ag{0}evidencei=j∑Wi, jxj+bi(0)
我们更希望得到的是这张图片关于0-9每个数字的概率分布。我们通过softmax这个激励函数把这个证据量转化为对应数字 iii 一个概率值yiy_{i}yi:
yi=softmax(evide