大数据文摘出品
来源:Medium
编译:李雷、橡树_Hiangsug
文章解释了转型为数据科学家的原因,整理了数据科学家应该掌握的技能,着重介绍了从数据分析师转型为数据科学家的具体方法。
如何从数据分析师华丽转型,成为一名数据科学家?好比“把大象装进冰箱”,成为“数据科学家”仅需简单三步:
1. 进入LinkedIn登录你的账号。
2. 点击“编辑个人资料”。
3. 将 “数据分析师”这个词替换为“数据科学家”。
搞定,就是这么简单!
理想很丰满,现实很骨感。在现实生活中,我们必须承认:培养数据洞察能力绝非易事。
入门数据科学早已有许多优秀的博文可供参考,比如以下两篇:《成为Jet.com数据分析师的自学之路》和《入门数据科学需掌握的基础知识》,但是为数据分析师提供转型为数据科学家的方法的文章却少之又少。
《成为Jet.com数据分析师的自学之路》:
https://medium.freecodecamp.org/a-path-for-you-to-learn-analytics-and-data-skills-bd48ccde7325
《入门数据科学需掌握的基础知识》:
https://medium.freecodecamp.org/aspiring-data-scientist-master-these-fundamentals-be7c54350868
《尚学堂大数据课程》:
大数据学习视频:https://www.shsxt.com/dashujushipin/
可以免费获取优秀的大数据学习视频,还有尚学堂培训课程免费学习机会
在我开始介绍这条转型之路前,我还是想先花些功夫详细描述一下这两种职业身份的具体职责。

数据分析师的主要工作是对数据进行收集和处理,并通过统计算法分析已处理的结构化数据,从而为数据赋能,改良决策。
数据科学家也会进行类似的工作,但对其提出了更高的要求。除上述职责外,一个优秀的数据科学家需要同时具备处理大量非结构化数据的能力,甚至拥有对数据进行实时处理的能力。
他们不仅可以洞悉数据背后的价值,还会对数据进行更深度的清洗和处理,并且用各种各样的高级算法对数据进行更深层的分析。除此之外,他们还具有很强的叙事能力和数据可视化能力。
我经常会接触到许多才华横溢的分析师,他们急切地想要在数据科学界大展拳脚,却总是找不合适的机会,甚至不知从何入手——而这正是我写下这篇文章的主要原因。
为什么要成为数据科学家?
影响力:成为一名数据科学家意味着你将有机会发现和创造巨大的商业价值,发表更高层的决策意见,甚至帮助企业寻找未来的发展方向。
成就感:数据科学是一个飞速发展的领域,其中有许多有趣的问题亟待解决。作为一名数据科学家,你可以建立图像识别系统,开发文本分类器,识别社交媒体上的恶意评价,投身解决一系列尚未攻克的难题。
前沿性:曾有人预言,人工智能将最终取代人类工作。与其等着自己的工作被人工智能取代,不如主动出击,追上这一时代的浪潮。
薪酬待遇:也许数据科学家的薪酬还不足以让你享受开游艇喝香槟的奢靡生活,但相较于其他工作已经相当可观。业界对数据科学家的需求量依旧较大,优秀的数据科学家仍属高薪稀缺人才。直白来讲,为了更好的明天,努力成为一名优秀的数据科学家吧!

数据科学——学得多,做得多,但赚得也多!
友情提示:量力而行,切忌盲从,不要被金钱和诱惑蒙蔽了双眼,毕竟贪得无厌没有好结果(“华尔街之狼”的下场很惨)。
我是否拥有成为数据科学家的资质?
尽管培养处理棘手的数据结构和(或)大型数据的能力需要数年的经验积累,但别灰心,实际上大多数分析师在一定程度上已经打下了成为数据科学家的基础。换句话说,只要肯下功夫,转型为数据科学家没有想象中那么困难。
那么,成为一名合格的数据科学家到底需要掌握哪些技能?
一个复杂的数据科学项目可能由众多子项目构成,且项目流程又复杂多变,所以我们恐怕没有办法找到这个问题的标准答案。单就近几年数据科学的发展来看,成为一名数据科学家至少需要了解以下几个方面的技能分支:
-
数据科学语言:Python / R。
-
关系型数据库 :MySQL,Postgress。
-
非关系型数据库:MongoDB。
-
机器学习模型:回归算法(Regression)、提升决策树(Boosted Trees)、支持向量机(SVM)、神经网络(NNs)等。
-
图像处理:Neo4J,GraphX
-
分布式计算:Hadoop,Spark
-
云计算 :GCP / AWS / Azure
-
API 交互:OAuth,Rest
-
数据可视化和Web应用:D3,RShiny
-
专业领域:自然语言处理(NLP),光学字符识别(OCR)和计算机视觉(CV)
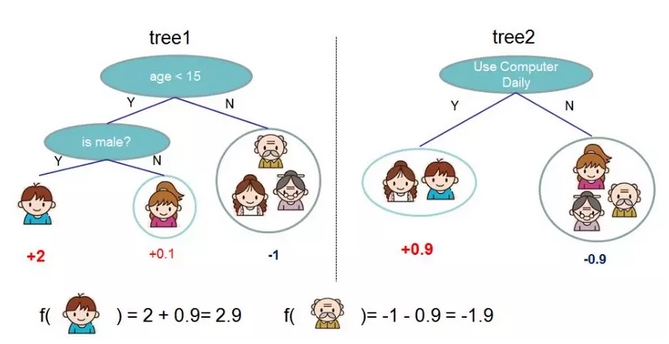
Boosted Trees模型在近几年的数据科学竞赛中大放异彩。
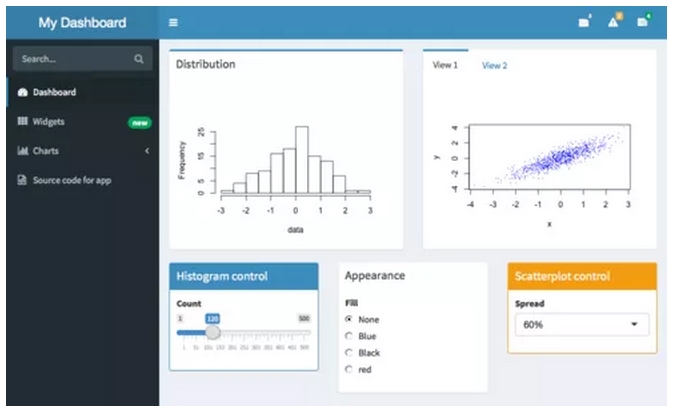
RShiny数据仪表盘是一个优秀的交互工具,可供用户更加直观地对数据进行探索。
掌握这些技能需要很长时间(可能比完成学位课程的时间还要长),即使是为我们熟知的“牛人”们仍在不断地学习。但是,我们大可不必担心自己能力有限,学习知识需要一步步的积累,掌握技能需要一步步的打磨。每天进步一点,总有一天我们将拥有足够丰富的知识储备和高水平的技能迎接未来的挑战。
智力水平的高低无法决定我们是否可以获得成功,坚定的决心和顽强的意志才是通往成功的关键所在。
我具体应该怎么做?
在开始行动前,我们需要掌握一些基本的技能:
树立正确的信念。或许在十年前,找到一门合适的数据软件课程可能需要花费数周之久,但时代已变,线上学习材料触手可及,资源匮乏再也不是逃避学习的借口。我们必须保持持续学习的能力,不断为自己充电,磨练自己的技术。
学习一门编程语言并提升你的数学能力。大多数人都是从学习Python和(或)R开始数据科学之路的,而且Coursera和Udemy等网站上提供了大量相关的免费课程资源。Python用户喜欢通过Anaconda和Jupyter编程,而R用户则较多地使用R Studio。就数学计算能力而言,吴恩达(Andrew Ng)的机器学习课程和斯坦福大学的神经网络课都很适合于转型人士学习。
动手解决问题。你可以尝试在工作中找到所遇到的实际问题,与业务专家和数据工程师展开合作,亲自动手解决这些问题——这是最好的端到端开发模式。
参加Kaggle比赛。还有什么比与数千人同台竞赛更能提升建模技巧呢?Kaggle上的比赛要求十分清晰,提供的数据都已经过清洗,非常值得一试。刚开始不要太在意比赛的排名,以尝试的心态开始你的第一场比赛——每一次尝试都是新的开始。
紧随领军人物的动态。有些人喜欢把为这一领域做出杰出贡献的人比作“数据科学界的摇滚巨星”,他们的言行和工作非常值得你花时间去了解和学习——时常刷新Geoffrey Hinton,Andrew Ng,Yann LeCun,Rachel Thomas和Jeremy Howard等人的动态,你肯定会有所收获。
高效地工作。在一定工作积累后,尝试借助工具提升你的工作效率——使用GitHub等版本控制工具维护和储存你的代码,用Docker对你的代码进行封装与发布。
有效地沟通。学会“推销”自己的工作。高管们总是喜欢“华丽”的项目展示,所以当你在做重要的工作报告时要努力“博眼球”,突出工作的亮点。
Twitter也是另一种获取信息的媒介,Rachel Thomas等人的动态十分值得关注。
为自己铺路
即使你掌握了世界上所有的技能,如果你的公司无法提供合适的开发工具,配置相应的开发环境,你也很难施展拳脚。
现实生活中总会有一些不可控的因素阻碍我们前进的脚步,与其浪费时间纠结于此,我们更加应该关注那些我们可以改变的因素并积极做出行动。
加入新的团队,这是最简单可行的转型方法。大多数中到大型的公司都至少会有一个小型数据科学团队——别犹豫,加入他们!
与专业人士合作,如果你无法“跳槽”,那么就请想方设法找到在你认识范围内知识最渊博的数据科学家并与之合作。
举例来说,你可以在现有的工作中找到可自动化完成的业务流程,然后带着这一问题找到这方面的专家。但这时千万不要直接把任务“甩”给这些专家,尝试与他们合作,加入到问题的解决过程中来。
搭建数据科学的内部环境,并不是所有的公司都确定它们是否需要数据科学的帮助,或者他们并不知道如何引入数据科学作为分析工具。
传统的分析系统已经让他们忙得不可开交,且开发新数据分析系统所带来的安全和审计任务都相当耗时,因此他们只接受效益明显的商业应用方案——这就是你大显身手的机会,用你的知识储备为公司搭建数据科学发展环境,引入合适的数据科学工具,培养内部人员的数据思维,为数据科学团队储备力量。
开发一个明确的业务用例,你可以重新审视业务流程,思考如何将数据科学应用到这些业务中,想办法将数据科学与业务完美融合,借助业务应用的成功案例为数据科学的后续发展铺路。
与有更多技能的人合作,加入多元化的团队不仅可以帮助你更容易获得更大的成就,你还可以在合作过程中学习到其他成员掌握的知识和拥有的技能。
尾记
种一棵树最好的时间是十年前,其次是现在。珍惜这次机会,马上开始你的学习之路,从实际问题入手,步步攻克一系列难关。开弓没有回头箭,你必须不断努力,将全部的信心和热情投入到工作中,你会惊讶地发现原来自己也可以获得如此高的成就!