作者提出了一种对抗样本生成算法TEXTFOOLER。
论文中,作者使用这种方法,对文本分类与文本蕴含两种任务做了测试,成功的攻击了这两种任务的相关模型,包括:BERT,CNN,LSTM,ESIM等等。
问题定义
一个有效的样本:和原样本近似。
给定文本x,以及训练好的模型F,F(x)=y,一个有效的对抗样本要满足:
![]()
其中是相似度函数,值域在[0,1],是最小相似度阈值。
TEXTFOOLER
论文的设定是黑盒模型,也就是说不知道模型的结构、参数、训练数据,能够知道的就是,输入文本给模型然后得到输出标签以及相关置信度得分。
论文中生成对抗样本主要包含两个步骤:词语重要性排序,词语转换。

因为是黑盒,作者通过这种方式来算重要性。其中,Xwi = {w1, . . . , wi−1, wi+1, . . . wn}, 就是去掉wi这个词,观察去掉wi前后的分数置信度的变化程度。
在过滤停用词时,去掉了the when more这种,使用的是NLTK2 和 spaCy3 库。
词语转换
论文作者认为,一个好的词语转换机制需要满足3个条件:
跟原词有相近的语义,
跟上下文比较融洽,
能让模型做出错误的预测。
同义词提取:论文作者根据【1】中的词向量,获取所有跟词wi最接近的N个且consine相似度大于一个阈值的词,以此作为候选词。N与阈值的大小都会影响到候选词的数量,论文实验中,将N设置为50,阈值设置为0.7。
词性检查:在候选词中,只保留与wi词性相同的词。
语义相似度检查:使用候选词中每个词替换原词wi,得到对抗样本x adv,论文使用UES【2】将句子编码向量化,然后计算与原句子向量之间的consine相似度,如果相似度大于阈值,则保留这个候选词。
获取对抗样本:如果还有候选词,且存在候选词改动后的样本使得模型预测标签与原标签不一致,那么选择语义相似度最大的一个词生成对抗样本;否则,我们选择一个词,其改变之后让模型对原标签的置信度最低,将原词替换为此词,并根据重要性排序选择下一个词重复第二步(词语转换)。

根据算法生成的对抗样本示例:
语义相似度还是挺高的。
实验
实验选择了两种文本任务:文本分类,文本蕴含,使用的相关数据集为:
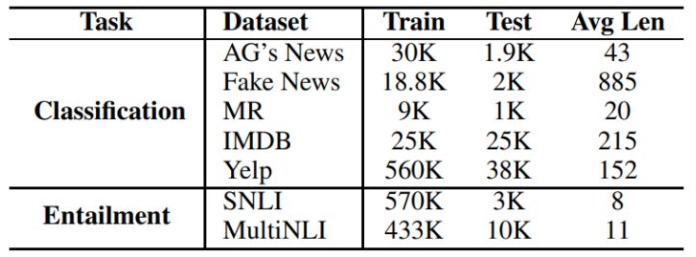
实验中分别为两个任务选择了三个模型,模型的原始准确率如下:

结果
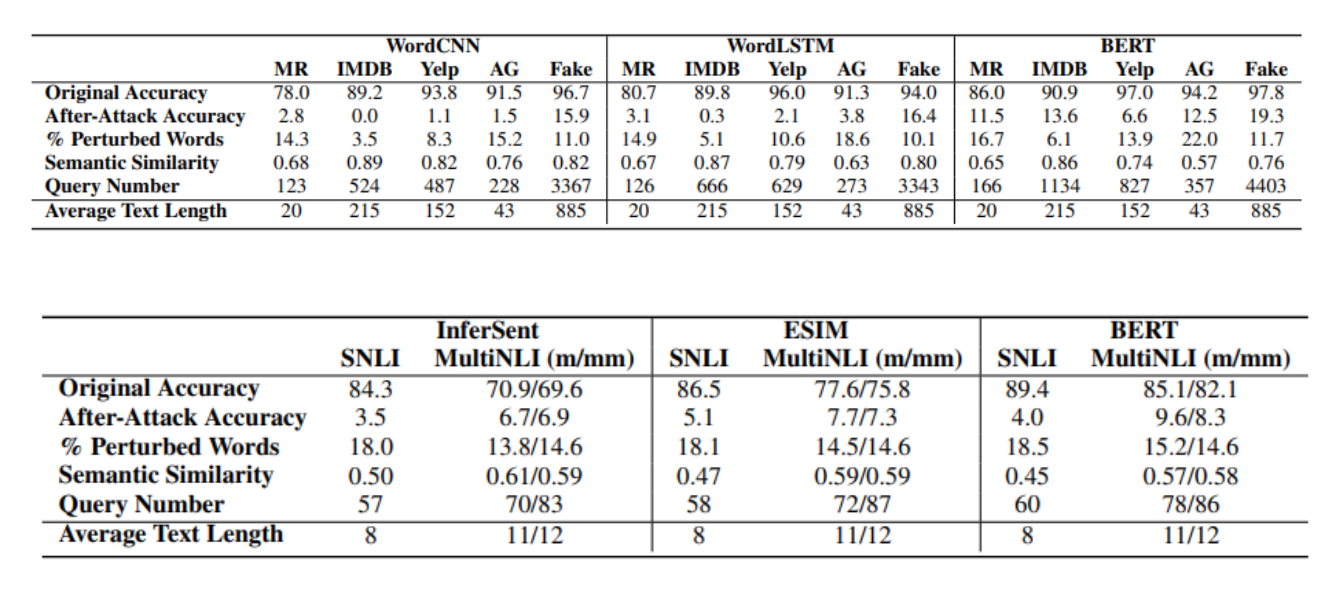
其中Original Accuracy表示原测试集准确性,After-Attack Accuracy表示对抗样本的准确性,% Perturbed Words表示对抗样本与原样本相比扰动的比例,Semantic Similarity表示对抗样本与原样本的相似度,Query Number表示使用模型F的次数(论文中未明确说明),m/mm中m表示匹配mm表示不匹配。
论文中结论显示,成功地攻击了两种文本任务,使用低于20%的扰动率,将模型的准确率降低到15%以下;且观察到一个简单结果:模型的准确率越高,就越难被攻击。
降低了好多。
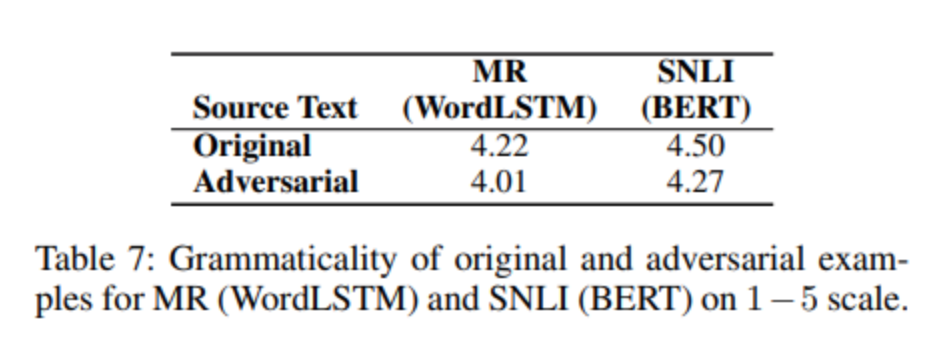
人工评价:
论文作者随机抽取了MR与SNLI个100个对抗样本,进行人工评价(1-5分),结果表明对抗样本与原样本在语法上相近,绝大部分情况都有相同的属性,且他们之间的感知差异较小。
讨论分析
可迁移性
论文作者使用一个模型生成的对抗样本去测试另外一个模型,结果表明这样生成的样本也会使其他模型一定程度上降低准确性。
对抗训练
论文中使用生成的对抗样本与原训练集一起重新训练模型,结果表明新得到的模型比原模型更难收到攻击,具有更好的鲁棒性。
错误分析
论文作者认为,他们的对抗样本容易收到三种类型的错误影响:词义歧义,语法错误,任务敏感的内容变换。
总结
在黑盒模型的情况下,以及在文本分类和文本蕴含任务中,该论文成功进行了对当前最优的模型的对抗攻击。实验表明,该论文提出的TEXTFOOLER方法能够生成有效的对抗样本,并且大部分都是人类易读的,且语法与语义上与原文本相似。
论文之外
在实际工作中,使用bert类模型做中文文本分类与文本蕴含任务的时候,也遇到了模型鲁棒性的问题,增加或删除一个字词,甚至只是一个标点符号,都可能会改变模型最终结果,这种修改导致模型结果不一致的可能性大概在3-4%(作者的任务中)。反过来说,如果解决这种及其微小扰动的鲁棒性问题,是不是直接可以提升模型准确率3-4个点?
论文也给了代码,感觉很棒棒,之后想用在比赛中的对抗训练中试一试!