MapReduce采用的是“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个从节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单来说,MapReduce就是”任务的分解与结果的汇总“。
实验内容
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1。
buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“ ”分割,样本数据及格式如下:
- 买家id 商品id 收藏日期
- 10181 1000481 2010-04-04 16:54:31
- 20001 1001597 2010-04-07 15:07:52
- 20001 1001560 2010-04-07 15:08:27
- 20042 1001368 2010-04-08 08:20:30
- 20067 1002061 2010-04-08 16:45:33
- 20056 1003289 2010-04-12 10:50:55
- 20056 1003290 2010-04-12 11:57:35
- 20056 1003292 2010-04-12 12:05:29
- 20054 1002420 2010-04-14 15:24:12
- 20055 1001679 2010-04-14 19:46:04
- 20054 1010675 2010-04-14 15:23:53
- 20054 1002429 2010-04-14 17:52:45
- 20076 1002427 2010-04-14 19:35:39
- 20054 1003326 2010-04-20 12:54:44
- 20056 1002420 2010-04-15 11:24:49
- 20064 1002422 2010-04-15 11:35:54
- 20056 1003066 2010-04-15 11:43:01
- 20056 1003055 2010-04-15 11:43:06
- 20056 1010183 2010-04-15 11:45:24
- 20056 1002422 2010-04-15 11:45:49
- 20056 1003100 2010-04-15 11:45:54
- 20056 1003094 2010-04-15 11:45:57
- 20056 1003064 2010-04-15 11:46:04
- 20056 1010178 2010-04-15 16:15:20
- 20076 1003101 2010-04-15 16:37:27
- 20076 1003103 2010-04-15 16:37:05
- 20076 1003100 2010-04-15 16:37:18
- 20076 1003066 2010-04-15 16:37:31
- 20054 1003103 2010-04-15 16:40:14
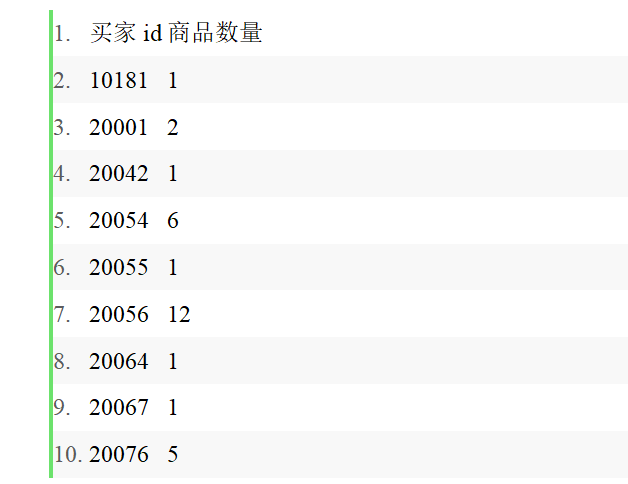
- 20054 1003100 2010-04-15 16:40:16 要求编写MapReduce程序,统计每个买家收藏商品数。按照实验报告上的步骤运行结果如下