“众里寻他千百度”——但是在信息化时代,我们只需要动动手指百度一下,google一下,便可以在网络上寻得我们想要查找的信息。我们或许都知道要如何在网上获得自己所需信息,但是上网的过程究竟是怎样的呢?
就上网方式而言,常见方式如下:
1.输入网址获得目标网页:
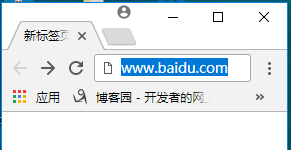
2.点击网页上的链接转到目标网页:
上网过程
其实不论用哪种方式“上网”,本质上都是同一件事:我们告诉浏览器我们需要一份网页。那么,浏览器知道了我们想要一个网页后,它是怎么做的呢?浏览器就会向服务器请求这个网页,服务器找到这份网页后就会返还给浏览器,由浏览器解释后显示出来——这就是我们上网的过程。其具体流程如下图:

网页
从流程图中我们可以一目了然地明白上网的流程,但是其中的网页又是什么呢?
当我们通过浏览器向服务器请求一个网页时,实际上是请求一个HTML文档。HTML文档——这就是我们所说的网页文件。所以,当我们略加修改,我们可以得到下图:
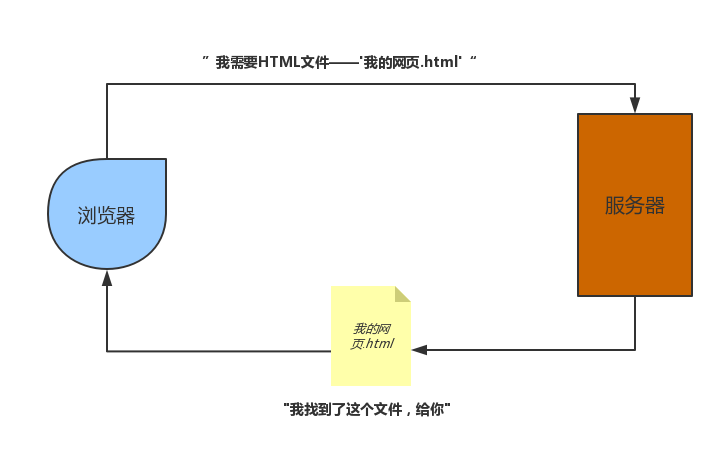
HTML文档
我们已经初步了解了上网过程与网页的本质,但是在上图,你会看到一个名为“我的网页.html”的HTML文档,HTML——超文本标记语言(Hypertext markup language),HTML文档就是用这种语言写的文档。也就是说,如果你想要自己制作网页,就必须掌握HTML。在下一章,我将介绍如何创建一份HTML文档并简单介绍HTML文档的结构。