HBase基于LSM树模型实现,所有的数据写入操作首先会顺序写入日志HLog,再写入MemStore,当MemStore中数据大小超过阈值之后再将这些数据批量写入磁盘,生成一个新的HFile文件。
HBase Table 的每个 Column family 维护一个 MemStore,当满足一定条件时 MemStore 会执行一次 flush,文件系统中生成新的 HFile。而每次 Flush 的最小单位是 Region。
1.Region的结构组成
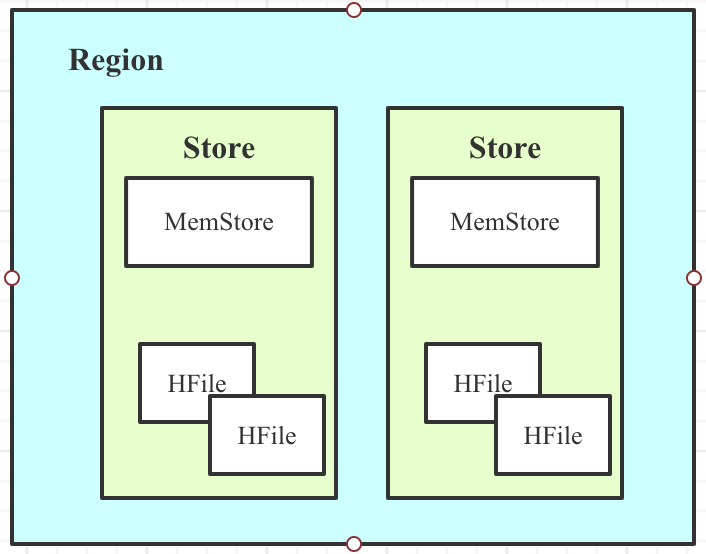
- 一张表会被水平切分成多个Region。
- 每个Region负责自己区域的数据读写请求。
- 每个Store对应一个列族,即Region中包含多个Store。
- 每个Store由一个MemStore和一系列HFile组成。
2.作用
- 存储在HDFS上的数据需要按照row key 排序。而HDFS本身被设计为顺序读写(sequential reads/writes),不允许修改。这样的话,HBase就不能够高效的写数据,因为要写入到HBase的数据不会被排序,这也就意味着没有为将来的检索优化。为了解决这个问题,HBase将最近接收到的数据缓存在内存中(in Memstore),在持久化到HDFS之前完成排序,然后再快速的顺序写入HDFS。
- 作为一个内存级缓存,缓存最近增加数据。一种显而易见的场合是,新插入数据总是比老数据频繁使用。
- 在持久化写入之前,在内存中对Rows/Cells可以做某些优化。比如,当数据的version被设为1的时候,对于某些CF的一些数据,Memstore缓存了数个对该Cell的更新,在写入HFile的时候,仅需要保存一个最新的版本就好了,其他的都可以直接抛弃。
有一点需要特别注意:每一次Memstore的flush,会为每一个CF创建一个新的HFile。 在读方面相对来说就会简单一些:HBase首先检查请求的数据是否在Memstore,不在的话就到HFile中查找,最终返回merged的一个结果给用户。
3.MemStore 的数据结构
跳表,采用的是java的 实际实现中ConcurrentSkipListMap
MemStore由两个ConcurrentSkipListMap(称为A和B)实现,写入操作(包括更新删除操作)会将数据写入ConcurrentSkipListMap A,当ConcurrentSkipListMap A中数据量超过一定阈值之后会创建一个新的ConcurrentSkipListMap B来接收用户新的请求,之前已经写满的ConcurrentSkipListMap A会执行异步f lush操作落盘形成HFile。
4.Memstore Flush流程
为了减少flush过程对读写的影响,HBase采用了类似于两阶段提交的方式,将整个flush过程分为三个阶段:
-
prepare阶段:
遍历当前Region中的所有Memstore,将Memstore中当前数据集kvset做一个快照snapshot,然后再新建一个新的kvset。后期的所有写入操作都会写入新的kvset中,而整个flush阶段读操作会首先分别遍历kvset和snapshot,如果查找不到再会到HFile中查找。prepare阶段需要加一把updateLock对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此持锁时间很短。
-
flush阶段:
遍历所有Memstore,将prepare阶段生成的snapshot持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘IO操作,因此相对比较耗时。
-
commit阶段:
-
遍历所有的Memstore,将flush阶段生成的临时文件移到指定的ColumnFamily目录下,针对HFile生成对应的storefile和Reader,把storefile添加到HStore的storefiles列表中,最后再清空prepare阶段生成的snapshot。
4.MemStore 的GC 问题
为什么MemStore的工作模式会引起严重的内存碎片?
这是因为一个RegionServer由多个Region构成,每个Region根据列簇的不同又包含多个MemStore,这些MemStore都是共享内存的。这样,不同Region的数据写入对应的MemStore,因为共享内存,在JVM看来所有MemStore的数据都是混合在一起写入Heap的。
MSLAB内存管理方式
为了优化这种内存碎片可能导致的Full GC,HBase借鉴了线程本地分配缓存(Thread-Local Allocation Buffer,TLAB)的内存管理方式,通过顺序化分配内存、内存数据分块等特性使得内存碎片更加粗粒度,有效改善Full GC情况。具体实现步骤如下:
- 每个MemStore会实例化得到一个MemStoreLAB对象。
- MemStoreLAB会申请一个2M大小的Chunk数组,同时维护一个Chunk偏移量,该偏移量初始值为0。
- 当一个KeyValue值插入MemStore后,MemStoreLAB会首先通过KeyValue.getBuffer()取得data数组,并将data数组复制到Chunk数组中,之后再将Chunk偏移量往前移动data. length。
- 当前Chunk满了之后,再调用new byte[2 * 1024 * 1024]申请一个新的Chunk。
5.相关配置参数
对Memstore Flush来说,主要有两组配置项:
- 决定Flush触发时机
- 决定Flush何时触发并且在Flush时候更新被阻断(block)
hbase.hregion.memstore.flush.size
单个MemStore的大小,默认是128M
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
<description>
Memstore will be flushed to disk if size of the memstore
exceeds this number of bytes. Value is checked by a thread that runs
every hbase.server.thread.wakefrequency.
</description>
</property>
hbase.regionserver.global.memstore.lowerLimit
hbase.regionserver.global.memstore.lowerLimit 默认0.35,表示所有的MemStore占用超过heap的35%时,会选择一些占用内存比较大的MemStore阻塞写操作并进行flush,这是为了降低阻塞全部写操作flush带来的问题。
<property>
<name>hbase.regionserver.global.memstore.lowerLimit</name>
<value>0.35</value>
<description>Maximum size of all memstores in a region server before
flushes are forced. Defaults to 35% of heap.
This value equal to hbase.regionserver.global.memstore.upperLimit causes
the minimum possible flushing to occur when updates are blocked due to
memstore limiting.
</description>
</property>
hbase.regionserver.global.memstore.upperLimit
默认0.4,当RegionServer上全部的MemStore占用超过heap(heap的大小在hbase-env.sh中设置HBASE_HEAPSIZE,默认1G,我们设置的4G)的40%时,强制阻塞所有的写操作,将所有的MemStore刷写到HFile;
<property>
<name>hbase.regionserver.global.memstore.upperLimit</name>
<value>0.4</value>
<description>Maximum size of all memstores in a region server before new
updates are blocked and flushes are forced. Defaults to 40% of heap.
Updates are blocked and flushes are forced until size of all memstores
in a region server hits hbase.regionserver.global.memstore.lowerLimit.
</description>
</property>
hbase.hregion.memstore.block.multiplier
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>2</value>
<description>
Block updates if memstore has hbase.hregion.block.memstore
time hbase.hregion.flush.size bytes. Useful preventing
runaway memstore during spikes in update traffic. Without an
upper-bound, memstore fills such that when it flushes the
resultant flush files take a long time to compact or split, or
worse, we OOME.
</description>
</property>
6.MemStore对业务的影响
正常情况下,大部分 Memstore Flush 操作都不会对业务读写产生太大影响,比如:定期刷新 MemStore、手动触发、单个 MemStore flush、Region 级别的 flush 以及超过 HLog 数量限制等情况,这几种场景只会短暂的阻塞对应 Region 上的写请求,阻塞时间很短,毫秒级别。
然而一旦触发 Region Server 级别的限制导致 flush,就会对用户请求产生较大的影响。会阻塞所有落在该 RegionServer 上的更新操作,阻塞时间很长,甚至可以达到分钟级别。
导致触发 RegionServer 级别限制的主要因素:
-
Region Server 上运行的 Region 总数
Region 越多,Region Server 上维护的 MemStore 就越多。根据业务表读写请求量和 RegionServer 可分配内存大小,合理设置表的分区数量(预分区的情况)。 -
Region 上的 Store 数(表的 Column family 数量)
每个 Column family 会维护一个 MemStore,每次 MemStore Flush,会为每个 Column family 都创建一个新的 HFile。当其中一个CF的 MemStore 达到阈值 flush 时,所有其他CF的 MemStore 也会被 flush,因此不同CF中数据量的不均衡将会导致产生过多 HFile 和小文件,影响集群性能。很多情况下,一个CF是最好的设计。
7.频繁的 MemStore Flush
频繁的 MemStore Flush 会创建大量的 HFile。在检索的时候,就不得不读取大量的 HFile,读性能会受很大影响。为预防打开过多 HFile 及避免读性能恶化(读放大),HBase 有专门的 HFile 合并处理(HFile Compaction Process),根据一定的策略,合并小文件和删除过期数据。后续的文章会有详细介绍。
参考:
http://hbasefly.com/2016/03/23/hbase-memstore-flush/
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ConcurrentSkipListMap.html
https://www.jianshu.com/p/396664db17be
https://www.huaweicloud.com/articles/ee63636f7fdca5e2bb279245909a0758.html