分页
分页器的引入
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
分页器的创建
PageNumberPagination分页器
按页码数分页,第n页,每页显示m条数据
使用URL
http://127.0.0.1:8000/api/article/?page=2&size=1
示例
# PageNumberPagination 方式 分页器 class MyPageNumberPagination(PageNumberPagination): # 创建一个自定义类继承分页器类,自定义类中进行参数设置,自定义类的实例化即为分页器对象 page_size = 1 # 每页显示数目 page_query_param = 'page' # url 中的指定 关键字 page_size_query_param = "size" # 允许临时添加的参数 max_page_size = 5 # 对临时添加数据的限制 """ 关于临时添加参数 http://127.0.0.1:8000/?page=1&size=2 size 为临时添加数据 由 page_size_query_param 控制 max_page_size 控制 size 的限制 """
class P2(PageNumberPagination): #默认每页显示的数据条数 page_size = 2 #获取url参数中设置的每页显示数据条数 page_size_query_param = 'size' #获取url中传入的页码key page_query_param = 'page' #最大支持的每页显示的数据条数 max_page_size = 5 class IndexView3(APIView): #使用http://127.0.0.1:8080/app01/v1/index3/?page=1&page_size=1可进行判断 def get(self,request,*args,**kwargs): user_list = models.UserInfo.objects.all() #实例化分页对象,获取数据库中的分页数据 p2 = P2() print(p2.page_size_query_description) page_user_list = p2.paginate_queryset(queryset=user_list,request=request,view=self) print('打印的是分页的数据',page_user_list) #序列化对象 ser = MySerializes(instance=page_user_list,many=True) #可允许多个 #生成分页和数据 # return Response(ser.data) #不含上一页下一页 return p2.get_paginated_response(ser.data)
LimitOffsetPagination分页器
分页,在n位置,向后查看m条数据
使用URL
http://127.0.0.1:8000/api/article/?offset=2&limit=2
示例
# LimitOffsetPagination 方式 分页器 class MyPageNumberPagination(LimitOffsetPagination): default_limit=1 # 每页最多显示多少数目 关键词是 limit """ LimitOffsetPagination 的分页器 拥有一个 offset 内置 参数 http://127.0.0.1:8000/?limit=1&offset=2 offst 表示向后偏移,偏移块大小为 limit的长度 当前页1 limit=1 offset=2 表示向下偏移两个长度 显示第三页内容 """
from rest_framework.views import APIView from rest_framework.response import Response from app01.serializes.myserializes import MySerializes from rest_framework.pagination import LimitOffsetPagination from app01 import models # =========== 可以自己进行自定制分页,基于limitoffset=================== class P1(LimitOffsetPagination): max_limit = 3 # 最大限制默认是None default_limit =2 # 设置每一页显示多少条 limit_query_param = 'limit' # 往后取几条 offset_query_param = 'offset' # 当前所在的位置 class IndexView2(APIView): #使用http://127.0.0.1:8080/app01/v1/index2/?offset=2&limit=4可进行判断 def get(self,request,*args,**kwargs): user_list = models.UserInfo.objects.all() p1 = P1()#注册分页 page_user_list = p1.paginate_queryset(queryset=user_list,request=request,view=self) print('打印的是分页的数据',page_user_list) ser = MySerializes(instance=page_user_list,many=True) #可允许多个 # return Response(ser.data) #不含上一页下一页 return p1.get_paginated_response(ser.data) # =======================也可以用下面这种形式=========== class BaseResponse(object): def __init__(self,code=1000,data=None,error=None): self.code = code self.data = data self.error = error class IndexView(views.APIView): '''第二种类表示的方式''' def get(self,request,*args,**kwargs): ret = BaseResponse() try: user_list = models.UserInfo.objects.all() p1 = P1() page_user_list = p1.paginate_queryset(queryset=user_list,request=request,view=self) ser = IndexSerializer(instance=page_user_list,many=True) ret.data = ser.data ret.next = p1.get_next_link() except Exception as e: ret.code= 1001 ret.error = 'xxxx错误' return Response(ret.__dict__)
CursorPagination分页器
加密分页,把上一页和下一页的id值记住
使用URL
http://127.0.0.1:8000/api/article/?page=2&size=1
示例
基本和 PageNumberPagination 内部字段差不多
class P3(CursorPagination): # URL传入的游标参数 cursor_query_param = 'cursor' # 默认每页显示的数据条数 page_size = 2 # URL传入的每页显示条数的参数 page_size_query_param = 'size' # 每页显示数据最大条数 max_page_size = 3
# 根据ID从大到小排列 ordering = "id" class IndexView4(APIView): #使用http://127.0.0.1:8080/app01/v1/index4/?cursor=cj0xJnA9NA%3D%3D&size=3可进行判断 def get(self,request,*args,**kwargs): user_list = models.UserInfo.objects.all().order_by('-id') p3 = P3()#注册分页 page_user_list = p3.paginate_queryset(queryset=user_list,request=request,view=self) print('打印的是分页的数据',page_user_list) ser = MySerializes(instance=page_user_list,many=True) #可允许多个 # return Response(ser.data) #不含上一页下一页 return p3.get_paginated_response(ser.data)
分页器的使用
# 分页器的使用一:未封装起来的时候 class BookViewSet(viewsets.ModelViewSet): queryset = Book.objects.all() serializer_class = BookSerializers def list(self,request,*args,**kwargs): book_list=Book.objects.all() # 调用分页器类实例化 (根据分页器类型要做区分) pp=LimitOffsetPagination() # 对分页器对象赋值使用 实例化自定义分页类 # 参数 queryset=被分页的queryset对象,后两个固定即可 pager_books=pp.MyPageNumberPagination(queryset=book_list,request=request,view=self) bs=BookSerializers(pager_books,many=True) return pp.get_paginated_response(bs.data) # 分页器的使用二:封装起来的时候 class AuthorModelView(viewsets.ModelViewSet): queryset = Author.objects.all() serializer_class = AuthorModelSerializers # 序列化组件 pagination_class = MyPageNumberPagination # 分页组件,分页器只能使用一个,此处不可以为列表 # 分页器的使用三: 全局生效,在settings.py 中设置 REST_FRAMEWORK = { 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination', 'PAGE_SIZE': 100 }
版本
为什么需要版本控制
API 版本控制允许我们在不同的客户端之间更改行为(同一个接口的不同版本会返回不同的数据)。 DRF提供了许多不同的版本控制方案。
可能会有一些客户端因为某些原因不再维护了,但是我们后端的接口还要不断的更新迭代,这个时候通过版本控制返回不同的内容就是一种不错的解决方案。
内置版本类型
DRF提供了五种版本控制方案
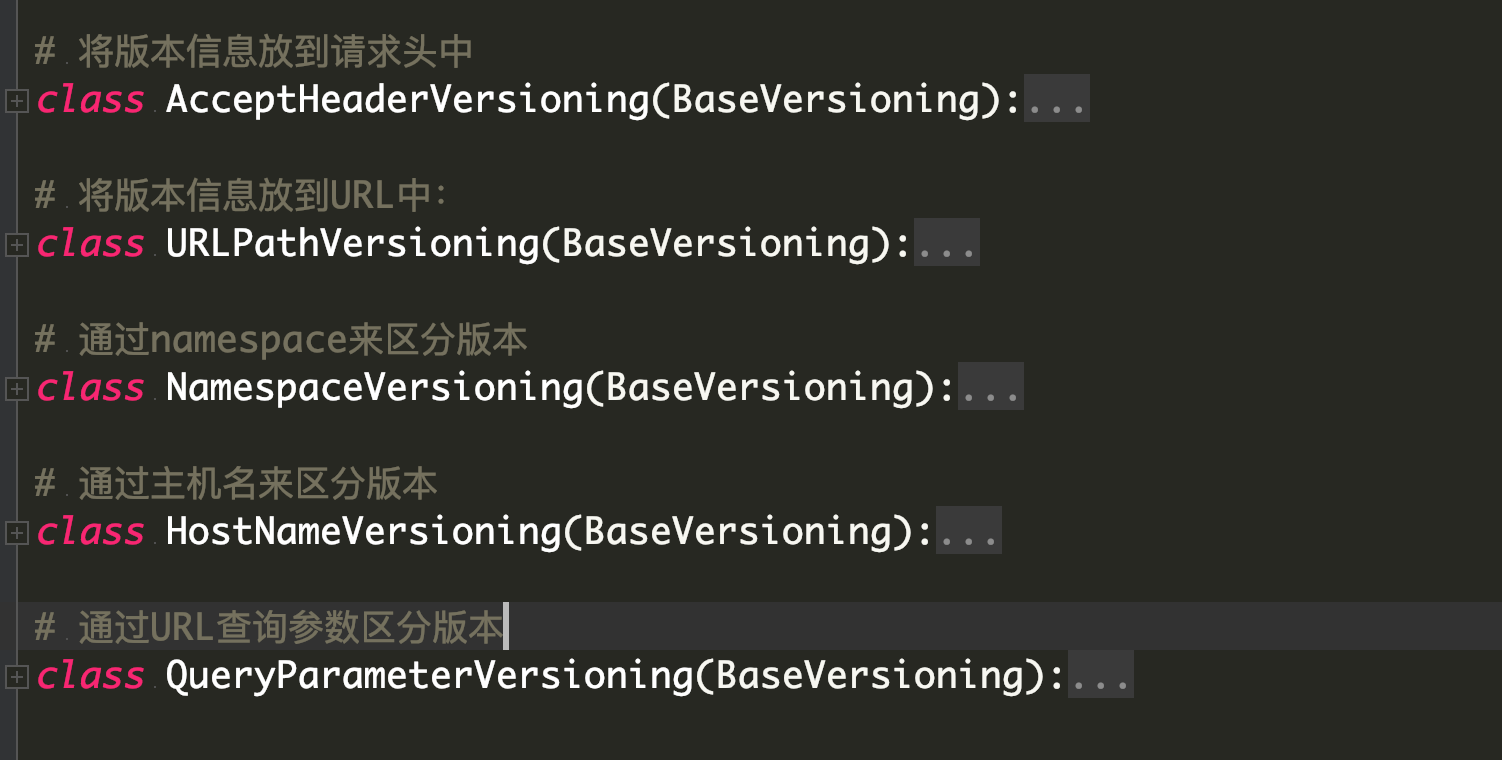
版本的创建使用
# 版本控制 # 1. 配置文件中加入 REST_FRAMEWORK = { # 全局配置版本 # "DEFAULT_VERSIONING_CLASS": "rest_framework.versioning.QueryParameterVersioning", # # 配置默认允许版本 # "ALLOWED_VERSIONS": ["v1", "v2"], # # 配置默认版本 # "DEFAULT_VERSION": "v1", # # 配置参数 # "VERSION_PARAM": "version", # 还是推荐用 URLPathVersioning 的方式来控制版本更好用一些 "DEFAULT_VERSIONING_CLASS": "rest_framework.versioning.URLPathVersioning", } # 2. 设置路由 urlpatterns = [ url(r'^(?P<version>[v1|v2]+)/api/', include("api.urls")), ] # 3 获取版本 request.version
ps:
通常我们是不会单独给某个视图设置版本控制的,如果你确实需要给单独的视图设置版本控制,你可以在视图中设置versioning_class属性
class PublisherViewSet(ModelViewSet): ... versioning_class = URLPathVersioning
在视图中自定义具体的行为,不同的版本返回不同的序列化类
class PublisherViewSet(ModelViewSet): def get_serializer_class(self): """不同的版本使用不同的序列化类""" if self.request.version == 'v1': return PublisherModelSerializerVersion1 else: return PublisherModelSerializer queryset = models.Publisher.objects.all()