issue 1. EMQX的共享订阅
EMQX是一个非常强大的物联网通信消息总线,基于EMQX开展应用开发,要注意很多配置细节问题,这里要说到的就是共享订阅以及和cleanSession之间的关系问题。共享订阅在EMQ的里程牌中出现的较早,V2的时候就已经提供了,只是那个时候只支持单节点的共享订阅,在V3的时候才支持集群的共享订阅。
共享订阅功能非常实用,解决了消费者应用程序的负载均衡问题,或者说高可用问题。否则,负载均衡或者高可用问题,需要借助于全局锁进行消息消费过程中的只消费一次的问题。这个实现起来,相对比较的麻烦,主要是稳定性和并发支持上要花很多精力调优。现在EMQX已经做了这个,已共享订阅的方式为应用程序的开发提供了便利。
共享订阅支持两种方式:
订阅前缀 使用示例 $queue/ mosquitto_sub -t ‘$queue/topic’ $share/<group>/ mosquitto_sub -t ‘$share/group/topic’
目前,我们的物联网平台中采用的是$share/<group>这种方式,主要有$share/dcX/yourTopic,和$share/resX/yourTopic这两种应用场景。
使用共享订阅,需要注意这里会遇到的潜在风险,和cleanSession的配置相关(cleanSession干什么用,自行查阅研究),这里我就拿我们项目上遇到的故事,分享一下:
- 我们的应用程序res部署了2个应用实例,emqx集群也是2个节点,其实这里和emqx集群节点数没有关系(理论分析)。res应用程序里面,cleanSession设置的是false,也就是说应用程序和EMQX的mqtt连接断掉后,emqx服务端还会保留session一个配置指定的时间。我们使用的emqx是V3.1.1,默认的session有效期是2h。共享订阅的策略是默认的random。res应用程序里面的消费者clientId是uuid随机生成的,每次运行都不一样,一旦程序启动后,ClientID就固定下来。
- 我们的测试动作是这么干的,正常启动两个res服务a和b,一切正常,共享订阅消息没有问题。测试中途,将其中一个res应用a停机了,在b上继续验证业务逻辑,发现在b上一会收的到消息,一会又收不到消息,同样的订阅逻辑,为何停掉了一个应用,就会出现这种现象?
- 上述现象发现后,大概半小时的分析,无果。然后,将停掉的res应用a再次启动,发现,还是会出现a,b,上同样有可能都收不到消息,订阅逻辑没有问题啊,怎么还是解决不了问题?
- 开始怀疑res应用程序订阅逻辑写的不对,将多个topic逐个订阅改成数组的模式一次订阅,继续部署继续测试,发现订阅不到消息的情况更明显了,这咋解释啊?
其实,当知道是res应用程序反复启停,在res上订阅不到消息的现象越发明显。这个线索非常有价值,这就提醒了问题所在了!其实就是因为cleanSession为false的情况下因为ClientID在每次启停res的时候以一个新的身份进行共享订阅了,对于EMQX来说,相当于共享订阅者变多了,每次启停,就产生了一个虚拟的共享订阅者,若我们不注意,其实是看不到的,因为我们只是关注了实际的两个res应用a和b。若你细心一点,你可以在emqx的dashboard上能够看到不止2个订阅者。(参看下面几个图)
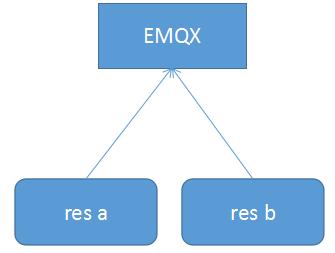
图1:正常订阅(正常的两个共享订阅者)
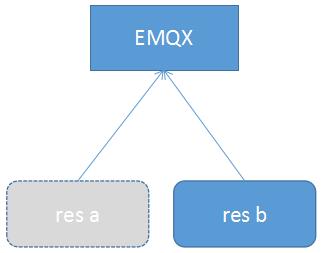
图2:将res a应用移除(相当于在一段时间内,EMQX认为有2个共享订阅者,session为超期)
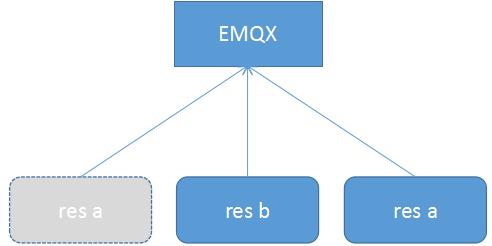
图3 将res a移除后,又加入进来共享订阅(相当于在一段时间内,EMQX认为有3个共享订阅者,session为超期)
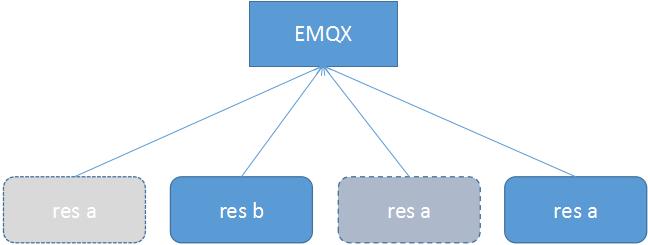
图4 将res a移除后,加入进来,然后又移除,然后又加进来(相当于在一段时间内,EMQX认为有4个共享订阅者,session为超期)
解决这个问题,其实有两个方向:
1. ClientID不能变化,每次res启停都是相同的,不管什么时候,一个res应用,对应的ClientID要恒定不变。可以基于app_ip+app_port+emqx_ip这种类似思路,进行锁定ClientID。这样EMQX这边就不会出现虚拟的消费者连接。
2. 将cleanSession配置为true,每次mqtt连接断掉后,EMQX端就不要继续保持对应连接的session,EMQX这里就会立即踢掉断线的session,不会出现潜在的接收消息的订阅者,此种情况下,及时ClientID每次不一样,也不会出现虚拟消费者。
issue 2. ACL校验
EMQX对于接入的连接,不论是想订阅和消费,首先要经过权限校验,符合ACL规则的,才允许进行后续的数据流转。但是,EMQ基于插件的方式实现auth功能,这里,我们采用的是基于mysql实现认证和acl。其实身份认证还不是多大的问题,主要是acl比较消耗mysql的性能。尤其是在连接数比较多的时候。
- 我们的压测环境下,mysql是单点库,机器配置4C24G500G。 EMQX节点2个,在连接数1W以上,每个连接每秒2个消息的情况下,mysql数据库开始出现CPU占用比较高的现象,CPU 60%的消耗。
- 当时ACL表中的记录数并不是太多,才10多万,通过show full processlist查看SQL信息,发现很多都是EMQX的emqx_auth_mysql.conf文件里面的acl_query的语句。说明这个查询比较频繁,且占用时间有点长。觉得这个不应该吧,并发不是很高啊。。。
- emqx的ACL cache配置ttl是默认的1分钟,最大缓存数量cache size是默认的32.
-
emqx_auth_mysql.conf中的查询语句:auth.mysql.acl_query = select allow, ipaddr, username, clientid, access, topic from mqtt_acl where ipaddr = '%a' or username = '%u' or username = '$all' or clientid = '%c'。 检查了下这个SQL的执行计划,得到下面的结果:
mysql> explain select allow, ipaddr, username, clientid, access, topic from scc_mqtt_acl_1 where ipaddr = '%a' or username = '%u' or username = '$all' or clientid = '%c'; +----+-------------+----------------+------------+------+---------------------------------------+------+---------+------+--------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------------+------------+------+---------------------------------------+------+---------+------+--------+----------+-------------+ | 1 | SIMPLE | scc_mqtt_acl_1 | NULL | ALL | doubleIndex,USERNAME_IDX,CLIENTID_IDX | NULL | NULL | NULL | 201976 | 34.39 | Using where | +----+-------------+----------------+------------+------+---------------------------------------+------+---------+------+--------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
可以看到,这里是没有用到索引的。即,在设备数据量很大的时候,这里是存在隐患的,即查询会全表扫描。说明emqx默认的关于ACL的查询需要结合应用场景进行优化。
-
分析了我们的应用场景,每个设备接入都有自己的用户名和密码,ipaddr是变化的,也就是说不好进行监控管理,就不做强制要求,所以可以忽略不管,ClientID,这个对于应用来说,也是基于一定规则进行的,不会出现重复的信息,所以,我们也没有做强制要求, 在ACL配置的时候,主要是基于username和ClientID进行标识记录的,username是必须要有的,ClientID不是必须的,所以,我们的ACL查询语句就优化了下,将原来默认的查询where中的几个or改了,只是一个username了。如下:
auth.mysql.acl_query = select allow, ipaddr, username, clientid, access, topic from scc_mqtt_acl_1 where username = '%u'
给数据表的username创建一个normal的索引,此时的执行计划如下:mysql> explain select allow, ipaddr, username, clientid, access, topic from scc_mqtt_acl_1 where username = '%u'; +----+-------------+----------------+------------+------+---------------+--------------+---------+-------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------------+------------+------+---------------+--------------+---------+-------+------+----------+-------+ | 1 | SIMPLE | scc_mqtt_acl_1 | NULL | ref | USERNAME_IDX | USERNAME_IDX | 403 | const | 1 | 100.00 | NULL | +----+-------------+----------------+------------+------+---------------+--------------+---------+-------+------+----------+-------+ 1 row in set, 1 warning (0.04 sec)可以看到,索引生效了,取代默认配置or语句,用上索引。
issue 3. emqx稳定性问题
我们的压测目标,就是在两个EMQX节点集群环境(4C16G100G)下,能够支持至少10000的TPS(每秒10000条消息被消费),目标20000个连接。 下面的几种case中,消费者程序是一样的。生成消息的机制有点变化,但是消息报文大小是一样的。
case 1.
在用V3.0.1的时候,进行压测,并发20000TPS,100连接。出现下面的错误信息,提示消息处理不过来,EMQX将消费者进行剔除。
2019-09-11 20:44:38.916 [error] 39346787c9bc4afd990a16a2700995fd@10.95.198.25:40038 [Channel] Shutdown exceptionally due to message_queue_too_long 2019-09-11 20:44:49.827 [warning] [SYSMON] large_heap warning: pid = <0.5103.0>, info: [{old_heap_block_size,6189440}, {heap_block_size,3581853}, {mbuf_size,0}, {stack_size,29}, {old_heap_size,2848687}, {heap_size,1048794}] [{initial_call,{proc_lib,init_p,5}}, {current_function,{lists,foldl,3}}, {registered_name,[]}, {status,running}, {message_queue_len,57631}, {group_leader,<0.2133.0>}, {priority,normal}, {trap_exit,true}, {reductions,1536664490}, {last_calls,false}, {catchlevel,2}, {trace,0}, {suspending,[]}, {sequential_trace_token,[]}, {error_handler,error_handler}, {memory,83275744}, {total_heap_size,9775308}, {heap_size,3581853}, {stack_size,34}, {min_heap_size,233}] 2019-09-11 20:44:50.300 [error] 9001547605ec46648b3c485103233946@10.95.198.26:58460 [Channel] Shutdown exceptionally due to message_queue_too_long 2019-09-11 20:44:57.398 [error] b34a92025fbc4c89bbe54ca22e74199f@10.95.198.25:40110 [Channel] Shutdown exceptionally due to message_queue_too_long 2019-09-11 20:44:57.922 [error] a74b0c24136b4c5899dc866fe57d9173@10.95.198.25:40112 [Channel] Shutdown exceptionally due to message_queue_too_long 2019-09-11 20:45:05.640 [error] 4f930fb242734f9ba22ce57c753c482b@10.95.198.26:58442 [Channel] Shutdown exceptionally due to message_queue_too_long 2019-09-11 20:45:30.424 [error] 39346787c9bc4afd990a16a2700995fd@10.95.198.25:40116 [Channel] Shutdown exceptionally due to message_queue_too_long 2019-09-11 20:45:32.180 [error] a74b0c24136b4c5899dc866fe57d9173@10.95.198.25:40126 [Channel] Shutdown exceptionally due to message_queue_too_long 2019-09-11 20:45:32.376 [error] b34a92025fbc4c89bbe54ca22e74199f@10.95.198.25:40128 [Channel] Shutdown exceptionally due to message_queue_too_long 2019-09-11 20:45:51.497 [error] 9001547605ec46648b3c485103233946@10.95.198.26:33234 [Channel] Shutdown exceptionally due to message_queue_too_long
这个问题,在V3.0.1下测试很久,逐渐降低并发,降到13000左右才算稳定。但是这个过程中,遇到CPU消耗不稳定的现象,解决CPU在两个EMQX之间很不平衡,以及调整共享订阅的Strategy从random到round_robin启动失败,将版本调整到了V3.1.1
case 2.
在用V3.1.1的时候,同样进行压测,并发低些,但是要求连接数提升,至少过万,但是模拟的设备数量不到6000就出现问题。
2019-10-09 08:42:15.479 [error] 10.95.198.31:46924 ** State machine <0.14661.18> terminating ** Last event = {timeout,15000} ** When server state = {idle, {state,esockd_transport,#Port<0.418835>, {{10,95,198,31},46924}, undefined,running,100, {pstate,external, #Fun<emqx_connection.0.73284863>, {{10,95,198,31},46924}, nossl,4,<<"MQTT">>,<<>>,false, <0.14661.18>,undefined,undefined, undefined,undefined,false,#{},1048576, undefined,undefined,undefined,false,true, true,false,ignore, #{msg => 0,pkt => 0}, #{msg => 0,pkt => 0}, false,undefined,false, #{from_client => 0,to_client => 0}, emqx_connection,#{},undefined}, {none, #{max_packet_size => 1048576, version => 4}}, {emqx_gc, #{cnt => {1000,1000}, oct => {1048576,1048576}}}, undefined,true,undefined,undefined,undefined, undefined,15000}} ** Reason for termination = exit:idle_timeout ** Callback mode = [state_functions,state_enter] ** Stacktrace = ** [{gen_statem,loop_event_result,9,[{file,"gen_statem.erl"},{line,1158}]}, {proc_lib,init_p_do_apply,3,[{file,"proc_lib.erl"},{line,249}]}]
这个问题,研究了很长时间,开始总以为是客户端程序写的有问题,改过几种版本的消息生产者程序,都是不成功,连接数上不来。后来查看EMQX在Github上的issue列表,发现有关于idle_timeout的merge request(https://github.com/emqx/emqx/pull/2675),我估计是不是知道内部有错误,做了修改。另外,关于这个问题,有人也提了issue,只是我觉得emqx的维护者并不是很nice的解答开发者的问题(https://github.com/emqx/emqx/issues/2686,这个issue的解答,我是觉得没有说清楚的)。于是,我将版本升级到了最新版本V3.2.3,再次测试这个连接数的问题,到目前为止,可以上升到13000的连接数,EMQX集群运行还算正常。
PS:
一个小小的经验,出现下面类似这样的警告,说明ClientID出现了重复,因为EMQX里面不允许出现重复的ClientID,若出现,将会阻断后接入的这个应用的接入。
2019-10-09 18:06:52.083 [warning] 1_qemqeqseq68@10.95.198.31:60514 [Channel] Discarded by 1_qemqeqseq68:<41446.2930.412> 2019-10-09 18:06:52.083 [warning] 1_qewf2p45b7k@10.95.198.31:60500 [Channel] Discarded by 1_qewf2p45b7k:<41446.2733.412> 2019-10-09 18:06:52.083 [warning] 1_qem2iltm7eo@10.95.198.31:60508 [Channel] Discarded by 1_qem2iltm7eo:<41446.32139.411> 2019-10-09 18:06:52.084 [warning] 1_qer8ey3os8w@10.95.198.31:60555 [Channel] Discarded by 1_qer8ey3os8w:<41446.19217.410> 2019-10-09 18:06:52.087 [warning] 1_qeq2zud8kqo@10.95.198.31:60536 [Channel] Discarded by 1_qeq2zud8kqo:<0.31128.411> 2019-10-09 18:06:52.088 [warning] 1_qeoe5lwdreo@10.95.198.31:60528 [Channel] Discarded by 1_qeoe5lwdreo:<0.27662.411> 2019-10-09 18:06:52.088 [warning] 1_qeo1lfw2nls@10.95.198.31:60504 [Channel] Discarded by 1_qeo1lfw2nls:<0.27702.411> 2019-10-09 18:06:52.091 [warning] 1_qex6mpfgnwg@10.95.198.31:60567 [Channel] Discarded by 1_qex6mpfgnwg:<0.27882.411> 2019-10-09 18:06:52.091 [warning] 1_qemujku3vgg@10.95.198.31:60558 [Channel] Discarded by 1_qemujku3vgg:<0.2020.412> 2019-10-09 18:06:52.091 [warning] 1_qemvx7mz3sw@10.95.198.31:60564 [Channel] Discarded by 1_qemvx7mz3sw:<41446.3072.412>
最后总结一下感受:
1. EMQX功能很强大,基本性能的确也非常不错,但是使用起来,尤其是想作为产品级别来使用,目前基于免费的版本,的确存在很多坑。
2. EMQX里面的确还有较多的不稳定问题存在,因为相关的资料的确太少,加上erlang语言,懂的不多,出现问题,调查起来非常的费劲,所以,还希望互联网用户能够积极分享经验。