概述
当前开源的hadoop任务工作流管理主要有oozie和Azkaban,本文先介绍oozie的配置安装与基本运行原理。
配置安装
(参考https://segmentfault.com/a/1190000002738484)
1. 首先要自己下载代码编译。
git clone https://github.com/apache/oozie.git
2. 修改pom文件,修改scala和hadoop版本。
<spark.scala.binary.version>2.11</spark.scala.binary.version> <hadoop.version>2.7.0</hadoop.version>
3. 编译
bin/mkdistro.sh -DskipTests -Dhadoop.version=2.7.0 -Pspark-2 -Phadoop-2
注释:支持spark yarn模式运行,必须加上-Phadoop-2,编译后的文件在distro/target/oozie-4.3.0-distro/oozie-4.3.0文件夹内
4. 安装oozie server(1)创建目录
cd distro/target/oozie-4.3.0-distro/oozie-4.3.0/
mkdir libext
(2)oozie server 需要用到一个js库,在csdn上(http://download.csdn.net/detail/on_way_/8674059),下载后把ext-2.2.zip这个文件放的libext文件夹里。
cp ~/Downloads/ext-2.2.zip libext/
(3)把hadoop的jar把也放到这个libext文件夹内,参考下面这个命令
cp ${HADOOP_HOME}/share/hadoop/*/*.jar libext/
cp ${HADOOP_HOME}/share/hadoop/*/lib/*.jar libext/
(4)输出下述jar包,不要放到libext中
cd libext
rm jasper-compiler-5.5.23.jar
rm jasper-runtime-5.5.23.jar
rm jsp-api-2.1.jar
cd ../
(5)hue+oozie运行任务异常:
java.lang.NoSuchFieldError: HADOOP_CLASSPATH
解决方法(参考http://stackoverflow.com/questions/41205447/oozie-example-map-reduce-job-fails-with-java-lang-nosuchfielderror-hadoop-class)
mkdir tmp
cp oozie.war tmp
cd tmp
jar -xvf oozie.war
rm -f WEB-INF/lib/hadoop-*.jar
rm -f WEB-INF/lib/hive-*.jar
rm oozie.war
jar -cvf oozie.war ./*
cp oozie.war ../
cd ../
bin/oozie-setup.sh prepare-war
(6)更新hadoop配置conf/hadoop-conf
mkdir conf/hadoop-conf
cp ${HADOOP_HOME}/etc/hadoop/* conf/hadoop-conf
(7)新增spark配置conf/spark-conf
mkdir conf/spark-conf
cp ${SPARK_HOME}/conf/* conf/spark-conf
(8)增加oozie配置conf/oozie-site.xml
<property>
<name>oozie.service.ProxyUserService.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>oozie.service.ProxyUserService.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
验证方式:
http://localhost:11000/oozie/v1/admin/configuration?timezone=America%2FLos_Angeles&user.name=hadoop&doAs=test
(9)执行下面的命令,把相关的jar包传到hdfs上
bin/oozie-setup.sh sharelib create -fs hdfs://mycluster
(10)启动bin/oozied.sh start
oozie运行试运行
配置好job.properties和workflow.xml后,就可以运行spark任务了。
cd oozie-4.3.0/examples/src/main/apps/spark
oozie job -oozie http://localhost:11000/oozie -config job.properties -run
oozie的缺陷
oozie中,由于分叉和连接节点需要成对出现,这会导致导致一些流在oozie中无法支持,例如。如 A->C,B->C, B->D,这种依赖关系在oozie中无法实现。
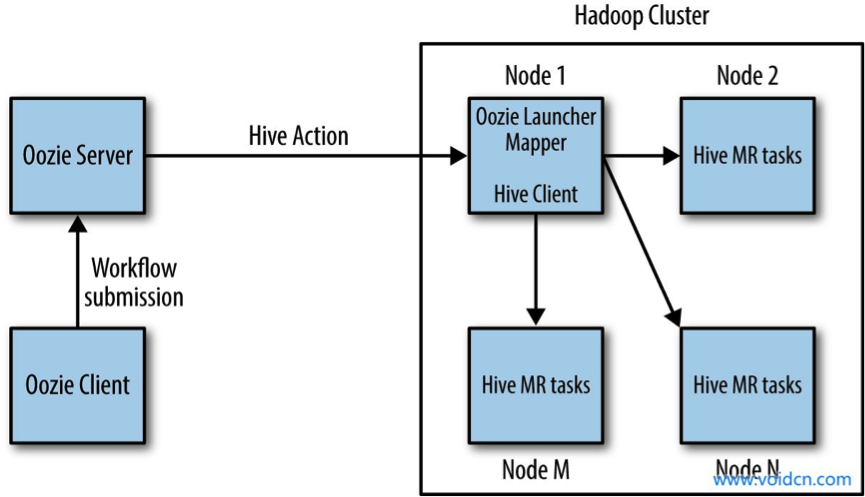
最后附一张oozie运行任务的流程图: