全分布模式安装
1、准备工作
(*)关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
(*)安装JDK
(*)配置主机名 vi /etc/hosts
192.168.153.11 bigdata11
192.168.153.12 bigdata12
192.168.153.13 bigdata13
(*)配置免密码登录:两两之间的免密码登录
(1) 每台机器产生自己的公钥和私钥
ssh-keygen -t rsa
(2) 每台机器把自己的公钥给别人
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata11
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata12
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata13
(*)保证每台机器的时间同步
如果时间不一样,执行MapReduce程序的时候可能存在问题
2、在主节点上(bigdata11)安装Hadoop
(1)解压设置环境变量
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
设置:bigdata11 bigdata12 bigdata13
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
(2) 修改配置文件
进入Hadoop的配置文件目录:

修改hadoop-env.sh 文件,添加Java的安装目录

=======hdfs-site.xml
<!--表示数据块的冗余度,默认:3-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
=======core-site.xml
<!--配置NameNode地址,9000是RPC通信端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata11:9000</value>
</property>
<!--HDFS数据保存在Linux的哪个目录,默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
========mapred-site.xml 默认没有 cp mapred-site.xml.template mapred-site.xml
<!--MR运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
=============yarn-site.xml
<!--Yarn的主节点RM的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata11</value>
</property>
<!--MapReduce运行方式:shuffle洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
slaves
bigdata11
bigdata12
bigdata13
(3) 格式化NameNode: hdfs namenode -format
(4) 把主节点上配置好的hadoop复制到从节点
scp -r hadoop-2.7.3/ root@bigdata12:/root/training
scp -r hadoop-2.7.3/ root@bigdata13:/root/training
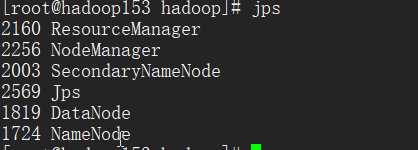
(5) 在主节点上启动 start-all.sh
通过jps命令可以查看得到以下进程