elasticsearch自身支持本地同义词,使用远程词库需要使用插件,两种方式使用方法如下:
一 本地同义词库:
官方地址:https://www.elastic.co/guide/en/elasticsearch/reference/5.0/analysis-synonym-tokenfilter.html
安装好elasticsearch和elasticsearch-analysis-ik分词器分词器后,再配置同义词;elasticsearch 自身自带的有一个名为 synonym 同义词的 filter,需要我们在自定义分析器的时候指定使用该filter;步骤如下:
例1
1)新建同义词文件:首先要在es的elasticsearch-2.3.3/config目录下面,存放synonyms.txt, synonyms.txt 编码格式为’utf-8’;在文件里写入同义词配置:
西红柿, 番茄 马铃薯, 土豆
有两种写法:
a,b => c
a,b,c第一种在分词的时候,a,b都会解析成为c,然后把c存入索引中
第二种在分词的时候,有a的地方,都会解析成a,b,c,把a,b,c存入索引中
第一种方法相比之下有个主词,比较省索引。
2)新建索引,自定义分析器:
/atest/ post
{ "settings": { "analysis": { "analyzer": { "customsynonym": { "tokenizer": "whitespace", "filter": [ "mysynonym" ] } }, "filter": { "mysynonym": { "type": "synonym", "synonyms_path": "analysis/synonym.txt", "ignore_case": true } } } }, "mappings": { "product": { "properties": { "firstname": { "type": "string", "index": "analyzed", "analyzer": "customsynonym"
} } } } }
3 测试:
http://192.168.60.60:xxxx/atest/_analyze?text=土豆&analyzer=customsynonym
结果:
{ "tokens": [ { "token": "土豆", "start_offset": 0, "end_offset": 2, "type": "word", "position": 0 }, { "token": "马铃薯", "start_offset": 0, "end_offset": 2, "type": "SYNONYM", "position": 0 } ] }
例2 也可以不在索引中定义,在/config/elasticsearch.yml es的配置文件中定义改配置,同时同义词也可以结合ik分词器使用:
1)跟上面一样新建同义词文件,加入同义词数据;
2)在es配置文件elasticsearch.yml中最后面加入如下配置
index:
analysis:
analyzer:
ik_syno:
type: custom
tokenizer: ik_max_word
filter: [my_synonym_filter]
ik_syno_smart:
type: custom
tokenizer: ik_smart
filter: [my_synonym_filter]
filter:
my_synonym_filter:
type: synonym
synonyms_path: analysis/synonym.txt
以上配置定义了 ik_syno 和 ik_syno_smart 这两个新的 analyzer,分别对应 IK 的 ik_max_word 和 ik_smart 两种分词策略。根据 IK 的文档,二者区别如下:
● ik_max_word:会将文本做最细粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、民、共和国、共和、和、国国、国歌」,会穷尽各种可能的组合;
● ik_smart:会将文本做最粗粒度的拆分,例如「中华人民共和国国歌」会被拆分为「中华人民共和国、国歌」;
ik_syno 和 ik_syno_smart 两个自定义分析器 都会使用 synonym filter 实现同义词转换。
可以直接使用 http://192.168.60.60:xxxx/_analyze?text=土豆&analyzer=customsynonym 测试,在指定mapping时,可以使用一定的策略,例如部分字段指定自定义的分析器ik_syno 或 ik_syno_smart 他们都是兼容同义词的,部分字段不指定,而使用默认的ik分词器等等
二 动态同义词配置(远程词库)
本地同义词设置只能读取本地同义词文件,如果我们要动态热更新同义词,并配置远程同义词词库需要使用到elasticsearch-analysis-dynamic-synonym插件,官方地址:https://github.com/bells/elasticsearch-analysis-dynamic-synonym
1 选择合适的包:
找到适合Elasticsearch版本的elasticsearch-analysis-dynamic-synonym插件,如果没有找到适合的版本,可以找临近的版本,通过修改配置文件的版本号来解决兼容性

例如我的es是2.3.3的,没有找到对应es2.3.3的包,就下载2.3.0的包,编译后修改plugin-descriptor.properties文件的配置,将2.3.0修改为2.3.3:
 和
和
2 安装步骤:
1) 下载包,并在包的目录执行
2) mvn package //编译
3) 将编译成功后会生成target目录,将target/releases/elasticsearch-analysis-dynamic-synonym-{version}.zip 文件copy并解压到到es的plugins目录: plugins/dynamic-synonym,
路径地址如图: 。
。
注意:实际解压出来的文件比上面要多,由于个别文件与之前安装的IK插件里的文件冲突,故删掉这里的冲突的文件。
3 新建远程同义词库:http://10.10.110.201:1111/dics/synonym.txt ,注意远程词库必须是utf-8格式

4 结合ik分词器,使用同义词分词器 自定义分析器
最终既读取了ik词库里的词语,又可以使用同义词功能
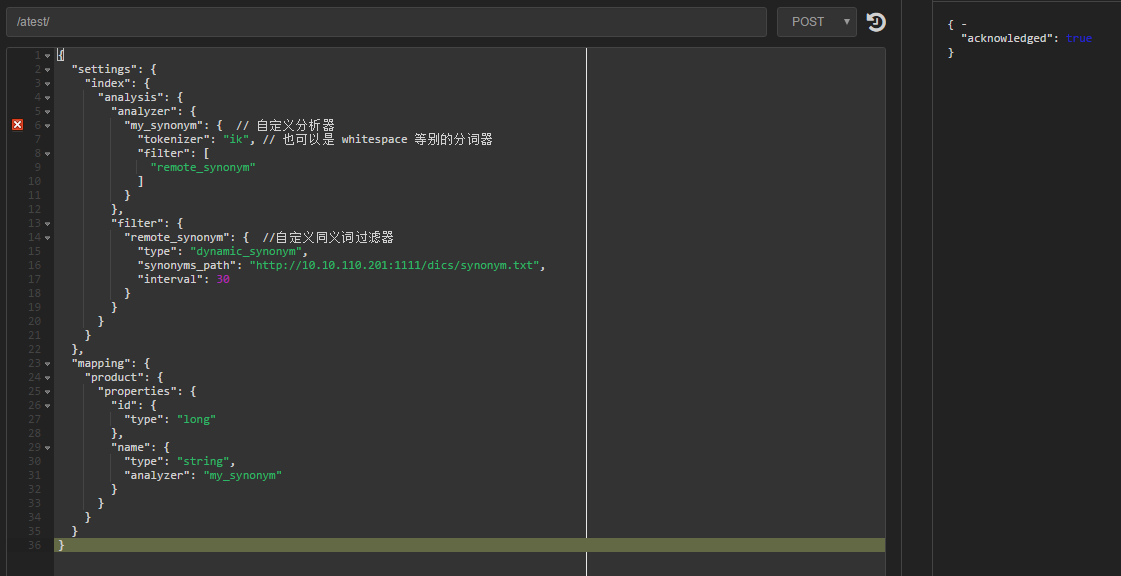
测试:
http://192.168.60.60:xxxx/atest/_analyze?text=土豆&analyzer=my_synonym
{ "tokens": [ { "token": "土豆", "start_offset": 0, "end_offset": 2, "type": "CN_WORD", "position": 0 }, { "token": "马铃薯", "start_offset": 0, "end_offset": 2, "type": "SYNONYM", "position": 0 }, { "token": "豆", "start_offset": 1, "end_offset": 2, "type": "CN_WORD", "position": 1 } ] }
官方介绍的写法:
{ "index" : { "analysis" : { "analyzer" : { "synonym" : { "tokenizer" : "whitespace", "filter" : ["remote_synonym"] } }, "filter" : { "remote_synonym" : { "type" : "dynamic_synonym", "synonyms_path" : "http://host:port/synonym.txt", "interval": 30 }, "local_synonym" : { "type" : "dynamic_synonym", "synonyms_path" : "synonym.txt" }, } } } }
说明: synonyms_path 是必须要配置的,根据它的值是否是以http://开头来判断是本地文件,还是远程文件。
interval 非必须配置的,默认值是60,单位秒,表示间隔多少秒去检查同义词文件是否有更新。
ignore_case 非必须配置的, 默认值是false。
expand 非必须配置的, 默认值是true。
format 非必须配置的, 默认值是空字符串, 如果为wordnet,则表示WordNet结构的同义词。
热更新同义词说明
- 对于本地文件:主要通过文件的修改时间戳(Modify time)来判断是否要重新加载。
- 对于远程文件:
synonyms_path是指一个url。 这个http请求需要返回两个头部,一个是Last-Modified,一个是ETag,只要有一个发生变化,该插件就会去获取新的同义词来更新相应的同义词。
注意: 不管是本地文件,还是远程文件,编码都要求是UTF-8的文本文件
es的自定义分析器介绍: http://www.cnblogs.com/shaner/p/6340925.html
es分词器插件介绍: http://www.cnblogs.com/shaner/p/5663588.html
nest的实现代码:


/// <summary> /// 生成包含拼音分词和同义词功能的mapping /// </summary> /// <typeparam name="T"></typeparam> /// <param name="indexName"></param> public static ICreateIndexResponse AddSynonymsIKPYMapping<P>(string indexName) where P : class { var pinYinTokenizer = new PinYinTokenizer(); var pinYinTF = new PinYinTF(); var iktokenizer = new Iktokenizer(); var remote_synonymtf = new Remote_synonymTF(); ICreateIndexRequest descriptor = new CreateIndexDescriptor(indexName) .Settings(s => s .Analysis(a => //自定义分析器 a.Tokenizers(ts => ts.UserDefined("ik", iktokenizer) .UserDefined("pinyintoken", pinYinTokenizer)) .TokenFilters(tf => tf.UserDefined("remote_synonym", remote_synonymtf) .UserDefined("pinyintf", pinYinTF)) .Analyzers(c => c.Custom("synonymikanalyzer", f => f.Tokenizer("ik").Filters("remote_synonym")) .Custom("pinyinanalyzer", f => f.Tokenizer("pinyintoken").Filters("pinyintf"))) //设置ik&同义词自定义的分析器 ) ).Mappings(ms => ms .Map<P>(m => m.AutoMap()) ); var ir = ESHelper.GetInstance().GetElasticClient().CreateIndex(descriptor); return ir; }
class Iktokenizer : ITokenizer { public string Type { get { return "ik"; } } public string Version { get { return ""; } set { throw new NotImplementedException(); } } } public class Remote_synonymTF: ITokenFilter { public string Type { get { return "dynamic_synonym"; } } /// <summary> /// 远程词库地址 /// </summary> public string synonyms_path { get { return AppConfig.SynonymsPath; } } /// <summary> /// 词库刷新时间 s /// </summary> public string interval { get { return "5"; } } /// <summary> /// /// </summary> public string Version { get { return ""; } set { throw new NotImplementedException(); } } }
/// <summary> /// 自定义拼音分词器 /// </summary> public class PinYinTokenizer : ITokenizer { public string Type { get { return "pinyin"; } } public string Version { get { return string.Empty; } set { throw new NotImplementedException(); } } public string first_letter { get { return "prefix"; } //开启前缀匹配 } //public string padding_char //{ // get { return " "; } //} public bool keep_full_pinyin { get { return true; } } } /// <summary> /// 自定义拼音词元过滤器 /// </summary> public class PinYinTF : ITokenFilter { /// <summary> /// 连词过滤器 /// </summary> public string Type { get { return "nGram"; } } public string Version { get { return ""; } set { throw new NotImplementedException(); } } public int min_gram { get { return 1; } } public int max_gram { get { return 10; } } }