HBase基本知识和应用场景
✿ 诞生背景:
hadoop局限性: Hadoop 只能执行批量处理,并且只以顺序方式访问数据。
✿ hadoop实际应用之一:Hadoop+HBase(随机高效读取)建立NoSQL分布式数据库应用
一、HBase(HBase以表的形式存储数据,表有行和列组成。)
1,什么是HBase?
HBase是一个分布式的、面向列的开源数据库。本质是一个数据库(适用于分布式的数据库,它面向列)。
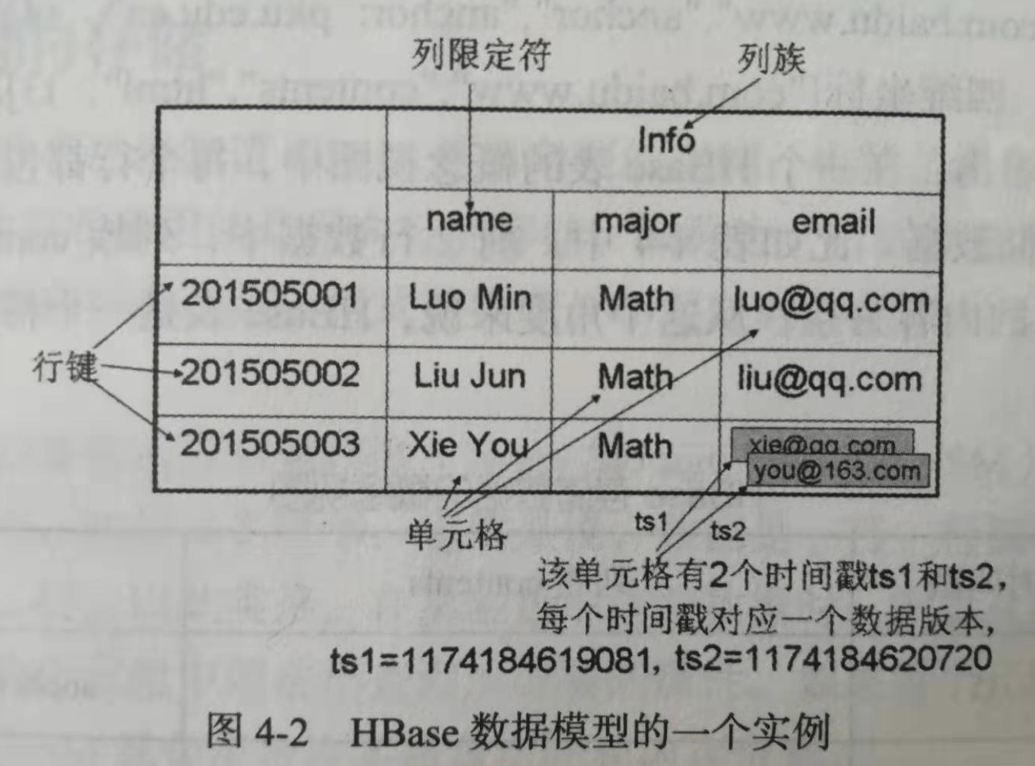
HBase 结构,首先是一张表结构,然后与一般表不同的是,一般表:同一个列名下的那些一个个的单元格的值类型是相同的,而 HBase表是同一个列名下的那些一个个的单元格的值类型是不同,且数量不同...
(相比于传统表,同列名下的一个个单元格,hbase 的单元格内容,可以装不定长的数据(一些以键值对形式存储的数据,一些则直接也是单个值的形式))
✿ 传统表:单元格 是一个坑一个萝卜
✿ HBase表:单元格 是一个坑 一把花生 (花生有双仁、单仁的哦)
(图:传统的表)
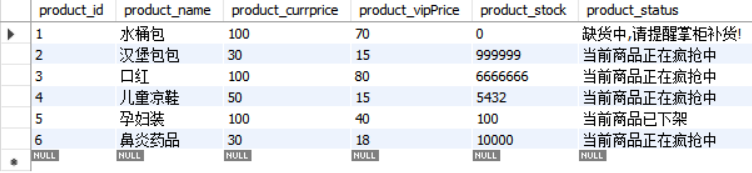
(图2:HBase 表)
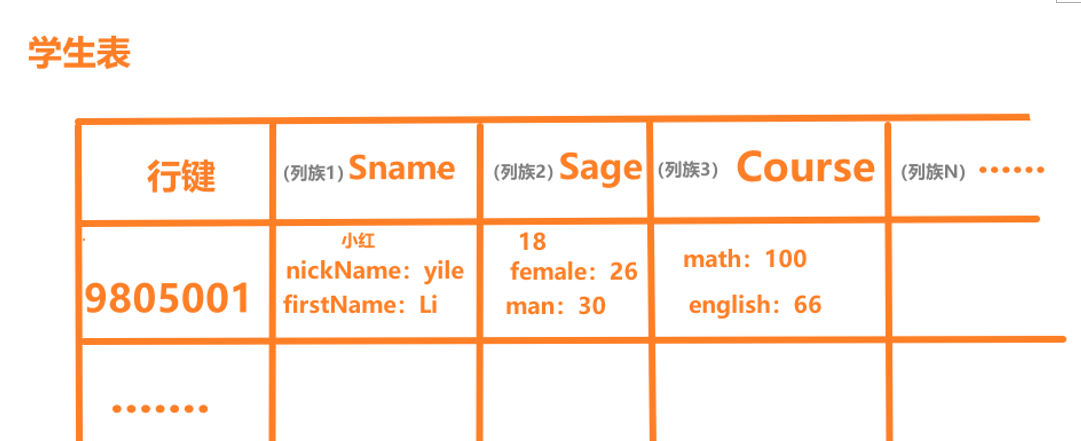
列族里的数据通过列限定符或列来定位,
通过列限定符来定位例如:Sname:nickName,Sage:female 等等;通过列来定位 的例如:Sname:小红
2,HBase 中的表特点:
(1)大:一个表可以有上十亿行,上百万列
(2)面向列:列可以灵活指定,面向列(族)的存储和权限控制,列(簇)独立检索。
(3)稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
(4)无严格模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列
3.1,HTable一些基本概念1
☺ 在HBase中,HTable是其客户端和服务端通信的java api对象,主要提供对表的put/get/delete/scan等操作
创建一个 hBase 对象:
Configuration conf = HBaseConfiguration.create(); HTable hTable = new HTable(conf, "tableName");
② HTable 的增删改查,这里简单举几个例子
●获取指定行某些单元格对应的值:public Result get(final Get get) throws IOException
●获取表名:public byte [] getTableName()
●添加值:public void put(final Put put) throws IOException
●删除指定单元格/行:void delete(Delete delete) throws IOException
......
ps: HBase Java API 代码开发
常用的几个主要HBase API类和数据模型之间的对应关系:
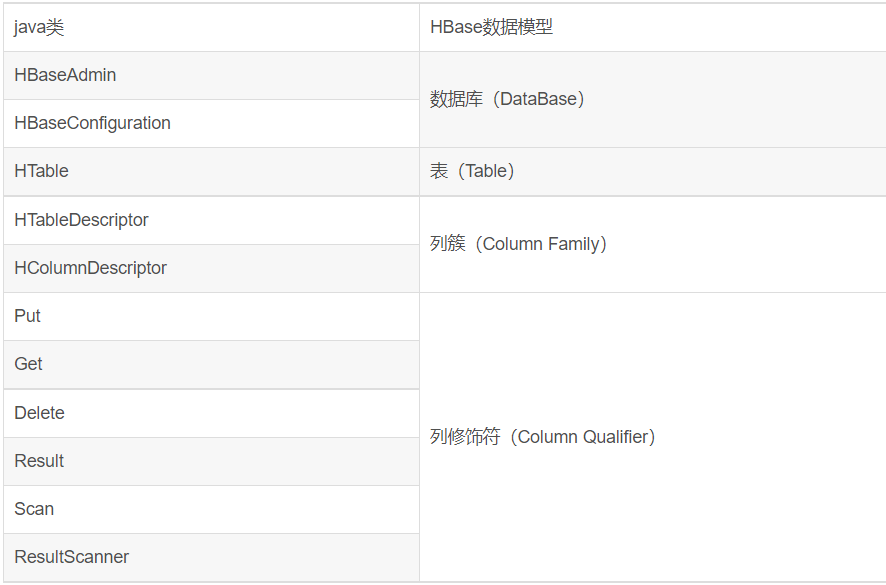
3.2, HTable一些基本概念2 【表结构逻辑视图】
|
表:HBase用表来组织数据。 行:在表里,数据按行存储,行由行键唯一标识。行键没有数据类型,为字节数组byte[]。 列族:行里的数据按照列族分组,列族必须事先定义并且不轻易修改。表中每行拥有相同的列族。 列限定符:列族里的数据通过列限定符或列来定位,列限定符不必事先定义。 单元:存储在单元里的数据称为单元值,值是字节数组。单元由行键,列族或列限定符一起确定。 时间版本:单元值有时间版本,是一个long类型。 |
1、 行键(RowKey):
① 通过单个 row key 访问
② 通过 row key 的 range
③ 全表扫描
2、 列簇(Column Family):
- HBase 表中的每个列,都归属与某个列簇。列簇是表的 Schema 的一部分(而列不是)
- 列名都以列簇作为前缀。例如:student:name,student:age,teacher:age 等等 (例子在文章最后的图1)
- 访问控制、磁盘和内存的使用统计等都是在列簇层面进行的。
- 列簇越多,在取一行数据时所要参与 IO、搜寻的文件就越多,所以,如果没有必要,不要设置太多的列簇,官网推荐是小于等于 3(最好就一个列簇)
3、 时间戳(TimeStamp):
■ 时间戳可以由 HBase (在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。
■ 每个单元格都保存着同一份数据的多个版本。版本通过时间戳来索引。
■ 如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
■ 每个单元格中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。HBase 在查询的时候,默认返回最新版本/最近的数据。如果需要读取旧版本的数据,可以指定时间戳。
□
为了避免数据存在过多版本造成的的管理(包括存储和索引)负担,HBase 提供了两种数据版本回收方式:
保存数据的最后 n 个版本
保存最近一段时间内的版本(设置数据的生命周期
TTL)。
用户可以针对每个列簇进行设置。
4、 单元格(Cell):
■ 由{RowKey, Column( =<Column Family> + <Qualifier>), Version} 唯一确定的单元。Cell 中的数据是没有类型的,全部是字节码形式存储。
二、HBase 的安装和应用
对应于Hadoop,HBase 也有三种运行模式:单机模式、伪分布式模式、分布式模式。
..........(安装过程遇到的bug,请参考文章)《HBase 安装之后版本的验证的bug:(错误的替换、找不到或无法加载主类、SLF4J)》
附录
图1:HBase 表结构

图2:列名以列簇作为前缀的例子
列族里的数据通过列限定符或列来定位,
通过列限定符来定位例如:Sname:nickName,Sage:female 等等;通过列来定位 的例如:Sname:小红
参考文章:
《Hbase总结(五)-hbase常识及habse适合什么场景》https://blog.csdn.net/lifuxiangcaohui/article/details/39894265
《hBase之HTable踩坑》https://www.jianshu.com/p/8f5fad6d7c9c
《HBase基础知识》https://blog.csdn.net/qq_1018944104/article/details/85013790
《HBase 的Get(读),Put(写),Delete(删),Scan(扫描)和Increment(列值递增)》https://www.cnblogs.com/wangleBlogs/p/9935553.html