最近在弄一件任务,要求测试一下从文本中读取数据,然后向mysql表中插入。要求用JDBC线程导入。要求效率。
环境说明:
数据量 : 10058624条 (大约一千零6万条数据,本地机器运行)
数据大小 : 1093.56MB (1.1G)
MYSQL版本 : 5.7 (装在服务器上)
MYSQL引擎: InnoDB
MYSQL未做任何优化,配置如图:

一、数据文件读取
因为项目要求读取的是dbf文件,数据量比较大,所以单独写了一个程序,测试一下数据读取用多久。
未做任何保存、配置,只是将数据循环遍历一边。 计算出时间:
数据量 :10058624条 (大约一千零6万条数据 ,截图中没有显示)
读取用时 : 19s

二、 代码优化。(mysql配置不动)
方式一: 传统方式

输出时间:
Program running index : 10000 use : 7 s
Program running index : 20000 use : 15 s
Program running index : 30000 use : 21 s
Program running index : 40000 use : 28 s
Program running index : 50000 use : 34 s
Program running index : 60000 use : 41 s
Program running index : 70000 use : 48 s
Program running index : 80000 use : 54 s
Program running index : 90000 use : 61 s
Program running index : 100000 use : 69 s
Program running index : 500000 use : 346 s
Program running index : 1000000 use : 693 s
Program running index : 1500000 use : 1042 s
Program running index : 2000000 use : 1402 s
Program running index : 2500000 use : 1757 s
总结:
运行很慢,平均插入一万条需要耗时7s,
那么一千万条, 预计需要7000s 。 ( 117 min , 即将近两个小时 。。 )
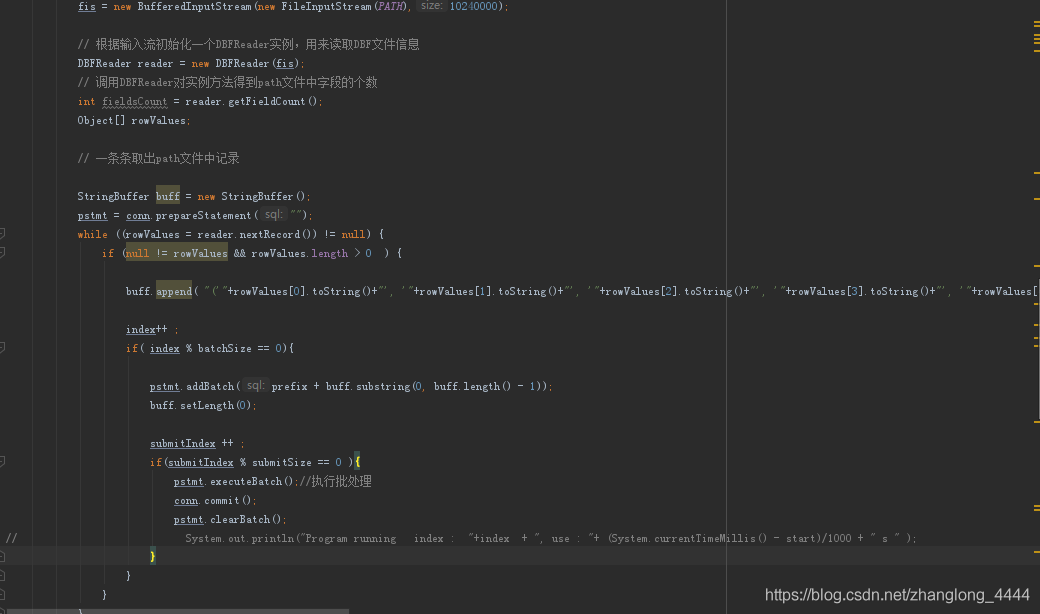
方式二: 将sql中的多个value值,拼在一起,进行插入操作。
实例:
insert into `tableName` (`id`,`name`) values ('1', '张三') ;
insert into `tableName` (`id`,`name`) values ('2', '李斯') ;
insert into `tableName` (`id`,`name`) values ('3', '王五') ;
变成:
insert into `tableName` (`id`,`name`) values ('1', '张三') , ('2', '李斯') , ('3', '王五') ;
代码片段截图:
运行结果分析:
batchSize : 多少条数据,拼成一条SQL
submitSize : 多少条SQL提交一次
处理数据完成 ==> batchSize : 500 , submitSize: 1 插入数据总条数 size : 10058624 total use : 190 s , 处理速度: 52940 条/s
处理数据完成 ==> batchSize : 500 , submitSize: 5 插入数据总条数 size : 10058624 total use : 144 s , 处理速度: 69851 条/s
处理数据完成 ==> batchSize : 500 , submitSize: 10 插入数据总条数 size : 10058624 total use : 137 s , 处理速度: 73420 条/s
处理数据完成 ==> batchSize : 1000 , submitSize: 1 插入数据总条数 size : 10058624 total use : 161 s , 处理速度: 62475 条/s
处理数据完成 ==> batchSize : 1000 , submitSize: 5 插入数据总条数 size : 10058624 total use : 134 s , 处理速度: 75064 条/s
处理数据完成 ==> batchSize : 1000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 133 s , 处理速度: 75628 条/s
处理数据完成 ==> batchSize : 5000 , submitSize: 1 插入数据总条数 size : 10058624 total use : 144 s , 处理速度: 69851 条/s
处理数据完成 ==> batchSize : 5000 , submitSize: 5 插入数据总条数 size : 10058624 total use : 136 s , 处理速度: 73960 条/s
处理数据完成 ==> batchSize : 5000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 134 s , 处理速度: 75064 条/s
处理数据完成 ==> batchSize : 10000 , submitSize: 1 插入数据总条数 size : 10058624 total use : 143 s , 处理速度: 70340 条/s
处理数据完成 ==> batchSize : 10000 , submitSize: 5 插入数据总条数 size : 10058624 total use : 138 s , 处理速度: 72888 条/s
处理数据完成 ==> batchSize : 10000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 137 s , 处理速度: 73420 条/s
处理数据完成 ==> batchSize : 100000 , submitSize: 1 插入数据总条数 size : 10058624 total use : 137 s , 处理速度: 73420 条/s
处理数据完成 ==> batchSize : 100000 , submitSize: 5 插入数据总条数 size : 10058624 total use : 136 s , 处理速度: 73960 条/s
处理数据完成 ==> batchSize : 100000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 135 s , 处理速度: 74508 条/s
处理数据完成 ==> batchSize : 1000000 , submitSize: 1 插入数据总条数 size : 10058624 total use : 148 s , 处理速度: 67963 条/s
总结:
最快处理速度 :
每1000条数据拼一条SQL语句,批量提交10条SQL语句,
插入数据总条数 size : 10058624 total use : 133 s , 处理速度: 75628 条/s
总结:
代码效率明显会比第一次提升N倍,推荐用这种方式进行插入。
注:
种方式会报异常,
Packet for query is too large (1117260 > 1048576). You can change this value on the server by setting the max_allowed_packet' variable.
原因&解决方案:
Sql语句过长,超过限制,需要调整 mysql 参数:
修改 /etc/my.comf 文件, 添加参数: max_allowed_packet = 128M 。( 大小可以自己测试 )
方式三、改写所有 insert into 语句为 insert delayed into
这个insert delayed不同之处在于:立即返回结果,后台进行处理插入。

测试速度:
处理数据完成 ==> batchSize : 1000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 138 s , 处理速度: 72888 条/s
处理数据完成 ==> batchSize : 1000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 139 s , 处理速度: 72364 条/s
总结:
性能并没有发现明显提升...............
三、数据库参数优化
这次修改了下面四个配置项:
1)将 innodb_flush_log_at_trx_commit 配置设定为0;按过往经验设定为0,插入速度会有很大提高。
-
当
innodb_flush_log_at_trx_commit=0时, log buffer将每秒一次地写入log file, 并且log file的flush(刷新到disk)操作同时进行. 此时, 事务提交是不会主动触发写入磁盘的操作. -
当
innodb_flush_log_at_trx_commit=1时(默认), 每次事务提交时, MySQL会把log buffer的数据写入log file, 并且将log file flush(刷新到disk)中去. -
当
innodb_flush_log_at_trx_commit=2时, 每次事务提交时, MySQL会把log buffer的数据写入log file, 但不会主动触发flush(刷新到disk)操作同时进行. 然而, MySQL会每秒执行一次flush(刷新到disk)操作.然而, 每秒flush并不能确保100%每秒发生, 因为os调度问题.
默认的1可以获得更好地数据安全, 但性能会打折扣. 不过非1时, 在遇到crash可能会丢失1秒的事务; 设置为0时, 任何mysqld进程crash会丢失上1秒的事务; 设置为2时, 任何os crash或者机器掉电会丢失上1秒的事务; InnoDB的crash recovery运行时会忽略这些数据.
2)将 innodb_autoextend_increment 配置由于默认8M 调整到 128M
此配置项作用主要是当tablespace 空间已经满了后,需要MySQL系统需要自动扩展多少空间,每次tablespace 扩展都会让各个SQL 处于等待状态。增加自动扩展Size可以减少tablespace自动扩展次数。
3)将 innodb_log_buffer_size 配置由于默认1M 调整到 16M
此配置项作用设定innodb 数据库引擎写日志缓存区;将此缓存段增大可以减少数据库写数据文件次数。
4)将 innodb_log_file_size 配置由于默认 8M 调整到 128M
此配置项作用设定innodb 数据库引擎UNDO日志的大小;从而减少数据库checkpoint操作。
经过以上调整,系统插入速度由于原来10分钟几万条提升至1秒1W左右;注:以上参数调整,需要根据不同机器来进行实际调整。特别是 innodb_flush_log_at_trx_commit、innodb_log_buffer_size和 innodb_log_file_size 需要谨慎调整;因为涉及MySQL本身的容灾处理。
5)修改 max_allowed_packet
sql语句过长会报错,增加长度。
最终修改参数:
max_allowed_packet = 128M
innodb_flush_log_at_trx_commit = 0
innodb_log_buffer_size = 16M
innodb_autoextend_increment = 128M
innodb_log_file_size = 128M
innodb_buffer_pool_size = 4096M
测试运行结果:
处理数据完成 ==> batchSize : 1000 , submitSize: 1 插入数据总条数 size : 10058624 total use : 134 s , 处理速度: 75064 条/s
处理数据完成 ==> batchSize : 1000 , submitSize: 5 插入数据总条数 size : 10058624 total use : 129 s , 处理速度: 77973 条/s
处理数据完成 ==> batchSize : 1000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 128 s , 处理速度: 78583 条/s
处理数据完成 ==> batchSize : 10000 , submitSize: 1 插入数据总条数 size : 10058624 total use : 139 s , 处理速度: 72364 条/s
处理数据完成 ==> batchSize : 10000 , submitSize: 5 插入数据总条数 size : 10058624 total use : 138 s , 处理速度: 72888 条/s
处理数据完成 ==> batchSize : 10000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 138 s , 处理速度: 72888 条/s
处理数据完成 ==> batchSize : 100000 , submitSize: 1 插入数据总条数 size : 10058624 total use : 137 s , 处理速度: 73420 条/s
处理数据完成 ==> batchSize : 100000 , submitSize: 5 插入数据总条数 size : 10058624 total use : 136 s , 处理速度: 73960 条/s
处理数据完成 ==> batchSize : 100000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 135 s , 处理速度: 74508 条/s
四、更换数据库表引擎
1、采用MyISAM 数据引擎
建表语句:
DROP TABLE IF EXISTS `DBF_MyISAM`;
CREATE TABLE `DBF_MyISAM` (
`GDDM` varchar(255) DEFAULT NULL,
`GDXM` varchar(255) DEFAULT NULL,
`BS` varchar(255) DEFAULT NULL,
`MJBH` varchar(255) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
执行效果: ( 最快用时97 s )
处理数据完成 ==> batchSize : 1000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 97 s , 处理速度: 103697 条/s
处理数据完成 ==> batchSize : 5000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 106 s , 处理速度: 94892 条/s
处理数据完成 ==> batchSize : 10000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 107 s , 处理速度: 94005 条/s
处理数据完成 ==> batchSize : 100000 , submitSize: 10 插入数据总条数 size : 10058624 total use : 107 s , 处理速度: 94005 条/s
总结: 采用MyISAM 数据引擎 性能上会比用InnoDB 快 ,性能提升 25% 左右。
最快时间为97s ,如果去除掉读取文件的时间19s ,
插入10058624 (一千零五万八)条数据,只需要 78 s 。 因机器、网络不同,时间略有差异。
分区,多线程,读写分离等技术都可以提高数据插入数据,本篇文章先不做概述
如果有不正确或者更好的解决方案, 欢迎指正,不胜感谢.......
COME FROM :https://blog.csdn.net/zhanglong_4444/article/details/86743371