darknet的cfg文件中有一个配置参数: burn_in
burn_in=1000
这个参数在caffe中是没有的,一旦设置了这个参数,当update_num小于burn_in时,不是使用配置的学习速率更新策略,而是按照下面的公式更新
lr = base_lr * power(batch_num/burn_in,pwr)
其背后的假设是:全局最优点就在网络初始位置附近,所以训练开始后的burn_in次更新,学习速率从小到大变化。update次数超过burn_in后,采用配置的学习速率更新策略从大到小变化,显然finetune时可以尝试。
————————————————
版权声明:本文为CSDN博主「z0n1l2」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/z0n1l2/article/details/82959455
darknet-yolov3 burn_in learning_rate policy
darknet-yolov3中的learning_rate是一个超参数,调参时可通过调节该参数使模型收敛到一个较好的状态。
在cfg配置中的呈现如下图:

我这里随便设了一个值。
接下来说一下burn_in和policy.
这两者在代码中的呈现如下所示:
float get_current_rate(network *net)
{
size_t batch_num = get_current_batch(net);
int i;
float rate;
if (batch_num < net->burn_in) //当batch_num小于burn_in时,返回如下learning_rate
return net->learning_rate * pow((float)batch_num / net->burn_in, net->power);
switch (net->policy) {//当大于burn_in时,按如下方式,原配值中给的是STEPS
case CONSTANT:
return net->learning_rate;
case STEP:
return net->learning_rate * pow(net->scale, batch_num/net->step);
case STEPS:
rate = net->learning_rate; for(i = 0; i < net->num_steps; ++i){
if(net->steps[i] > batch_num) return rate;
rate *= net->scales[i];
}
return rate;
case EXP:
return net->learning_rate * pow(net->gamma, batch_num);
case POLY:
return net->learning_rate * pow(1 - (float)batch_num / net->max_batches, net->power);
case RANDOM:
return net->learning_rate * pow(rand_uniform(0,1), net->power);
case SIG:
return net->learning_rate * (1./(1.+exp(net->gamma*(batch_num - net->step))));
default:
fprintf(stderr, "Policy is weird!
");
return net->learning_rate;
}
}
这里我做了一些调整。
调整依据是:发现自己设置的学习率和burn_in结束时的学习率总是有很大差异,造成loss变化出现停滞,或者剧烈抖动。
调整办法:让steps的起始学习率=burn_in结束时的学习率。
实现如下:
float last_rate;
float get_current_rate(network *net)
{
size_t batch_num = get_current_batch(net);
int i;
float rate;
if (batch_num < net->burn_in)
{
/******************************************************/
last_rate = net->learning_rate * pow((float)batch_num / net->burn_in, net->power);
/*****************************************************/
return net->learning_rate * pow((float)batch_num / net->burn_in, net->power);
}
switch (net->policy) {
case CONSTANT:
return net->learning_rate;
case STEP:
return net->learning_rate * pow(net->scale, batch_num/net->step);
case STEPS:
//rate = net->learning_rate;
rate = last_rate;
for(i = 0; i < net->num_steps; ++i){
if(net->steps[i] > batch_num) return rate;
rate *= net->scales[i];
}
return rate;
case EXP:
return net->learning_rate * pow(net->gamma, batch_num);
case POLY:
return net->learning_rate * pow(1 - (float)batch_num / net->max_batches, net->power);
case RANDOM:
return net->learning_rate * pow(rand_uniform(0,1), net->power);
case SIG:
return net->learning_rate * (1./(1.+exp(net->gamma*(batch_num - net->step))));
default:
fprintf(stderr, "Policy is weird!
");
return net->learning_rate;
}
}
原文地址:https://www.codeprj.com/blog/b9a0f01.html
YOLOv3官方版本的学习率配置信息在模型配置文件 *.cfg file 中:
learning_rate: 标准学习率
burn_in: 学习率从 0 上升到 learning_rate 的 batch 数目
max_batches: 需要进行训练的 batch 数目
policy: 学习率调度的策略
steps: 在何处进行学习率衰减
scales: 学习率进行衰减的倍数
这个YOLO关于学习率调度的的代码设置在 train.py 中,设置标准学习率和最终的学习率分别为参数hyp['lr0'] 和 hyp['lrf'],其中最终的学习率 final LR = hyp['lr0'] * (10 ** hyp['lrf'])。例如,标准学习率 hyp['lr0'] = 0.001, hyp['lrf'] = -2,因此 final LR = 0.00001.下面这张图显示了Pytorch中的两个常用的学习率调度方法。其中YOLO原版采用的是 MultiStepLR scheduler。我们可以根据自己需要对学习率进行调整。

YOLO会对前面1000个batch进行学习率warm up:
# SGD burn-in
if epoch == 0 and i <= n_burnin:
lr = hyp['lr0'] * (i / n_burnin) ** 4
for x in optimizer.param_groups:
x['lr'] = lr
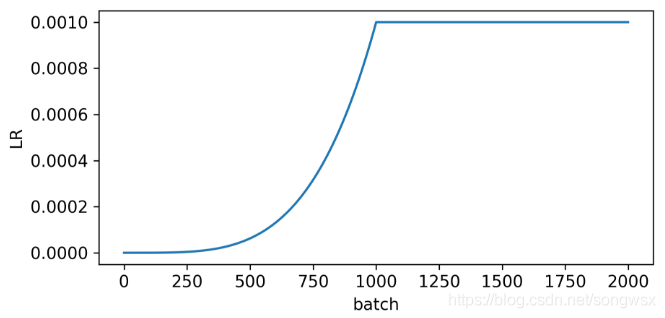
不过代码里默认是注释掉了,如果使用的话需要打开以下
————————————————
版权声明:本文为CSDN博主「松菇」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/songwsx/article/details/102656935

