一、通配符与正则表达式的区别:
1.通配符是对文件名进行匹配的;正则表达式是对文件的内容进行匹配的
2.正则表达式是要结合grep、sed、awk使用的
3.grep命令
作用:对文件中的内容进行逐行过滤
格式: grep [选项] 匹配内容 文件
选项:
-v 取反
-o 仅仅显示所有匹配到的内容
--color 将匹配到的内容着色
-i 忽略大小写
二、正则中的元字符
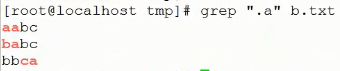
1 、. 表示任意一个字符(可以是空格、逗号、字母、数字……)
示例: .a
说明:
1) 表示匹配两个字符,第一个是任意字符、第二个是a
2)在一行的任何位置匹配都可以
2、[ ]表示范围内的单个字符
用字母和数字的方式表示
1)[12345] 表示1 或2 或3 或4 或5
2)[1234567890] 表示 任意一个数字
3)[a-z] 表示任意一个小写字母
4)[A-Z] 表示任意一个大写字母
5)[a-zA-Z] 表示任意字母
6)[0-9a-zA-Z] 表示所有数字和字母的任一个
示例:
过滤出包含数字的行:

用字符集的方式表示
1)[:space:] 表示一个空格
2)[:digit:] 表示0-9全部十个数字,等价于 0123456789,而不是[0123456789]
[[:digit:]] 表示任意一个数字
3)[:lower:] 表示全部26个小写字母,等价于 abcdef……z
[[:lower:]] 表示任意一个小写字母
4)[:upper:] 表示全部26个大写字母,等价于 ABCDEF……Z
[[:upper:]] 表示任意一个大写字母
5)[:alpha:] 表示全部52个字母(大小写)
[[:alpha:]] 表示任意一个字母
6)[:punct:] 表示全部的标点符号
[[:punct:]] 表示任意 标点符号
7)[:alnum:] 表示全部数字+字母(62个)
[[:alnum:]] 表示任意一个数字或字母
补充:
[[:digit:][:lower:]] 表示任意一个数字或小写字母
思考:匹配空格或数字或大写字母?
[[:space:][:digit:][:upper:]]
3、[^]匹配范围以外的任意一个字符
grep "[357]" a.txt 说明:过滤包含3或5或7任意一个数字的行
grep "[^357]" a.txt 说明:如果一行中有3、5、7以外的字符,则匹配字符成功;如果一行仅有3或5或7或3、5、7三个数字任意组合,则该行不会被匹配。
grep -v "[357]" a.txt 说明:过滤出不包含3或5或7的行
4、显示匹配到的行及前后n行
1) -A n 显示匹配到的行及后面n行
2) -B n 显示匹配到的行及前面n行
3) -C n 显示匹配到的行及前n行和后n行
5、次数匹配
* 表示其前面的字符出现任意次数的情况,(0,1,n)
.* 表示任意长度的任意字符
? 表示其前面的字符出现最多一次的情况
{m,n} 表示其前面的字符出现最少m次,最多n次的情况
{3,} 表示其前面的字符出现最少3次
{,5} 表示其前面的字符出现最多5次
示例:
a* 表示任意多个a(可是0 1 n)
ab* 表示a后面的b出现任意次
a*b 表示匹配b前面有任意个a的情况
grep "a.*b" fileName 表示过滤出含有a,b的行,a在前,b在后

6、位置锚定
^ 表示以什么为开头的行
$ 表示以什么为结尾的行
^$ 表示空白行
< 表示单词首部
> 表示单词尾部
1)过滤出包含root的行
grep "root" a.txt
2)过滤出以root开头的行
grep "^root" a.txt
3)过滤出以root结尾的行
grep "root$" a.txt
4)过滤出以空格开头的行
grep "^[[:space:]]" a.txt
5)过滤出以多个空格后面是root为开头的行
grep "^[[:space:]]{1,}root" a.txt
6)过滤出空白行
grep "^$" a.txt
7、分组
( ) 将一个内容当做一个整体看待
1 表示引用前面的第一个分组
2 表示引用前面的第二个分组
示例:从a.txt中过滤出 出现两个相同数字的行
grep "([[:digit:]]).*1" a.txt

8、扩展正则表达式
grep -E 匹配内容 文件
egrep 匹配内容 文件
扩展内容:
1) 扩展匹配模式不需要对?,{},()进行转义
2) 次数匹配增加一个模式:+ 匹配前面的一个字符至少一次
示例:匹配文件a.txt中 a前至少有一个b的行
grep "b{1,}a" a.txt
grep -E "b{1,}" a.txt
egrep "b{1,}a" a.txt
egrep "b+a" a.txt
grep -E "b+a" a.txt
3)| 增加或语法
示例:从文件a.txt中过滤出cat和Cat
grep -E "(c|C)at" a.txt
grep -E "cat | Cat" a.txt
4)位置锚定与扩展表达式用法一致