一.Anaxonda的安装
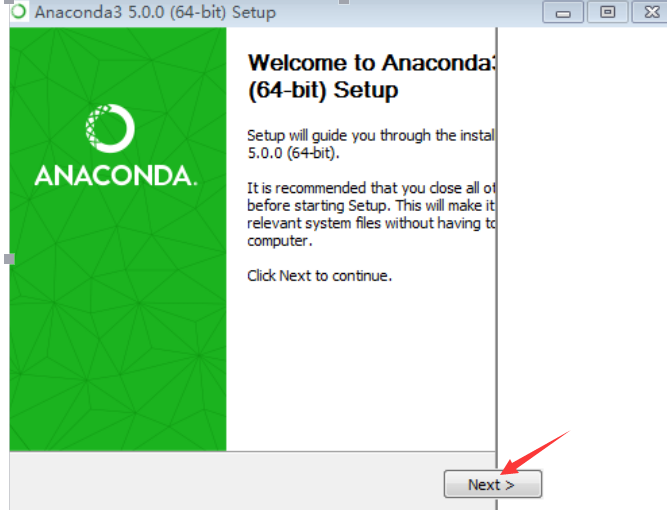
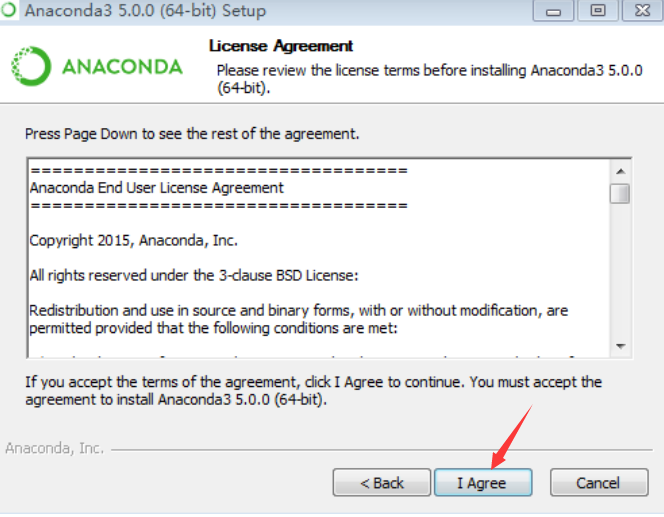
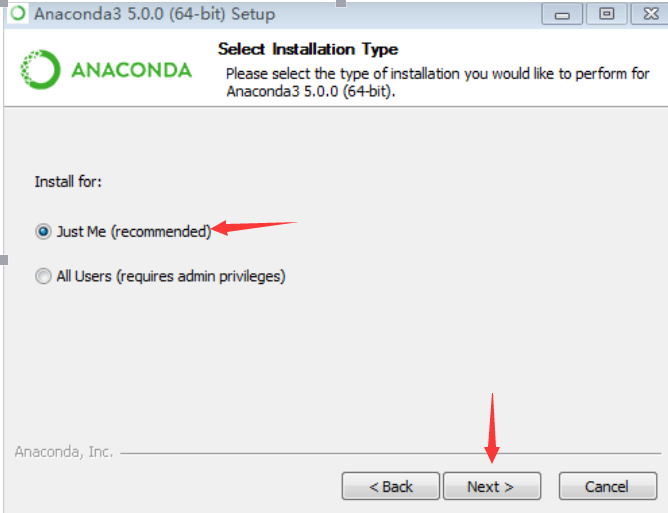
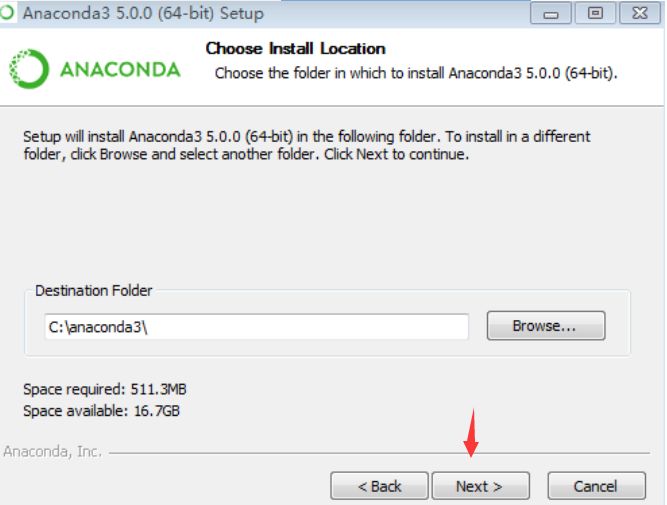
1.双击Anaconda3-5.0.0-Windows-x86_64.exe文件

2.下一步

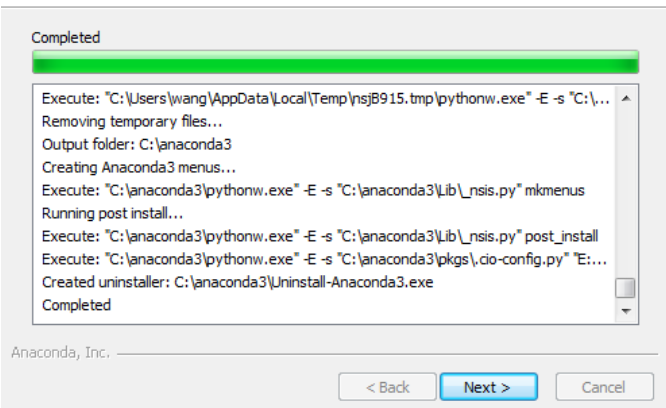
3.
①
打开cmd窗口,录入jupyter notebook指令,
如果没有显示找不到命令且没有报错即可表示安装成功!
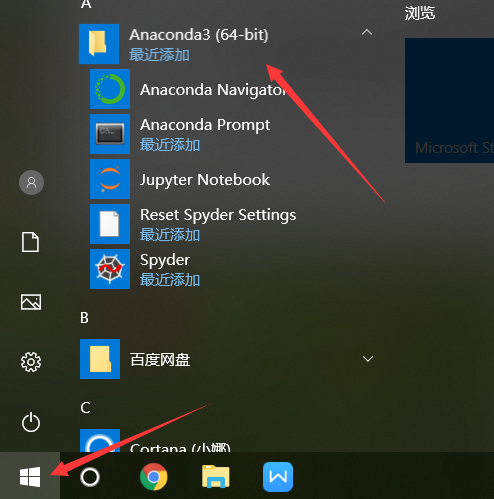
②在开始菜单中显示
二.HTTP 与HTTPS
1.HTTP协议
①概念
1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,
是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
2.白话概念:
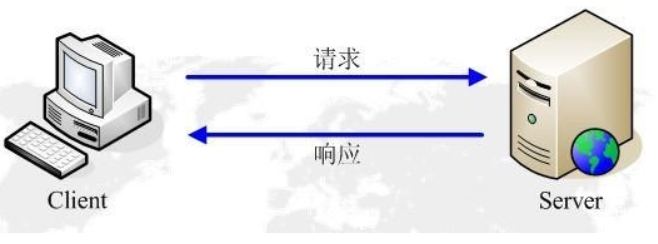
HTTP协议就是服务器(Server)和客户端(Client)之间进行数据交互(相互传输数据)的一种形式。
②HTTP工作原理
③注意事项
- HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。 - HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,
并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。 - HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,
任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。 - HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。
缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。
另一方面,在服务器不需要先前信息时它的应答就较快。
④HTTP之URL
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。
URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息 URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。
以下面这个URL为例,介绍下普通URL的各部分组成:http://www.aspxfans.com:8080/news/index.
asp?boardID=5&ID=24618&page=1#name从上面的URL可以看出,一个完整的URL包括以下几部分: - 协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,
如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符 - 域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用 - 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,
如果省略端口部分,将采用默认端口 - 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。
虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/” - 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,
则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,
那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。
文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名 - 锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分 - 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。
本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,
参数与参数之间用“&”作为分隔符。
⑤HTTP之Request

报文头:常被叫做请求头,请求头中存储的是该请求的一些主要说明(自我介绍)。服务器据此获取客户端的信息。 常见的请求头: accept:浏览器通过这个头告诉服务器,它所支持的数据类型 Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集 Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式 Accept-Language:浏览器通过这个头告诉服务器,它的语言环境 Host:浏览器通过这个头告诉服务器,想访问哪台主机 If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间 Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链 Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接 X-Requested-With: XMLHttpRequest 代表通过ajax方式进行访问 User-Agent:请求载体的身份标识 报文体:常被叫做请求体,请求体中存储的是将要传输/发送给服务器的数据信息。
⑥HTTP之Response

HTTP的响应状态码由5段组成:
1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急...
2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
相应头:响应的详情展示 常见的相应头信息: Location: 服务器通过这个头,来告诉浏览器跳到哪里 Server:服务器通过这个头,告诉浏览器服务器的型号 Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式 Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度 Content-Language: 服务器通过这个头,告诉浏览器语言环境 Content-Type:服务器通过这个头,告诉浏览器回送数据的类型 Refresh:服务器通过这个头,告诉浏览器定时刷新 Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据 Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的 Expires: -1 控制浏览器不要缓存 Cache-Control: no-cache Pragma: no-cache 相应体:根据客户端指定的请求信息,发送给客户端的指定数据
2.HTTPS协议
①概念
1.官方概念: HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,
HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。
2.白话概念:
加密安全版的HTTP协议。
②加密技术
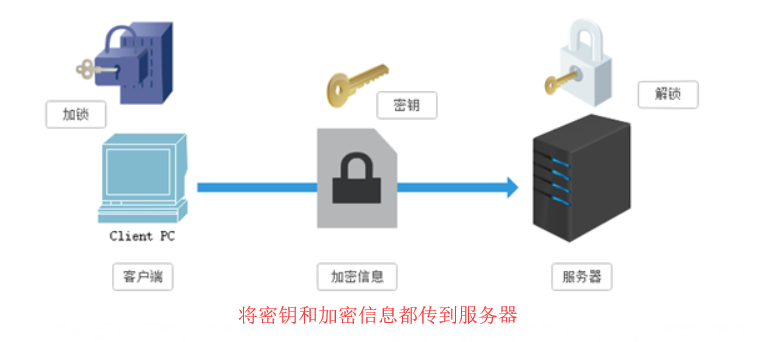
a.对称秘钥加密(SSL)
缺点:
潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。
b.非对称秘钥加密技术
缺点:
第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,
而不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
第二个是:非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度

c.证书加密机制
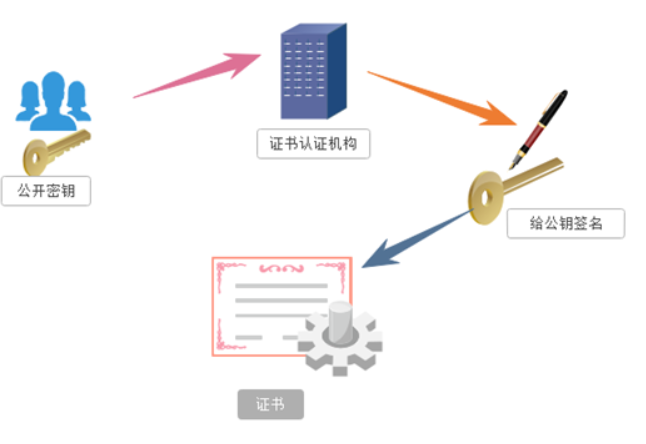
1:服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,
数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,
然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起
2:服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书
中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,
证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,
客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
三.爬虫初始
1.概念
爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程
2.爬虫的分类
通用爬虫:获取一整张页面数据
聚焦爬虫:根据指定的需求获取页面中指定的局部数据
增量式爬虫:用来监测网站数据更新的情况。爬取网站最新更新出来的数据。
反爬机制:网站可以采取先关的技术手段或者策略阻止爬虫程序进行网站数据的爬取
反反爬策略:让爬虫程序通过破击反爬机制获取数据
robots协议:防君子不妨小人
3.jupyter的快捷键
向上插入一个cell:a 向下插入一个cell:b 删除cell:x 将code切换成markdown:m 将markdown切换成code:y 运行cell:shift+enter 查看帮助文档:shift+tab 自动提示:tab
4.requests模块的使用
下载:pip install requests
作用:就是用来模拟浏览器上网的。
特点:简单,高效
old:urllib
requests模块的使用流程:
指定url
发起请求
获取响应数据
持久化存储
5.示例
①基于requests模块的get请求
#爬取搜狗指定词条搜索后的页面数据
import requests wd = input('enter a word:') url = 'https://www.sogou.com/web' #参数的封装 param = { 'query':wd } #UA伪装 headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } response = requests.get(url=url,params=param,headers=headers) #手动修改响应数据的编码 response.encoding = 'utf-8' page_text = response.text fileName = wd + '.html' with open(fileName,'w',encoding='utf-8') as fp: fp.write(page_text) print(fileName,'爬取成功!!!')
②基于requests模块的post请求
#登录豆瓣电影,爬取登录成功后的页面数据
import requests import os url = 'https://accounts.douban.com/login' #封装请求参数 data = { "source": "movie", "redir": "https://movie.douban.com/", "form_email": "15027900535", "form_password": "bobo@15027900535", "login": "登录", } #自定义请求头信息 headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', } response = requests.post(url=url,data=data) page_text = response.text with open('./douban111.html','w',encoding='utf-8') as fp: fp.write(page_text)
③基于requests模块ajax的get请求
④基于requests模块ajax的post请求
#爬取北京肯德基所有的餐厅位置信息(1-8页)
import requests import json for i in range(1,9): url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' data = { 'cname': '', 'pid': '', 'keyword': '北京', 'pageIndex': i, 'pageSize': '10', } headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } response = requests.post(url=url, headers=headers,data=data) json_text = response.text dict = json.loads(json_text) for i in dict['Table1']: # print(i['addressDetail']) with open('kfc.txt','a',encoding='utf-8') as f: f.write(i['addressDetail'] + " ") print('ok')