文章转载自:https://mp.weixin.qq.com/s/7VQd5sKt_PH56PFnCrUOHQ
1、什么是索引生命周期
在基于日志、指标、实时时间序列的大型系统中,集群的索引也具备类似上图中相通的属性,一个索引自创建之后,不可能无限期的存在下去, 从索引产生到索引“消亡”,也会经历:“生、老、病、死”的阶段。
我们把索引的“生、老、病、死”的全过程类比称为索引的生命周期。
2、什么是索引生命周期管理
由于自然规律,人会“不可逆转”的由小长到大,由大长到老,且理论上年龄一般不会超过 150 岁(吉尼斯世界纪录:122岁零164天)。
索引不是人,理论上:一旦创建了索引,它可以一直存活下去(假定硬件条件允许,寿命是无限的)。
索引创建后,它自身是相对静态的,没有“自然规律”牵引它变化,若放任其成长,它只会变成一个数据量极大的臃肿的“大胖子”。
这里可能就会引申出来问题:若是时序数据的索引,随着时间的推移,业务索引的数据量会越来越大。但,基于如下的因素:
- 集群的单个分片最大文档数上限:2 的 32 次幂减去 1(20亿左右)。
- 索引最佳实践官方建议:分片大小控制在30GB-50GB,若索引数据量无限增大,肯定会超过这个值。
- 索引大到一定程度,当索引出现健康问题,会导致真个集群核心业务不可用。
- 大索引恢复的时间要远比小索引恢复慢的多得多。
- 索引大之后,检索会很慢,写入和更新也会受到不同程度的影响。
- 某些业务场景,用户更关心最近3天、最近7天的业务数据,大索引会将全部历史数据汇集在一起,不利于这种场景的查询
非常有必要对索引进行管理起来,不再放任其“野蛮长成体弱多病、潜在风险极大的大胖子”,而是限制其分阶段、有目标的、有规律的生长。
这种分阶段、有目标的操作和实现,我们称为索引生命周期管理。
3、索引生命周期管理的历史演变
索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入,在 6.7 版本正式推出的一项功能。
ILM 是 Elasticsearch 的一部分,主要用来帮助用户管理索引。
没有 ILM 之前索引生命周期管理基于:rollover + curator 实现。
ILM 是早些年呼声非常高的功能之一,我印象中 2017 年南京的 meetup 中,就有公司说实现了类似的功能。
Kibana 7.12.0 索引生命周期管理配置界面如下图所示:
4、索引生命周期管理的前提
本文演示试用版本:Elasticesarch:7.12.0,Kibana:7.12.0。
集群规模:3节点,属性(node_roles)设置分别如下:
节点 node-022:主节点+数据节点+热节点(Hot)。
节点 node-023:主节点+数据节点+温节点(Warm)。
节点 node-024:主节点+数据节点+冷节点(Cold)。
4.1 冷热集群架构
冷热架构也叫热暖架构,是“Hot-Warm” Architecture的中文翻译。
冷热架构本质是给节点设置不同的属性,让每个节点具备了不同的属性。
为演示 ILM,需要首先配置冷热架构,三个节点在 elasticsearch.yml 分别设置的属性如下:
- node.attr.box_type: hot
- node.attr.box_type: warm
- node.attr.box_type: cold
拿舆情数据举例,通俗解读如下:
- 热节点(Hot):存放用户最关心的热数据。
- 温节点(Warm):存放前一段时间沉淀的热数据,现在不再热了。
- 冷节点(Cold):存放用户不太关心或者关心优先级低的冷数据,很久之前的热点事件。
如果磁盘数量不足,冷数据是待删除优先级最高的。
如果硬件资源不足,热节点优先配置为 SSD 固态盘。
检索优先级最高的是热节点的数据,基于热节点检索数据自然比基于全量数据响应时间要快。
4.2 rollover 滚动索引
实际Elasticsearch 5.X 之后的版本已经推出:Rollover API。Rollover API解决的是以日期作为索引名称的索引大小不均衡的问题。
Rollover API对于日志类的数据非常有用,一般我们按天来对索引进行分割(数据量更大还能进一步拆分),没有Rollover之前,需要在程序里设置一个自动生成索引的模板。
rollover 滚动索引实践一把:
# 1、创建基于日期的索引
PUT %3Cmy-index-%7Bnow%2Fd%7D-000001%3E
{
"aliases": {
"my-alias": {
"is_write_index": true
}
}
}
# 2、批量导入数据
PUT my-alias/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
{"index":{"_id":5}}
{"title":"testing 05"}
# 3、rollover 滚动索引
POST my-alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 5,
"max_primary_shard_size": "50gb"
}
}
GET my-alias/_count
# 4、在满足滚动条件的前提下滚动索引
PUT my-alias/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
# 5、检索数据,验证滚动是否生效
GET my-alias/_search
如上的验证结论是:
{
"_index" : "my-index-2021.05.30-000001",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"title" : "testing 05"
}
},
{
"_index" : "my-index-2021.05.30-000002",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"title" : "testing 06"
}
}
_id 为 6 的数据索引名称变成了:my-index-2021.05.30-000002,实现了 后缀 id 自增。
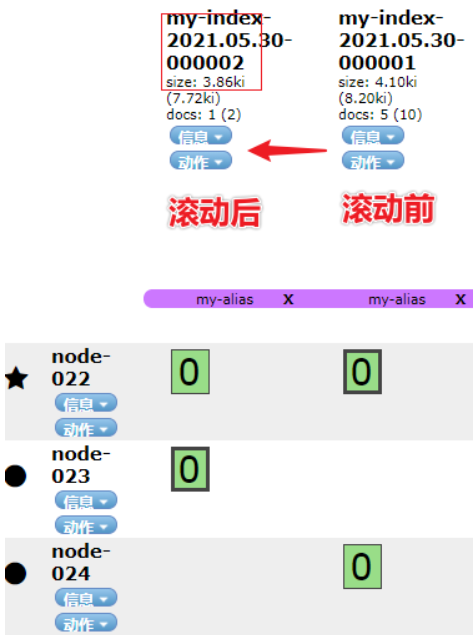
这里要强调下,索引滚动变化的三个核心条件:
- "max_age": "7d", 最长期限 7d,超过7天,索引会实现滚动。
- "max_docs": 5, 最大文档数 5,超过 5个文档,索引会实现滚动(测试需要,设置的很小)。
- "max_primary_shard_size": "50gb",主分片最大存储容量 50GB,超过50GB,索引就会滚动。
注意,三个条件是或的关系,满足其中一个,索引就会滚动。
4.3 shrink 压缩索引
压缩索引的本质:在索引只读等三个条件的前提下,减少索引的主分片数。
# 设置待压缩的索引,分片设置为5个。
PUT kibana_sample_data_logs_ext
{
"settings": {
"number_of_shards":5
}
}
# 准备索引数据
POST _reindex
{
"source":{
"index":"kibana_sample_data_logs"
},
"dest":{
"index":"kibana_sample_data_logs_ext"
}
}
# shrink 压缩之前的三个必要条件
PUT kibana_sample_data_logs_ext/_settings
{
"settings": {
"index.number_of_replicas": 0,
"index.routing.allocation.require._name": "node-024",
"index.blocks.write": true
}
}
# 实施压缩
POST kibana_sample_data_logs_ext/_shrink/kibana_sample_data_logs_shrink
{
"settings": {
"index.number_of_replicas": 0,
"index.number_of_shards": 1,
"index.codec": "best_compression"
},
"aliases": {
"kibana_sample_data_logs_alias": {}
}
}
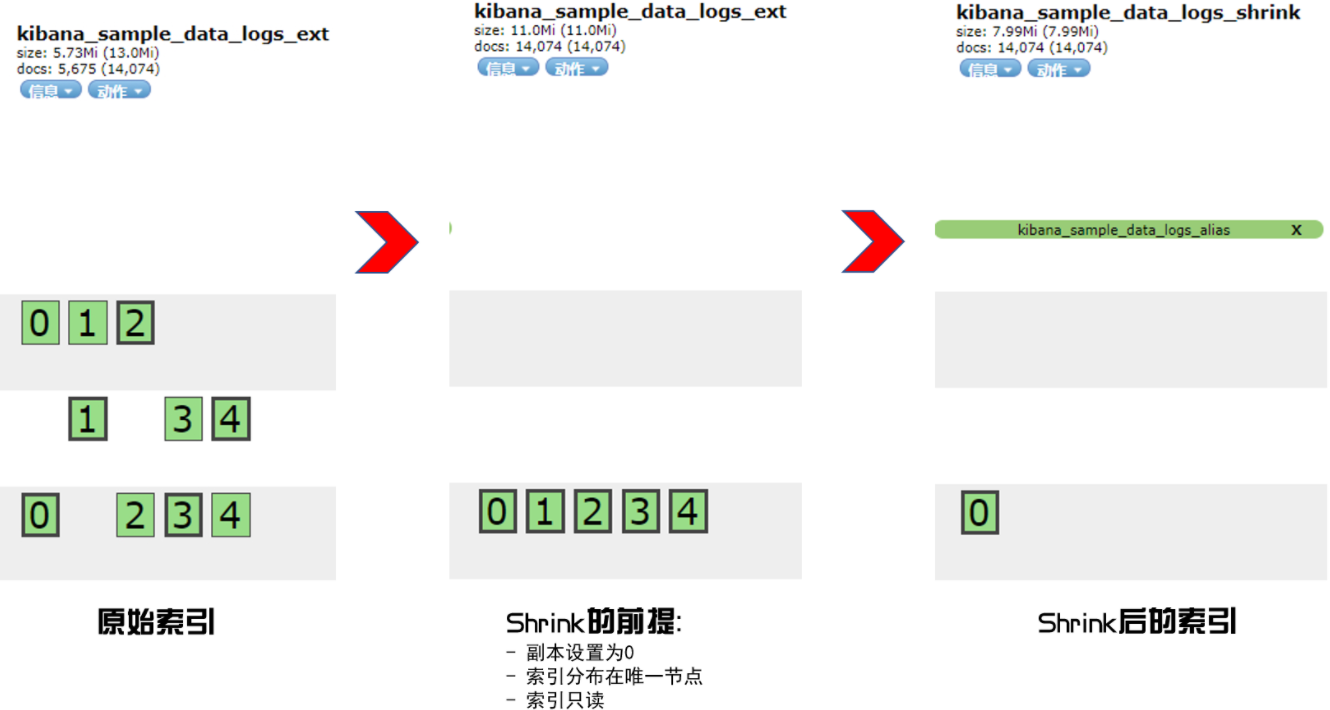
强调一下三个压缩前的条件,缺一不可:
- "index.number_of_replicas": 0 副本设置为 0。
- "index.routing.allocation.require._name": "node-024" 分片数据要求都集中到一个独立的节点。
- "index.blocks.write": true 索引数据只读。
4.4 Frozen 冷冻索引
为高效检索,核心业务索引都会保持在内存中,意味着内存使用率会变得很高。
对于一些非业务必须、非密集访问的某些索引,可以考虑释放内存,仅磁盘存储,必要的时候再还原检索。
这时候,就会用到 Frozen 冷冻索引。除了在内存中维护其元数据,冻结索引在集群上几乎没有开销,并且冷冻索引是只读的。
具体使用如下:
# 冷冻索引
POST kibana_sample_data_logs_shrink/_freeze
# 冷冻后,不能写入
POST kibana_sample_data_logs_shrink/_doc/1
{
"test":"12111"
}
# 冷冻后,能检索,但不返回具体数据,只返回0。
POST kibana_sample_data_logs_shrink/_search
# 解除冷冻
POST kibana_sample_data_logs_shrink/_unfreeze
# 解除冷冻后,可以检索和写入了
POST kibana_sample_data_logs_shrink/_search
综合上述拆解分析可知:
有了:冷热集群架构,集群的不同节点有了明确的角色之分,冷热数据得以物理隔离,SSD 固态盘使用效率会更高。
有了:rollover 滚动索引,索引可以基于文档个数、时间、占用磁盘容量滚动升级,实现了索引的动态变化。
有了:Shrink 压缩索引、Frozen 冷冻索引,索引可以物理层面压缩、冷冻,分别释放了磁盘空间和内存空间,提高了集群的可用性。
除此之外,还有:Force merge 段合并、Delete 索引数据删除等操作,索引的“生、老、病、死”的全生命周期的更迭,已然有了助推器。
如上指令单个操作,非常麻烦和繁琐,有没有更为快捷的方法呢?
有的!
第一:命令行可以 DSL 大综合实现。
第二:可以借助 Kibana 图形化界面实现。
下面两小节会结合实例解读。
5、Elasticsearch ILM 实战
5.1 核心概念:不同阶段(Phrase)的功能点(Acitons)

注意:仅在 Hot 阶段可以设置:Rollover 滚动。
5.2 各生命周期 Actions 设定
5.2.1 Hot 阶段
- 基于:max_age=3天、最大文档数为5、最大size为:50gb rollover 滚动索引。
- 设置优先级为:100(值越大,优先级越高)。
5.2.2 Warm 阶段
- 实现段合并,max_num_segments 设置为1.
- 副本设置为 0。
- 数据迁移到:warm 节点。
- 优先级设置为:50。
5.2.3 Cold 阶段
- 冷冻索引
- 数据迁移到冷节点
5.2.4 Delete 阶段
- 删除索引
关于触发滚动的条件:
- Hot 阶段的触发条件:手动创建第一个满足模板要求的索引。
- 其余阶段触发条件:min_age,索引自创建后的时间。
时间类似:业务里面的 热节点保留 3 天,温节点保留 7 天,冷节点保留 30 天的概念。
5.3 DSL 实战索引生命周期管理
# step1: 前提:演示刷新需要
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
# step2:测试需要,值调的很小
PUT _ilm/policy/my_custom_policy_filter
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "3d",
"max_docs": 5,
"max_size": "50gb"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "15s",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"allocate": {
"require": {
"box_type": "warm"
},
"number_of_replicas": 0
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "30s",
"actions": {
"allocate": {
"require": {
"box_type": "cold"
}
},
"freeze": {}
}
},
"delete": {
"min_age": "45s",
"actions": {
"delete": {}
}
}
}
}
}
# step3:创建模板,关联配置的ilm_policy
PUT _index_template/timeseries_template
{
"index_patterns": ["timeseries-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "my_custom_policy_filter",
"index.lifecycle.rollover_alias": "timeseries",
"index.routing.allocation.require.box_type": "hot"
}
}
}
# step4:创建起始索引(便于滚动)
PUT timeseries-000001
{
"aliases": {
"timeseries": {
"is_write_index": true
}
}
}
# step5:插入数据
PUT timeseries/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
# step6:临界值(会滚动)
PUT timeseries/_bulk
{"index":{"_id":5}}
{"title":"testing 05"}
# 下一个索引数据写入
PUT timeseries/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
核心步骤总结如下:
第一步:创建生周期 policy。
第二步:创建索引模板,模板中关联 policy 和别名。
第三步:创建符合模板的起始索引,并插入数据。
第四步: 索引基于配置的 ilm 滚动。
实现效果如下GIF动画(请耐心看完)
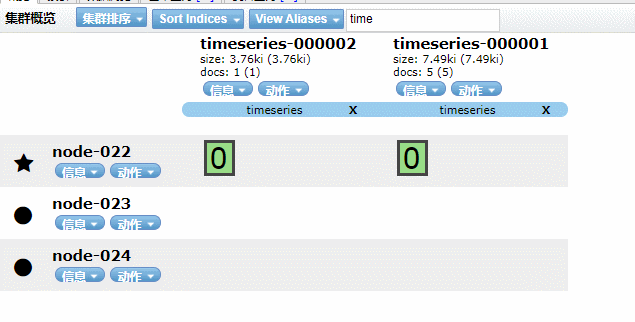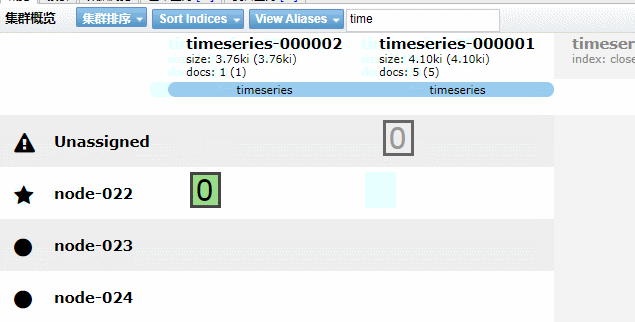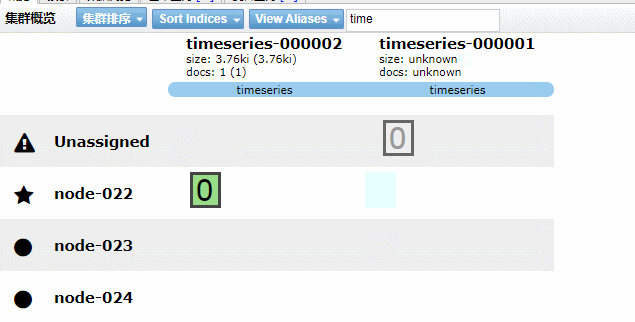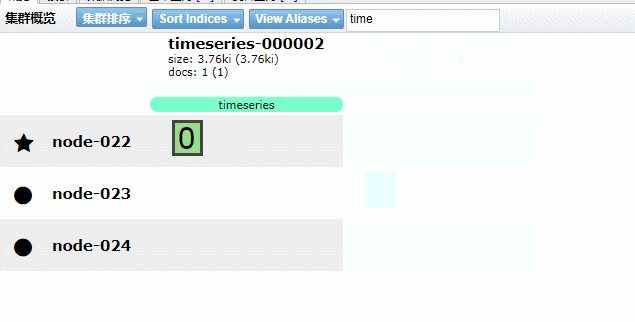
5.4、Kibana 图形化界面实现索引生命周期管理
步骤 1:配置 policy。

步骤 2:关联模板。
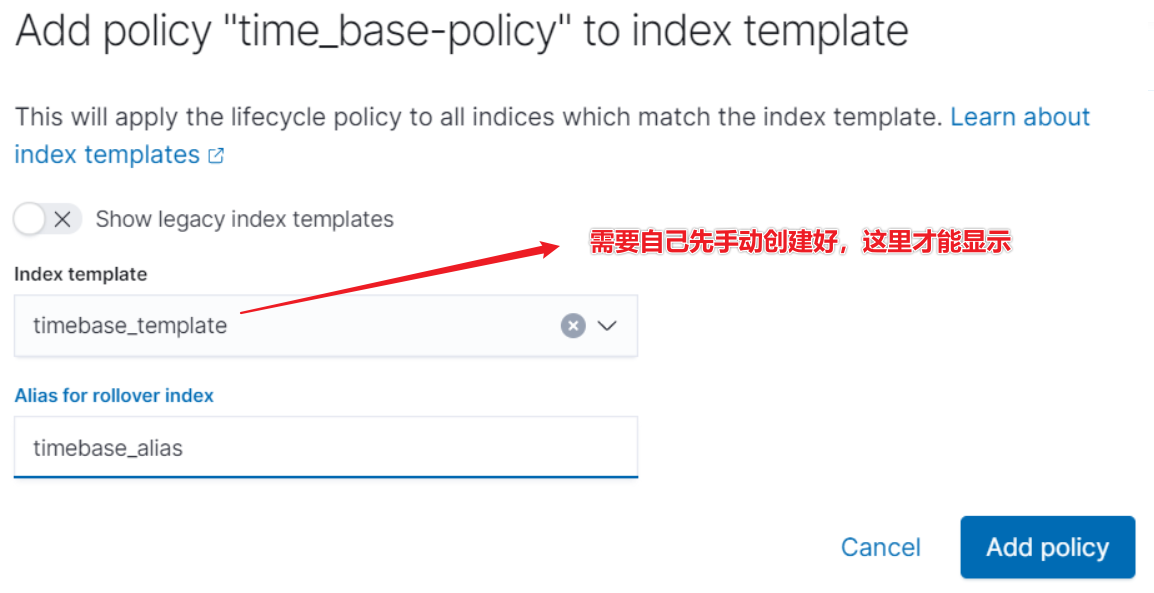
前提条件:
- 模板要自己 DSL 创建,以便关联。
PUT _index_template/timebase_template
{ "index_patterns": ["time_base-*"] }
- 创建起始索引,指定别名和写入。
PUT time_base-000001 { "aliases": { "timebase_alias": { "is_write_index": true } } }
6、小结
索引生命周期管理需要加强对三个概念的认知:
- 横向——Phrase 阶段:Hot、Warm、Cold、Delete 等对应索引的生、老、病、死。
- 纵向——Actions 阶段:各个阶段的动作。
- 横向纵向整合的Policy:实际是阶段和动作的综合体。
配置完毕Policy,关联好模板 template,整个核心工作就完成了80%。
剩下就是各个阶段 Actions 的调整和优化了。
实战表明:用 DSL 实现ILM 比图形化界面更可控、更便于问题排查。