1 Coredns CrashLoopBackOff 导致无法成功添加工作节点的问题
1.1 问题描述
kubeadm方式安装的k8s 1.14.1集群,使用一段时间后k8s-master-15-81机器重启docker和kubelet服务后,coredns无法工作了
[root@k8s-master-15-81 k8s_config]# kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE coredns-8686dcc4fd-4qswq 0/1 CrashLoopBackOff 15 40d coredns-8686dcc4fd-769bs 0/1 CrashLoopBackOff 15 40d kube-apiserver-k8s-master-15-81 1/1 Running 4 40d kube-apiserver-k8s-master-15-82 1/1 Running 0 40d kube-apiserver-k8s-master-15-83 1/1 Running 0 40d kube-controller-manager-k8s-master-15-81 1/1 Running 5 40d kube-controller-manager-k8s-master-15-82 1/1 Running 1 40d kube-controller-manager-k8s-master-15-83 1/1 Running 1 40d kube-flannel-ds-amd64-4fg7t 1/1 Running 0 40d kube-flannel-ds-amd64-bcl4j 1/1 Running 0 40d kube-flannel-ds-amd64-k6vp2 1/1 Running 0 40d kube-flannel-ds-amd64-lkjlz 1/1 Running 2 40d kube-flannel-ds-amd64-mb2lg 1/1 Running 0 40d kube-flannel-ds-amd64-nl9pn 1/1 Running 5 40d kube-proxy-4sbms 1/1 Running 2 40d kube-proxy-9v6fm 1/1 Running 0 40d kube-proxy-jsnkk 1/1 Running 5 40d kube-proxy-rvkmh 1/1 Running 0 40d kube-proxy-s4dfv 1/1 Running 0 40d kube-proxy-s8lws 1/1 Running 0 40d kube-scheduler-k8s-master-15-81 1/1 Running 5 40d kube-scheduler-k8s-master-15-82 1/1 Running 1 40d kube-scheduler-k8s-master-15-83 1/1 Running 1 40d kubernetes-dashboard-5f7b999d65-d7fpp 0/1 Terminating 0 18m kubernetes-dashboard-5f7b999d65-k759t 0/1 Terminating 0 21m kubernetes-dashboard-5f7b999d65-pmvkk 0/1 CrashLoopBackOff 2 43s [root@k8s-master-15-81 k8s_config]#
此时其他节点都是notready状态
[root@k8s-master-15-81 k8s_config]# kubectl get no NAME STATUS ROLES AGE VERSION k8s-master-15-81 Ready master 40d v1.14.1 k8s-master-15-82 NotReady master 40d v1.14.1 k8s-master-15-83 NotReady master 40d v1.14.1 k8s-node-15-84 NotReady <none> 40d v1.14.1 k8s-node-15-85 NotReady <none> 40d v1.14.1 k8s-node-15-86 NotReady <none> 40d v1.14.1 [root@k8s-master-15-81 k8s_config]#
初步诊断容器崩溃,我们需要进一步查看日志,使用“kubectl logs”:
这次我们获得了以下具体错误:
[root@k8s-master-15-81 ~]# kubectl -n kube-system logs coredns-8686dcc4fd-7fwcz #这是主要是日志 E1028 06:36:35.489403 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:322: Failed to list *v1.Namespace: Get https://10.96.0.1:443/api/v1/namespaces?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host E1028 06:36:35.489403 1 reflector.go:134] github.com/coredns/coredns/plugin/kubernetes/controller.go:322: Failed to list *v1.Namespace: Get https://10.96.0.1:443/api/v1/namespaces?limit=500&resourceVersion=0: dial tcp 10.96.0.1:443: connect: no route to host log: exiting because of error: log: cannot create log: open /tmp/coredns.coredns-8686dcc4fd-7fwcz.unknownuser.log.ERROR.20191028-063635.1: no such file or directory
[root@k8s-master-15-81 ~]# kubectl -n kube-system describe pod coredns-8686dcc4fd-4j5gv #这个日志没啥用 Name: coredns-8686dcc4fd-4j5gv Namespace: kube-system Priority: 2000000000 PriorityClassName: system-cluster-critical Node: k8s-master-15-81/192.168.15.81 Start Time: Mon, 28 Oct 2019 14:15:16 +0800 Labels: k8s-app=kube-dns pod-template-hash=8686dcc4fd Annotations: <none> Status: Running IP: 10.244.0.30 Controlled By: ReplicaSet/coredns-8686dcc4fd Containers: coredns: Container ID: docker://5473c887d6858f364e8fc4c8001e41b2c5e612ce55d7c409df69788abf6585ed Image: registry.aliyuncs.com/google_containers/coredns:1.3.1 Image ID: docker-pullable://registry.aliyuncs.com/google_containers/coredns@sha256:638adb0319813f2479ba3642bbe37136db8cf363b48fb3eb7dc8db634d8d5a5b Ports: 53/UDP, 53/TCP, 9153/TCP Host Ports: 0/UDP, 0/TCP, 0/TCP Args: -conf /etc/coredns/Corefile State: Terminated Reason: Error Exit Code: 2 Started: Mon, 28 Oct 2019 14:15:39 +0800 Finished: Mon, 28 Oct 2019 14:15:40 +0800 Last State: Terminated Reason: Error Exit Code: 2 Started: Mon, 28 Oct 2019 14:15:20 +0800 Finished: Mon, 28 Oct 2019 14:15:21 +0800 Ready: False Restart Count: 2 Limits: memory: 170Mi Requests: cpu: 100m memory: 70Mi Liveness: http-get http://:8080/health delay=60s timeout=5s period=10s #success=1 #failure=5 Readiness: http-get http://:8080/health delay=0s timeout=1s period=10s #success=1 #failure=3 Environment: <none> Mounts: /etc/coredns from config-volume (ro) /var/run/secrets/kubernetes.io/serviceaccount from coredns-token-ltkvt (ro) Conditions: Type Status Initialized True Ready False ContainersReady False PodScheduled True Volumes: config-volume: Type: ConfigMap (a volume populated by a ConfigMap) Name: coredns Optional: false coredns-token-ltkvt: Type: Secret (a volume populated by a Secret) SecretName: coredns-token-ltkvt Optional: false QoS Class: Burstable Node-Selectors: beta.kubernetes.io/os=linux Tolerations: CriticalAddonsOnly node-role.kubernetes.io/master:NoSchedule node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 27s default-scheduler Successfully assigned kube-system/coredns-8686dcc4fd-4j5gv to k8s-master-15-81 Normal Pulled 4s (x3 over 26s) kubelet, k8s-master-15-81 Container image "registry.aliyuncs.com/google_containers/coredns:1.3.1" already present on machine Normal Created 4s (x3 over 26s) kubelet, k8s-master-15-81 Created container coredns Normal Started 4s (x3 over 25s) kubelet, k8s-master-15-81 Started container coredns Warning BackOff 1s (x4 over 21s) kubelet, k8s-master-15-81 Back-off restarting failed container [root@k8s-master-15-81 ~]# kubectl -n kube-system describe pod coredns-8686dcc4fd-5p6tp Name: coredns-8686dcc4fd-5p6tp Namespace: kube-system Priority: 2000000000 PriorityClassName: system-cluster-critical Node: k8s-master-15-81/192.168.15.81 Start Time: Mon, 28 Oct 2019 14:15:15 +0800 Labels: k8s-app=kube-dns pod-template-hash=8686dcc4fd Annotations: <none> Status: Running IP: 10.244.0.29 Controlled By: ReplicaSet/coredns-8686dcc4fd Containers: coredns: Container ID: docker://4b19e53c68188faa107c310e75c6927bb0e280be042019b2805ef050fcd9aaaf Image: registry.aliyuncs.com/google_containers/coredns:1.3.1 Image ID: docker-pullable://registry.aliyuncs.com/google_containers/coredns@sha256:638adb0319813f2479ba3642bbe37136db8cf363b48fb3eb7dc8db634d8d5a5b Ports: 53/UDP, 53/TCP, 9153/TCP Host Ports: 0/UDP, 0/TCP, 0/TCP Args: -conf /etc/coredns/Corefile State: Waiting Reason: CrashLoopBackOff Last State: Terminated Reason: Error Exit Code: 2 Started: Mon, 28 Oct 2019 14:16:09 +0800 Finished: Mon, 28 Oct 2019 14:16:10 +0800 Ready: False Restart Count: 3 Limits: memory: 170Mi Requests: cpu: 100m memory: 70Mi Liveness: http-get http://:8080/health delay=60s timeout=5s period=10s #success=1 #failure=5 Readiness: http-get http://:8080/health delay=0s timeout=1s period=10s #success=1 #failure=3 Environment: <none> Mounts: /etc/coredns from config-volume (ro) /var/run/secrets/kubernetes.io/serviceaccount from coredns-token-ltkvt (ro) Conditions: Type Status Initialized True Ready False ContainersReady False PodScheduled True Volumes: config-volume: Type: ConfigMap (a volume populated by a ConfigMap) Name: coredns Optional: false coredns-token-ltkvt: Type: Secret (a volume populated by a Secret) SecretName: coredns-token-ltkvt Optional: false QoS Class: Burstable Node-Selectors: beta.kubernetes.io/os=linux Tolerations: CriticalAddonsOnly node-role.kubernetes.io/master:NoSchedule node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 90s default-scheduler Successfully assigned kube-system/coredns-8686dcc4fd-5p6tp to k8s-master-15-81 Warning Unhealthy 85s kubelet, k8s-master-15-81 Readiness probe failed: HTTP probe failed with statuscode: 503 Normal Pulled 36s (x4 over 89s) kubelet, k8s-master-15-81 Container image "registry.aliyuncs.com/google_containers/coredns:1.3.1" already present on machine Normal Created 36s (x4 over 88s) kubelet, k8s-master-15-81 Created container coredns Normal Started 36s (x4 over 88s) kubelet, k8s-master-15-81 Started container coredns Warning BackOff 4s (x11 over 84s) kubelet, k8s-master-15-81 Back-off restarting failed container [root@k8s-master-15-81 ~]#
强制删除coredns pod无效
[root@k8s-master-15-81 ~]# kubectl delete pod coredns-8686dcc4fd-4j5gv --grace-period=0 --force -n kube-system warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "coredns-8686dcc4fd-4j5gv" force deleted [root@k8s-master-15-81 ~]# kubectl delete pod coredns-8686dcc4fd-5p6tp --grace-period=0 --force -n kube-system warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely. pod "coredns-8686dcc4fd-5p6tp" force deleted [root@k8s-master-15-81 ~]#
本地dns配置是ok的
[root@k8s-master-15-81 k8s_config]# cat /etc/resolv.conf # Generated by NetworkManager nameserver 10.68.8.65 nameserver 10.68.8.66 [root@k8s-master-15-81 k8s_config]#
1.2 解决方案:
这问题很有可能是防火墙(iptables)规则错乱或者缓存导致的,可以依次执行以下命令进行解决:
systemctl stop kubelet systemctl stop docker iptables --flush iptables -tnat --flush systemctl start kubelet systemctl start docker
执行如上命令后问题解决
2 添加工作节点时提示token过期
集群注册token的有效时间为24小时,如果集群创建完成后没有及时添加工作节点,那么我们需要重新生成token。相关命令如下所示:
#生成token kubeadm token generate #根据token输出添加命令 kubeadm token create <token> --print-join-command --ttl=0

然后仅需复制打印出来的命令到工作节点执行即可。
3 kubectl 执行命令报“The connection to the server localhost:8080 was refused”
作为集群管理的核心,工作节点上的kubectl可能一上来就跪了,如下图所示:

出现这个问题的原因是kubectl命令需要使用kubernetes-admin的身份来运行,在“kubeadm int”启动集群的步骤中就生成了“/etc/kubernetes/admin.conf”。
因此,解决方法如下,将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到工作节点相同目录下:
#复制admin.conf,请在主节点服务器上执行此命令 scp /etc/kubernetes/admin.conf 172.16.2.202:/etc/kubernetes/admin.conf scp /etc/kubernetes/admin.conf 172.16.2.203:/etc/kubernetes/admin.conf
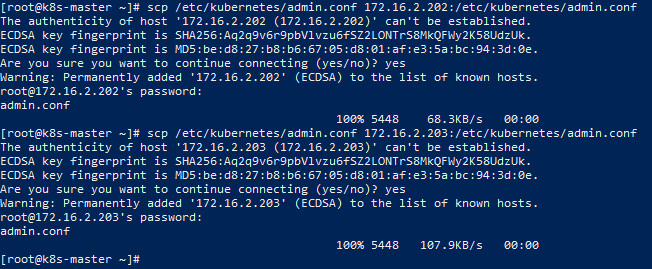
然后分别在工作节点上配置环境变量:
#设置kubeconfig文件 export KUBECONFIG=/etc/kubernetes/admin.conf echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
接下来,工作节点就正常了,如:

4 网络组件flannel无法完成初始化
网络组件flannel安装完成后,通过命令查看时一直在初始化状态,并且通过日志输出内容如下所示:
kubectl get pods -n kube-system -o wide
kubectl logs -f kube-flannel-ds-amd64-hl89n -n kube-system
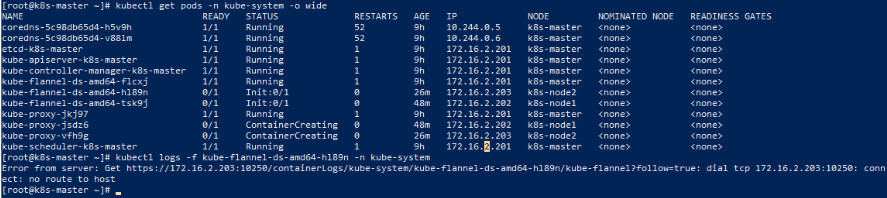
具体错误日志为:
Error from server: Get https://172.16.2.203:10250/containerLogs/kube-system/kube-flannel-ds-amd64-hl89n/kube-flannel?follow=true: dial tcp 172.16.2.203:10250: connect: no route to host
这时,我们可以登录节点所在的服务器,使用以下命令来查看目标节点上的kubelet日志:
journalctl -u kubelet -f
注意:journalctl工具可以查看所有日志,包括内核日志和应用日志。
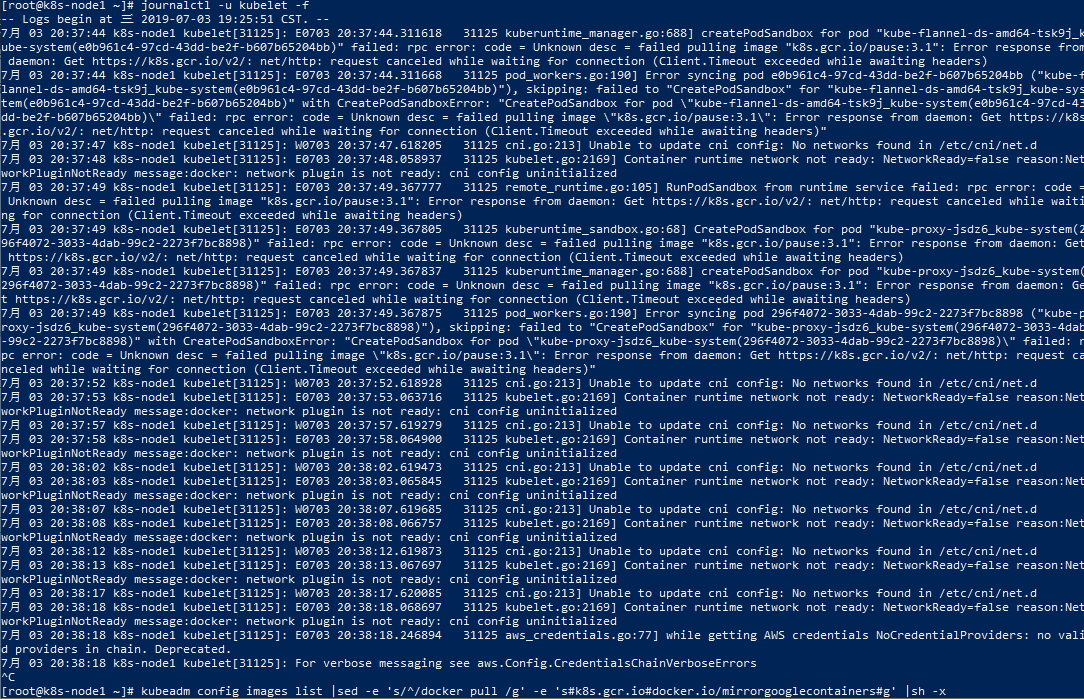
通过日志,我们发现是镜像拉取的问题。对此,大家可以参考上文中镜像拉取的方式以及重命名镜像标签来解决此问题,当然也可以通过设置代理来解决此问题。
5 部分节点无法启动pod
有时候,我们部署了应用之后,发现在部分工作节点上pod无法启动(一直处于ContainerCreating的状态):

通过排查日志最终我们得到重要信息如下所示:
NetworkPlugin cni failed to set up pod "demo-deployment-675b5f9477-hdcwg_default" network: failed to set bridge addr: "cni0" already has an IP address different from 10.0.2.1/24
这是由于当前节点之前被反复注册,导致flannel网络出现问题。可以依次执行以下脚本来重置节点并且删除flannel网络来解决:
kubeadm reset #重置节点 systemctl stop kubelet && systemctl stop docker && rm -rf /var/lib/cni/ && rm -rf /var/lib/kubelet/* && rm -rf /var/lib/etcd && rm -rf /etc/cni/ && ifconfig cni0 down && ifconfig flannel.1 down && ifconfig docker0 down && ip link delete cni0 && ip link delete flannel.1 systemctl start docker
执行完成后,重新生成token并注册节点即可,具体可以参考上文内容。
参考: