【1】
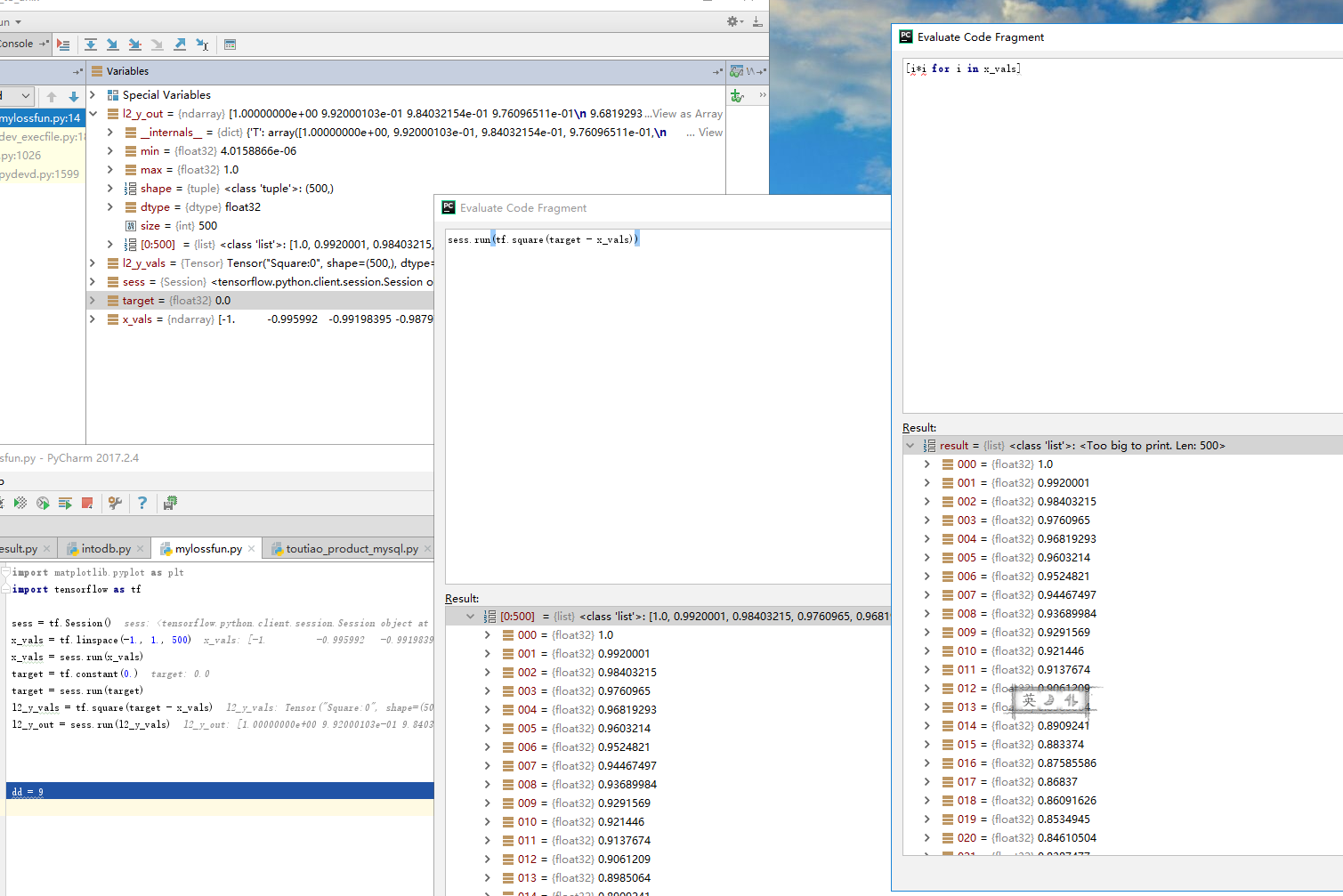
L2正则损失函数、欧拉损失函数:预测值与目标差值的*方和
在目标值附*有更好的曲度,离目标越*收敛越慢
【2】
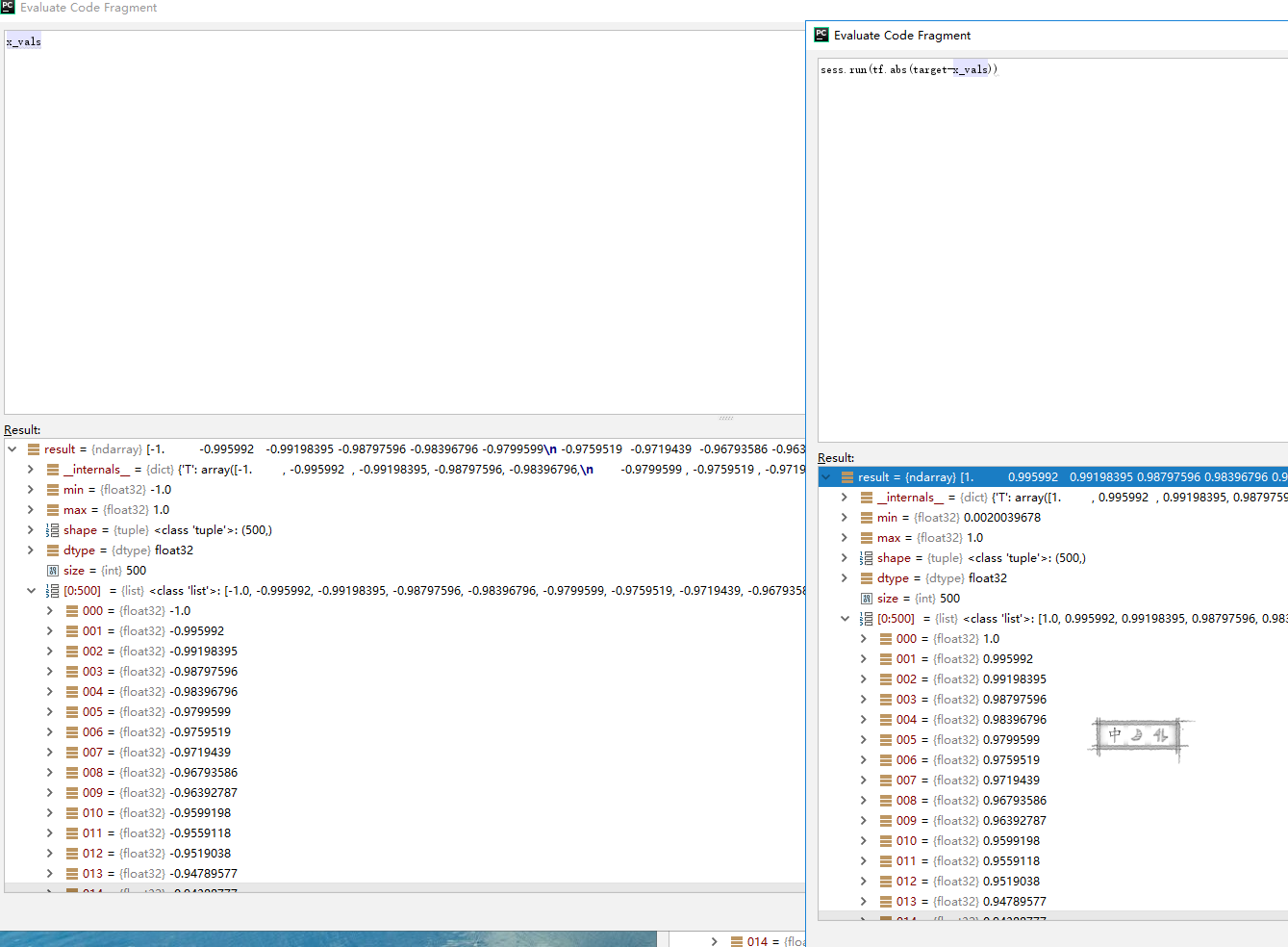
L1正则损失函数,绝对值损失函数
在目标值附*不*滑,导致算法不能很好地收敛
【1】【2】代码
import matplotlib.pyplot as plt import tensorflow as tf sess = tf.Session() x_vals = tf.linspace(-1., 1., 500) target = tf.constant(0.) l2_y_vals = tf.square(target - x_vals) l2_y_out = sess.run(l2_y_vals)
【3】
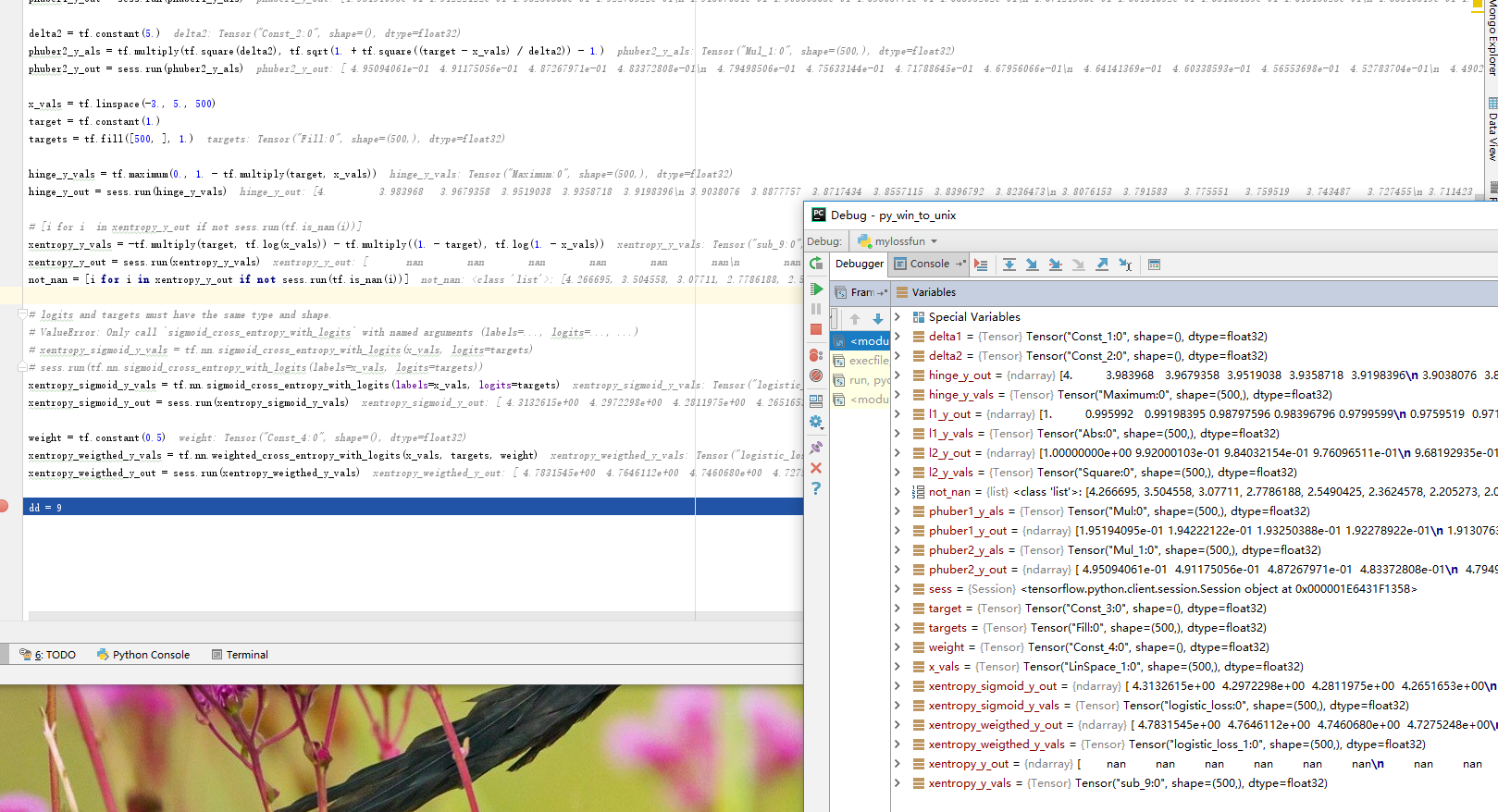
Pseudo-Huber损失函数是 Huber损失函数的连续、*滑估计,师徒利用L1和L2正则雪见极值处的陡峭,使得目标值附*连续。
它的表达式依赖delta。

【4】分类损失函数
用来评估预测分类结果
【5】
Hinge 损失函数 主要用来评估支持向量机算法,也用来评估神经网络算法
本例中,计算两个目标类(-1,1) 之间的损失,使用目标值1,故预测距离值1越*,

【6】两类交叉熵损失函数 逻辑损失函数
Cross-entropy loss
当预测2类目标0或者1时,希望度量预测值到真实分类值(0或者1)的距离,这个距离经常是0到1之间的实数。为了度量这个距离,我们可以使用信息论汇总的交叉熵。
【7】Sigmoid损失函数 Sigmoid cross entropy loss 与两类交叉熵损失函数类是,不同的是,它先把x_vals的值通过sigmoid函数转换,再计算交叉熵损失

import matplotlib.pyplot as plt import tensorflow as tf sess = tf.Session() x_vals = tf.linspace(-1., 1., 500) target = tf.constant(0.) l2_y_vals = tf.square(target - x_vals) l2_y_out = sess.run(l2_y_vals) l1_y_vals = tf.abs(target - x_vals) l1_y_out = sess.run(l1_y_vals) delta1 = tf.constant(0.25) phuber1_y_als = tf.multiply(tf.square(delta1), tf.sqrt(1. + tf.square((target - x_vals) / delta1)) - 1.) phuber1_y_out = sess.run(phuber1_y_als) delta2 = tf.constant(5.) phuber2_y_als = tf.multiply(tf.square(delta2), tf.sqrt(1. + tf.square((target - x_vals) / delta2)) - 1.) phuber2_y_out = sess.run(phuber2_y_als) x_vals = tf.linspace(-3., 5., 500) target = tf.constant(1.) targets = tf.fill([500, ], 1.) hinge_y_vals = tf.maximum(0., 1. - tf.multiply(target, x_vals)) hinge_y_out = sess.run(hinge_y_vals) # [i for i in xentropy_y_out if not sess.run(tf.is_nan(i))] xentropy_y_vals = -tf.multiply(target, tf.log(x_vals)) - tf.multiply((1. - target), tf.log(1. - x_vals)) xentropy_y_out = sess.run(xentropy_y_vals) not_nan = [i for i in xentropy_y_out if not sess.run(tf.is_nan(i))] # logits and targets must have the same type and shape. # ValueError: Only call `sigmoid_cross_entropy_with_logits` with named arguments (labels=..., logits=..., ...) # xentropy_sigmoid_y_vals = tf.nn.sigmoid_cross_entropy_with_logits(x_vals, logits=targets) # sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=x_vals, logits=targets)) xentropy_sigmoid_y_vals = tf.nn.sigmoid_cross_entropy_with_logits(labels=x_vals, logits=targets) xentropy_sigmoid_y_out = sess.run(xentropy_sigmoid_y_vals) dd = 9
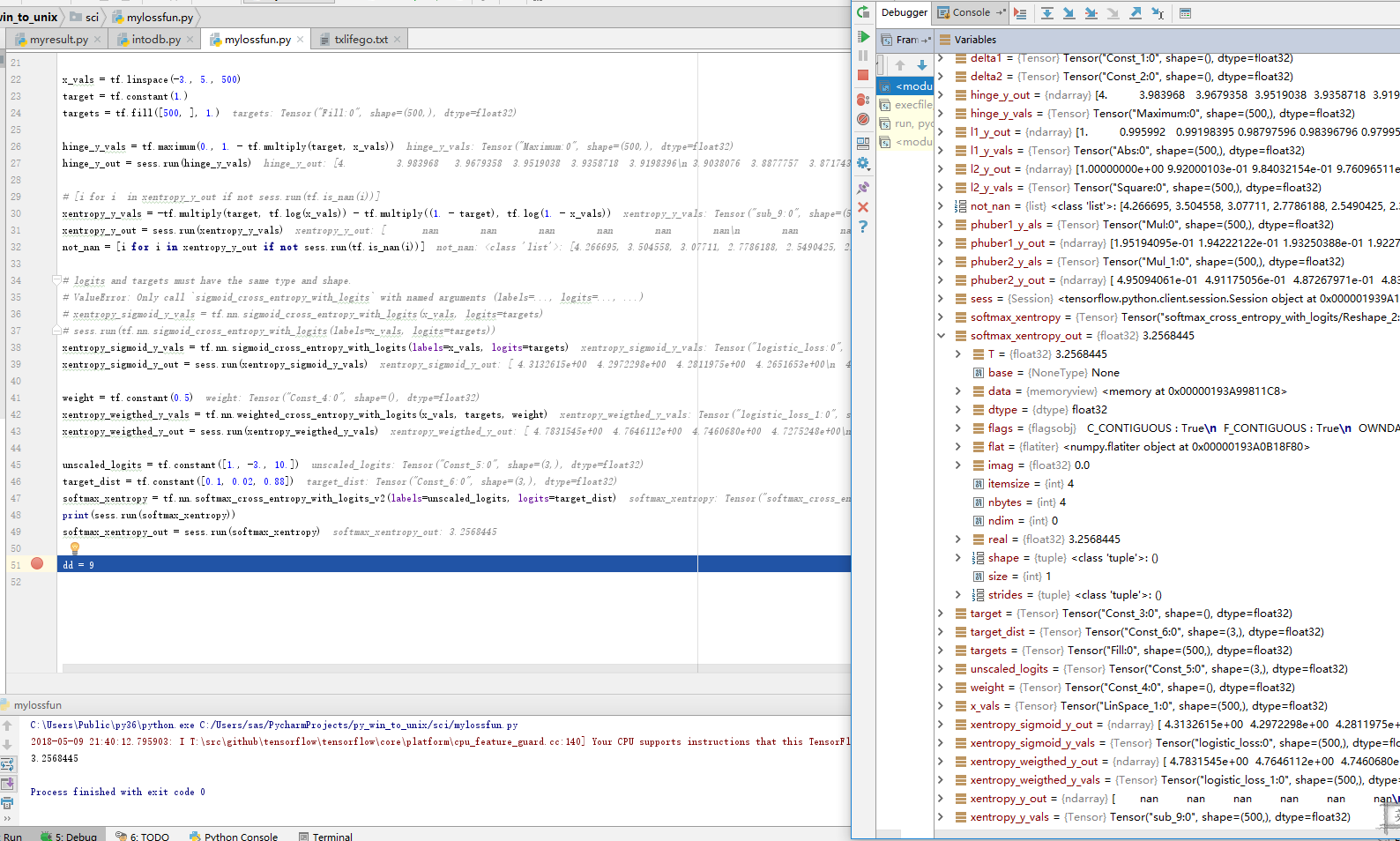
【8】加权交叉熵损失函数 Weighted cross entropy loss 是Sigmoid交叉熵损失函数的加权,对正目标加权
本例中,对正目标加权权重0.5
【9】Softmax交叉熵损失函数 Softmax cross-entropy loss 作用于非归一化的输出结果,只针对单个目标分类的计算损失。通过softmax函数将输出结果
转化成概率分布,然后计算真值概率分布的损失。
【TOCHECK】 1.16012561
【10】稀疏Softmax交叉熵损失函数 Sparse softmax cross-entropy loss 和Softmax交叉熵损失函数类似,它是把目标分类为true的转化成index,
而Softmax交叉熵损失函数将目标转成概率分布。

【TOCHECK】0.00012564
import matplotlib.pyplot as plt import tensorflow as tf sess = tf.Session() x_vals = tf.linspace(-1., 1., 500) target = tf.constant(0.) l2_y_vals = tf.square(target - x_vals) l2_y_out = sess.run(l2_y_vals) l1_y_vals = tf.abs(target - x_vals) l1_y_out = sess.run(l1_y_vals) delta1 = tf.constant(0.25) phuber1_y_als = tf.multiply(tf.square(delta1), tf.sqrt(1. + tf.square((target - x_vals) / delta1)) - 1.) phuber1_y_out = sess.run(phuber1_y_als) delta2 = tf.constant(5.) phuber2_y_als = tf.multiply(tf.square(delta2), tf.sqrt(1. + tf.square((target - x_vals) / delta2)) - 1.) phuber2_y_out = sess.run(phuber2_y_als) x_vals = tf.linspace(-3., 5., 500) target = tf.constant(1.) targets = tf.fill([500, ], 1.) hinge_y_vals = tf.maximum(0., 1. - tf.multiply(target, x_vals)) hinge_y_out = sess.run(hinge_y_vals) # [i for i in xentropy_y_out if not sess.run(tf.is_nan(i))] xentropy_y_vals = -tf.multiply(target, tf.log(x_vals)) - tf.multiply((1. - target), tf.log(1. - x_vals)) xentropy_y_out = sess.run(xentropy_y_vals) not_nan = [i for i in xentropy_y_out if not sess.run(tf.is_nan(i))] # logits and targets must have the same type and shape. # ValueError: Only call `sigmoid_cross_entropy_with_logits` with named arguments (labels=..., logits=..., ...) # xentropy_sigmoid_y_vals = tf.nn.sigmoid_cross_entropy_with_logits(x_vals, logits=targets) # sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=x_vals, logits=targets)) xentropy_sigmoid_y_vals = tf.nn.sigmoid_cross_entropy_with_logits(labels=x_vals, logits=targets) xentropy_sigmoid_y_out = sess.run(xentropy_sigmoid_y_vals) weight = tf.constant(0.5) xentropy_weigthed_y_vals = tf.nn.weighted_cross_entropy_with_logits(x_vals, targets, weight) xentropy_weigthed_y_out = sess.run(xentropy_weigthed_y_vals) unscaled_logits = tf.constant([1., -3., 10.]) target_dist = tf.constant([0.1, 0.02, 0.88]) softmax_xentropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=unscaled_logits, logits=target_dist) print(sess.run(softmax_xentropy)) softmax_xentropy_out = sess.run(softmax_xentropy) unscaled_logits = tf.constant([1., -3., 10.]) sparse_target_dist = tf.constant([2]) sparse_xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=unscaled_logits, logits=sparse_target_dist) print(sess.run(sparse_xentropy)) sparse_xentropy_out = sess.run(sparse_xentropy) dd = 9