Kafka简介
Kafka 是一个高吞吐量、低延迟分布式的消息队列。kafka每秒可以处理几十万条消息, 它的延迟最低只有几毫秒。
-
Kafka 模型
-
kafka 提供了一个生产者、缓冲区、消费者的模型
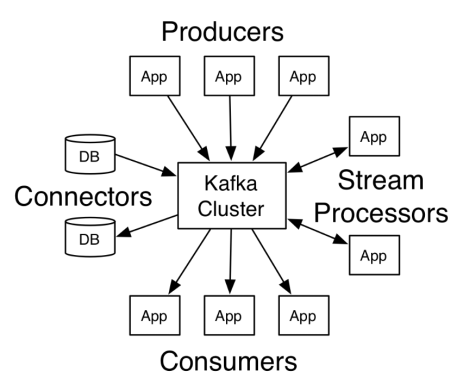
- Broker:kafka集群有多个服务器组成, 用于存储数据(消息)
- Topic: 不同的数据(消息)被分为不同的topic(主题)
- Producer: 消息生产者, 往broker中某个topic里生产数据
- Consumer:消息的消费者, 从broker中某个topic获取数据
-
-
概念理解
-
Topic && Message
- kafka将所有消息组织成多个topic的形式存储, 而每个 topic 又可以拆分成多个partition, 每个partition又由一条条消息组成。
- 每条消息都被标识了一个递增序列号代表其进来的先后顺序, 并按顺序存储在parition中。
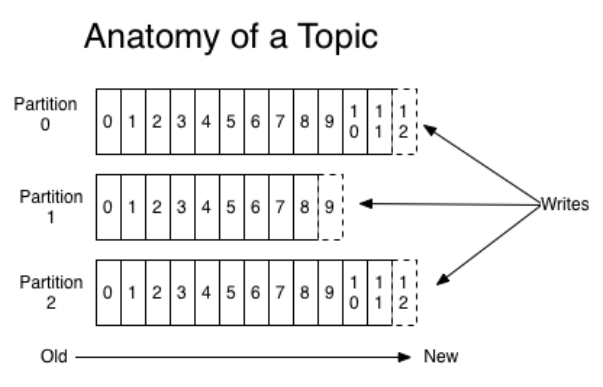
- Producer 选择一个topic, 生产消息, 消息会通过分配策略将消息追加到该topic下的某个partition 分区末尾(queue)
- Consumer 选择一个topic, 通过 id(offset 偏移量) 指定从哪个位置开始消费消息。消费完成之后保留id, 下次可以从这个位置开始继续消费, 也可以从其他任意位置开始消费。
- Offset(偏移量): 能唯一标识该分区中的每个记录。
- Kafka集群保留所有producer生产的消息记录, 不管该消息有没有被消费过。
- 消息在Kafka中的保留时间: 默认 7*24小时(7天), key在配置文件中自定义设置。
- 每个消费者唯一保存的元数据信息就是消费者当前消费日志的位移位置。
- 位移位置是由消费者控制, 即消费者可以通过修改偏移量读取任何位置的数据。
- 每个concumer都保留自己的offset, 互相之间不干扰,不存在线程安全问题, 为并发消费提供了线程安全的保证。
- 每个topic中的消息被组织成多个partition, partition 均匀分配到集群server中。生产、消费消息的时候, 会被路由指定到partition, 减少单台服务器的压力, 增加了程序的并行能力。
- 每个topic中保留的消息可能非常庞大, 通过parition将消息切分成若干个子消息, 并通过负责均衡策略将parition分配到不同的server。 这样当机器负载满的时候, 通过扩容可以将消息重新均匀分配
- 消息消费完成后不会删除, 可以通过重置offset重新消费。
- 灵活的持久化策略: 通过指定保留时间来保存消息, 从而节省broker存储空间。
- 消息以partition分区为单位分配到多个server, 并以partition为单位进行备份。
- 备份策略: 1 个 leader 和 N 个 followers, leader 接受读写请求, followers被动复制leader。 leader 和 followers 会在集群中打散, 保证partition高可用。
-
-
消费者组
-
consumer自己维护消费到哪个offset
-
每个consumer都有对应的group
-
group内是queue消费模型
- 各个consumer消费不同的partition
- 一个消息在group内只消费一次
-
group间是publish-subscribe消费模型
- 各个group各自独立消费, 互不影响
- 一个消息在每个group消费一次
-
每个分组只有一个consumer能消费单条消息
-
极端情况:
- 当所有consumer 的 consumer group 相同时, 即消费者都在一个组里面
- 当每个consumer 的consumer group 都不相同时, 即一个组里只有一个消费者
-
-
Kafka的使用场景
- 日志收集
- 公司可以用kafka来收集各种服务的日志, 这些日志可以通过kafka的接口以统一服务的方式开放给hadoop, Hbase,elasticsearch 等consumer。
- 消息系统
- 解耦 生产者 和 消费者、缓存消息等。
- 用户活动跟踪
- kafka常被用来记录 web 用户 或者 app 用户的各种活动, 如浏览网页、 搜索、 点击等活动, 这些活动信息被各个服务器发布到kafka的topic中, 然后订阅者通过订阅这些topic来做实时的监控分析, 或者装载到hadoop、数据仓库中做离线分析与挖掘。
- 流式处理: spark streaming,storm, flink
- 日志收集
Kafka数据一致性之ISR机制
-
简介
- Kafka是由follower到leader上拉取数据的方式进行同步的。
- Kafka上的副本机制是,写都往 leader上写,读也只在 leader上读,follower 只是数据的一个备份,保证leader被挂掉后顶上来,并不往外提供服务。
-
消息同步
- 同步复制: 只有所有的follower把数据拿过去后才 commit,一致性好,性能不高。
- 异步复制: 只要leader拿到数据立即 commit,等 follower 慢慢去复制,性能高,立即返回,一致性差一些。
-
kafka不是完全同步,也不是完全异步,是一种ISR(In-Sync Replica)机制:
-
leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护。
-
如果一个follower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除。
-
查看 topic 信息时附带 ISR 信息
[root@node01 kafka_2.11-0.8.2.1]# bin/kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --describe --topic test Topic:test PartitionCount:3 ReplicationFactor:2 Configs: Topic: test Partition: 0 Leader: 1 Replicas: 1,0 Isr: 1,0 Topic: test Partition: 1 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: test Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2 -
配置文件中 ISR 相关参数:
replica.lag.time.max.ms=10000 # 如果leader发现follower超过10秒没有向它发起fech请求,那么leader就把它从ISR中移除。 replica.lag.max.messages=4000 # follower与leader相差4000条数据,就将副本从ISR中移除 -
当follower同时满足这两个条件后,leader又会将它加入ISR中,所以ISR是处于一个动态(dynamic)调整的情况
-
ISR 中 replicas 的作用
- 当partion的leader挂掉,则会优先从ISR列表里的挑选一个follower选举成新的leader,同时将旧leader移除出ISR列表。
-
Kafka API
-
生产者
/** * 向kafka中生产数据 * * @author root */ public class MyProducer extends Thread { private String topic; //发送给Kafka的数据,topic private Producer<String, String> producerForKafka; public MyProducer(String topic) { this.topic = topic; // 底层为HashTable, 线程安全 Properties conf = new Properties(); conf.put("metadata.broker.list", "node01:9092,node02:9092,node03:9092"); conf.put("serializer.class", StringEncoder.class.getName()); /** * ack=0 生产者不会等待来自任何服务器的响应,一直发送数据 * ack=1 leader收到数据后,给生产者返回响应消息,生产者再继续发送新的数据 * ack=all 生产者发送一条数据后,leader会等待所有isr列表里的服务器同步好数据后,才返回响应。 * * ack=0.吞吐量高,但是消息存在丢失风险。 * ack=1.数据的安全性和性能 都有一定保障 * ack=all 安全性最高,但性能最差 */ conf.put("acks",0); //缓存数据,批量发送,当需要发送到同一个partition中的数据大小达到15KB时,将数据发送出去 conf.put("batch.size", 16384); producerForKafka = new Producer<>(new ProducerConfig(conf)); } @Override public void run() { int counter = 0; while (true) { String value = "ronnie" + counter; String key = counter + ""; /** * producer将 message发送数据到 kafka topic的时候,这条数据应该发到哪个partition分区里呢? * message 有key,value组成 * 当message的key为null值,则将message随机发送到partition里 * 当message的key不为null值时,则通过key 取hash后 ,对partition_number 取余数,得到数就是partition id. */ // KeyedMessage<String, String> message = new KeyedMessage<>(topic,value); KeyedMessage<String, String> message = new KeyedMessage<>(topic, key,value); producerForKafka.send(message); System.out.println(value + " - -- -- --- -- - -- - -"); //每2条数据暂停1秒 // if (0 == counter % 2) { // // try { // Thread.sleep(1000); // } catch (InterruptedException e) { // e.printStackTrace(); // } // } counter++; } } public static void main(String[] args) { new MyProducer("test1").start(); } } -
消费者
/** * Kafka消费者API分为两种 * 1.High level consumer API * 此种API,偏移量由zookeeper来保存,使用简单,但是不灵活 * 2.Simple level consumer API * 此种API,不依赖Zookeeper,无论从自由度和性能上都有更好的表现,但是开发更复杂 * * * topic下的一个partition分区,只能被同一组下的一个消费者消费。 * 要想保证消费者从topic中消费的数据是有序的,则应当将topic的分区设置为1个partition * */ //High level consumer API public class MyConsumer1 extends Thread { private final ConsumerConnector consumer; private final String topic; public MyConsumer1(String topic) { ConsumerConfig consumerConfig = createConsumerConfig(); consumer = Consumer .createJavaConsumerConnector(consumerConfig); this.topic = topic; } private static ConsumerConfig createConsumerConfig() { Properties props = new Properties(); //ZK地址 props.put("zookeeper.connect", "node01:2181,node02:2181,node03:2181"); //消费者所在组的名称 props.put("group.id", "ronnie3"); //ZK超时时间 props.put("zookeeper.session.timeout.ms", "400"); //消费者自动提交偏移量的时间间隔 props.put("auto.commit.interval.ms", "10000"); //当消费者第一次消费时,从最低的偏移量开始消费 props.put("auto.offset.reset","smallest"); //自动提交偏移量 默认就是true // props.put("auto.commit.enable","true"); return new ConsumerConfig(props); } public void run() { Map<String, Integer> topicCountMap = new HashMap<String, Integer>(); topicCountMap.put(topic, 1); // 描述读取哪个topic,需要几个线程读 Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer .createMessageStreams(topicCountMap); // 每个线程对应于一个KafkaStream List<KafkaStream<byte[], byte[]>> list = consumerMap.get(topic); // 获取kafkastream流 KafkaStream stream0 = list.get(0); ConsumerIterator<byte[], byte[]> it = stream0.iterator(); System.out.println("start................"); while (it.hasNext()){ // 获取一条消息 MessageAndMetadata<byte[], byte[]> value = it.next(); int partition = value.partition(); long offset = value.offset(); String data = new String(value.message()); System.err.println( data + " partition:" + partition + " offset:" + offset); // try { // Thread.sleep(1000); // } catch (InterruptedException e) { // e.printStackTrace(); // } } } public static void main(String[] args) { MyConsumer1 consumerThread = new MyConsumer1("test"); consumerThread.start(); } }
Kafka 数据丢失 和 重复消息问题
-
数据丢失
-
Producer 端导致数据丢失
-
丢失原因:
-
- Producer 在 发送数据给kafka时, kafka一开始的数据是存储的在服务器的PageCache(内存)上的, 定期 flush 到磁盘上的, 如果忽然断电则数据会造成丢失。
- 在使用kafka的备份机制, producer发数据给topic的分区时, 可以对 partition 分区做备份。由于当producer的ack设置为 0 或 1, 最多只能保证leader有数据。若有一条producer发送的数据 leader 刚接收完毕, 此时leader挂掉, 那么 partition 的 replicas 副本还未来得及同步。
-
-
解决方案:
-
-
我们可以提高flush的频率来减少数据丢失量, 但并不能保证数据一定不丢失。官方建议通过备份机制来解决数据丢失问题。
- 相关参数:
- log.flush.interval.messages: 当缓存中有多少条数据时, 触发溢写
- log.flush.interval.ms: 每隔多久时间, 触发溢写
- 相关参数:
-
针对于备份机制而导致的数据丢失, 将ack设置为all, 即所有的备份分区也都同步了该条数据, 再发送第二条数据。(降低性能)
-
-
-
-
Consumer 端导致数据丢失
- 丢失原因: 在使用kafka的高级API时, 消费者会自动每隔一段时间将offset保存到zookeeper上, 此时如果刚好将偏移量提交到zookeeper上后, 但这条数据还没消费完, 机器发生宕机, 此时数据就会丢失。
- 解决方案: 关闭偏移量自动提交, 改成手动提交, 每次数据处理完后, 再提交。
-
-
数据重复消费
- 产生原因: 在消费者自动提交offset 到 zookeeper 后, 程序又消费了几条数据, 但是还没有到下次提交offset到Zookeeper之时, 再下一次机器重启的时候, 消费者会先去读Zookeeper上的偏移量进行消费, 这就会导致数据重复消费
- 解决方案: 关闭自动提交, 改由手动提交
Kafka高吞吐的本质
-
页缓存技术 + 磁盘顺序写
-
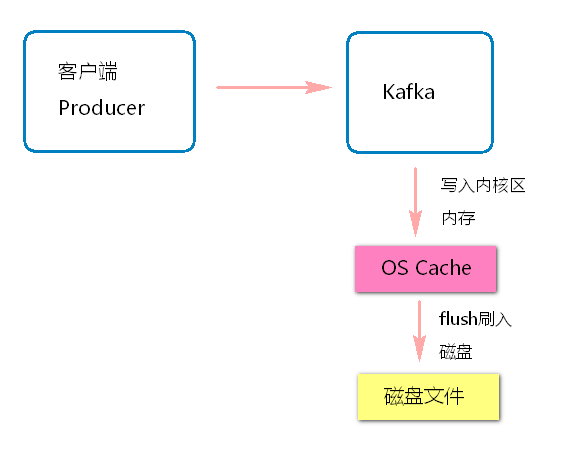
kafka是基于操作系统的页缓存来实现文件写入的。
- 操作系统本身有一层page cache 缓存(内存)[os cache]。
- 在写入磁盘文件的时候, 可以直接写入该缓存中, 接下来由操作系统自己决定什么时候把page cache 中的数据刷入到磁盘文件中。
-
Kafka写数据的时候是以磁盘顺序写的方式来写入的。仅仅将数据添加到文件的末尾, 不是在文件的随机位置来修改数据。
-
磁盘顺序写的性能会比随机写快上几百倍。
-
-
零拷贝技术
-
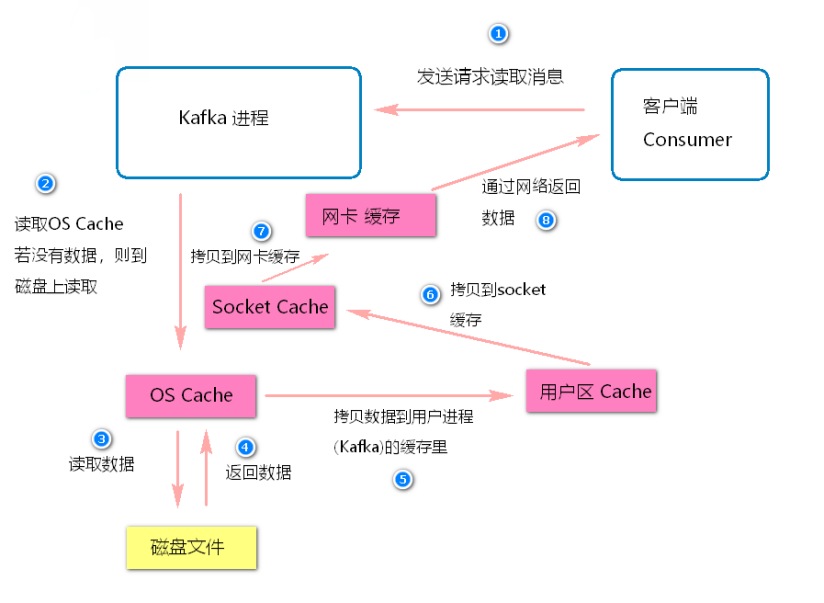
假设要是kafka什么优化都不做,就是很简单的从磁盘读数据发送给下游的消费者,那么大概过程如下所示:
)-
步骤 5 和 步骤 6 的两次拷贝是没有必要的(还会引起多次上下文切换, 消耗性能)
-
零拷贝技术就是直接让操作系统的 cache 中的数据发送到网卡后传输给下游的消费者, 中间跳过了两次拷贝数据的步骤, Socket缓存中仅仅会拷贝一个描述符过去, 不会拷贝数据到Socket缓存。
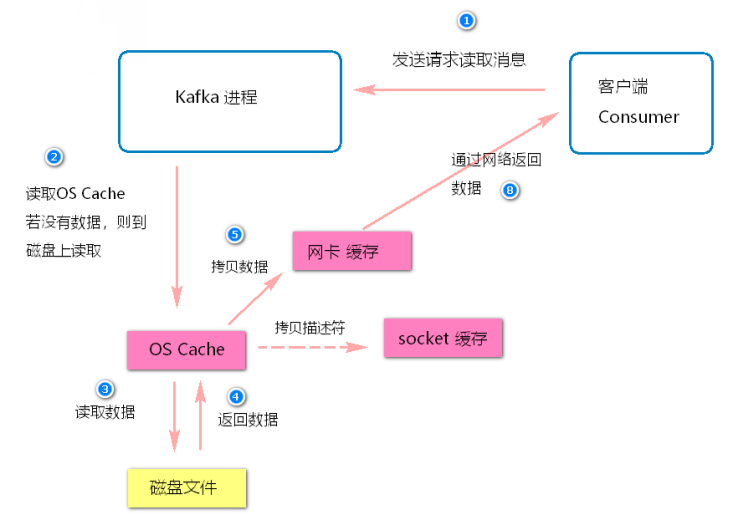
- 如果kafka集群经过良好的调优,我们会发现大量的数据都是直接写入os cache中,然后读数据的时候也是从os cache中读。
- 相当于是Kafka完全基于内存提供数据的写和读了,所以这个整体性能会极其的高。
-
-
Kafka消息的持久化
- Kafka topic的数据存储在磁盘的时候,默认存储在/tmp/kafka-logs目录下,这个目录可以自己设置。同时在该目录下,又会按topic的每个partition分区来存储,一个分区一个目录,一个partition目录下面又会有多个segment文件。
[root@node01 kafka_2.11-0.8.2.1]# cd /tmp/kafka-logs/
[root@node01 kafka-logs]# pwd
/tmp/kafka-logs
[root@node01 kafka-logs]# ll
total 16
-rw-r--r-- 1 root root 22 Oct 15 18:57 recovery-point-offset-checkpoint
-rw-r--r-- 1 root root 22 Oct 15 18:57 replication-offset-checkpoint
drwxr-xr-x 2 root root 4096 Oct 15 11:22 test-0
drwxr-xr-x 2 root root 4096 Oct 15 11:22 test-2
[root@node01 kafka-logs]# cd test-0/
[root@node01 test-0]# ll
total 0
-rw-r--r-- 1 root root 10485760 Oct 15 11:22 00000000000000000000.index
-rw-r--r-- 1 root root 0 Oct 15 11:22 00000000000000000000.log
-
test-x文件夹下有.index 和 .log参数
- .index 为索引文件, 命名规则为从0开始到,后续的由上一个文件的最大的offset偏移量来开头
- .log 文件为数据文件,存放具体消息数据 kafka从磁盘上查找数据时,会先根据offset偏移量,对index文件名字进行扫描,通过用二分法的查找方式,可以快速定位到此offset所在的索引文件,然后通过索引文件里的索引,去对应的log文件种查找数据。
-
相关参数:
-
Broker 全局参数:
- message.max.bytes (默认:1000000) – broker能接收消息的最大字节数,这个值应该比消费端的fetch.message.max.bytes更小才对,否则broker就会因为消费端无法使用这个消息而挂起。
- log.segment.bytes (默认: 1GB) – segment数据文件的大小,当segment文件大于此值时,会创建新文件,要确保这个数值大于一个消息的长度。一般说来使用默认值即可(一般一个消息很难大于1G,因为这是一个消息系统,而不是文件系统)。
- log.roll.hours (默认:7天) - 当segment文件7天时间里都没达到log.segment.bytes 大小,也会产生一个新文件。
- replica.fetch.max.bytes (默认: 1MB) – broker可复制的消息的最大字节数。这个值应该比message.max.bytes大,否则broker会接收此消息,但无法将此消息复制出去,从而造成数据丢失。
-
Consumer 端参数:
-
fetch.message.max.bytes (默认 1MB) – 消费者能读取的最大消息。这个值应该大于或等于message.max.bytes。
-
log.segment.bytes 这是一个全局参数,即所有的topic都是这个配置值。
-
-