一、什么是ZAB协议?
Zab 借鉴了 Paxos 算法,是特别为Zookeeper设计的支持崩溃恢复的原子广播协议。基于该协议,Zookeeper设计为只有一台客户端(Leader)负责处理外部的写事务请求,然后 Leader 客户端将数据同步到其他Follower节点。即Zookeeper只有一个Leader可以发起提案(proposal)。
Zab 协议主要包括两部分:消息广播、崩溃恢复。
整个Zookeeper就是在这两个模式之间切换。 当Leader服务可以正常使用,就进入消息广播模式,当Leader不可用时,则进入崩溃恢复模式。
二、消息广播
ZAB协议的消息广播过程使用的是一个原子广播协议,类似一个二阶段提交过程。
对于客户端发送的写请求,全部由Leader接收,Leader将请求封装成一个事务提案(proposal),将其发送给所有Follwer,如果超过半数Follwer成功响应,则执行commit操作(先提交自己,再发送commit给所有Follwer)。
广播流程图解
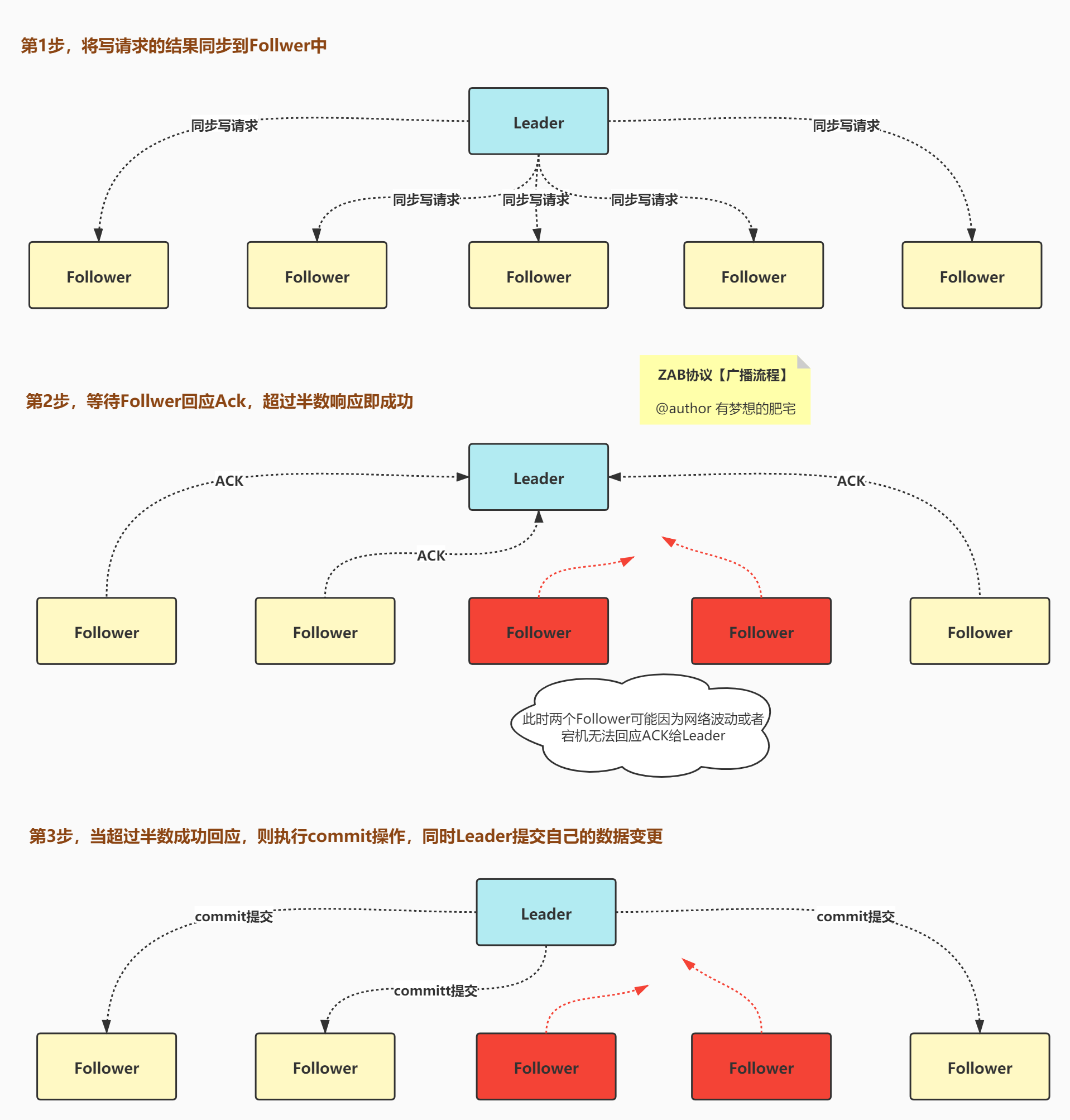
- (1)客户端发起写操作请求。
- (2)Leader服务器将客户端的请求转化为事务Proposal提案【同步写请求】,同时为每个Proposal分配一个全局的ID,即zxid。
- (3)Leader服务器为每个Follower服务器分配一个单独的队列,然后将需要广播的Proposal依次放到队列中去,并且根据FIFO策略进行消息发送。
- (4)Follower接收到Proposal后,会首先将其以事务日志的方式写入本地磁盘中,写入成功后向Leader反馈一个ACK响应消息。
- (5)Leader接收到超过半数以上Follower的ACK响应消息后,即认为消息发送成功,可以发送commit消息。
- (6)Leader向所有Follower广播commit消息,同时自身也会完成事务提交。Follower接收到commit消息后,会将上一条事务提交。
PS:Zab协议的核心,就是只要有一台服务器提交了Proposal,就要确保所有的服务器最终都能正确提交Proposal。
三、崩溃恢复
一旦Leader服务器出现崩溃或者由于网络原因导致Leader服务器失去了与过半Follower的联系,那么就会进入崩溃恢复模式。
出现异常的两种情况
- (1)假设一个事务在Leader提出之后,Leader挂了。
- (2)一个事务在Leader上提交了,并且过半的Follower都响应Ack了,但是Leader在Commit消息发出之前挂了。
Zab协议崩溃恢复原则
- (1)确保已经被Leader提交的提案Proposal,必须最终被所有的Follower服务器提交。【已经产生的提案,Follower必须执行】
- (2)确保丢弃已经被Leader提出的,但是没有被提交的Proposal。【丢弃Leader最终没确认commit的提案】
恢复方式
恢复方式主要就是选取新的Leader,再进行数据同步,选取Leader的流程可以详见我上一篇文章《Zookeeper(七)Zookeeper集群角色及选举原理分析》
四、CAP理论
什么是CAP理论?
- 一致性(C:Consistency)
- 可用性(A:Available)
- 分区容错性(P:Partition Tolerance)
CAP理论告诉我们,一个分布式系统不可能同时满足以上三种。
PS:这三个基本需求,最多只能同时满足其中的两项,因为P是必须的,因此往往选择就在CP或者AP中。
一致性(C:Consistency)
在分布式系统完成某写操作后任何读操作,都应该获取到该写操作写入的那个最新的值。相当于要求分布式系统中的各节点时时刻刻保持数据的一致性。
可用性(A:Available)
客户端一直可以正常访问并得到系统的正常响应。从用户角度来看就是不会出现系统操作失败或者访问超时等问题。
分区容错性(P:Partition Tolerance)
指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供满足一致性和可用性的服务。也就是说部分故障不影响整体使用。
Zookeeper如何应用CAP理论?
PS:Zookeeper保证的是CP。
原因如下:
- (1)ZooKeeper不能保证每次服务请求的可用性。【在极端环境下,ZooKeeper可能会丢弃一些请求,需要用户重新请求进行获取】
- (2)进行Leader选举时集群都是不可用的状态。