k近邻算法
3.1 k近邻算法
k近邻算法简单、直观:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。下面先叙述k近邻算法,然后再讨论其细节。
算法3.1(k近邻法)
输入:训练数据集
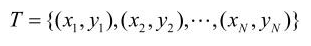
其中,xi∊x⊆Rn为实例的特征向量,yi∊={c1,c2,…,cK}为实例的类别,i=1,2,…,N;实例特征向量x;
输出:实例x所属的类y。
(1)根据给定的距离度量,在训练集T中找出与x最邻近的k个点,涵盖这k个点的x的邻域记作Nk(x);
(2)在Nk(x)中根据分类决策规则(如多数表决)决定x的类别y:
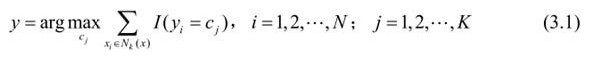
式(3.1)中,I为指示函数,即当yi=cj时I为1,否则I为0。
k近邻法的特殊情况是k=1的情形,称为最近邻算法。对于输入的实例点(特征向量)x,最近邻法将训练数据集中与x最邻近点的类作为x的类。
k近邻法没有显式的学习过程。
3.3k近邻法的实现:kd树
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。这点在特征空间的维数大及训练数据容量大时尤其必要。
k近邻法最简单的实现方法是线性扫描(linear scan)。这时要计算输入实例与每一个训练实例的距离。当训练集很大时,计算非常耗时,这种方法是不可行的。
为了提高k近邻搜索的效率,可以考虑使用特殊的结构存储训练数据,以减少计算距离的次数。具体方法很多,下面介绍其中的kd树(kd tree)方法[1]。
3.3.1 构造kd树
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树,表示对k维空间的一个划分(partition)。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。
构造kd树的方法如下:构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对k维空间进行切分,生成子结点。在超矩形区域(结点)上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);这时,实例被分到两个子区域。这个过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。
通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数(median)[2]为切分点,这样得到的kd树是平衡的。注意,平衡的kd树搜索时的效率未必是最优的。
下面给出构造kd树的算法。
算法3.2(构造平衡kd树)
输入:k维空间数据集T={x1,x2,…,xN},
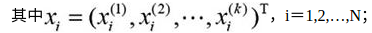
输出:kd树。
(1)开始:构造根结点,根结点对应于包含T的k维空间的超矩形区域。
选择x(1)为坐标轴,以T中所有实例的x(1)坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴x(1)垂直的超平面实现。
由根结点生成深度为1的左、右子结点:左子结点对应坐标x(1)小于切分点的子区域,右子结点对应于坐标x(1)大于切分点的子区域。
将落在切分超平面上的实例点保存在根结点。
(2)重复:对深度为j的结点,选择x(l)为切分的坐标轴,l=j(modk)+1,以该结点的区域中所有实例的x(l)坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴x(l)垂直的超平面实现。
由该结点生成深度为j+1的左、右子结点:左子结点对应坐标x(l)小于切分点的子区域,右子结点对应坐标x(l)大于切分点的子区域。
将落在切分超平面上的实例点保存在该结点。
(3)直到两个子区域没有实例存在时停止。从而形成kd树的区域划分。
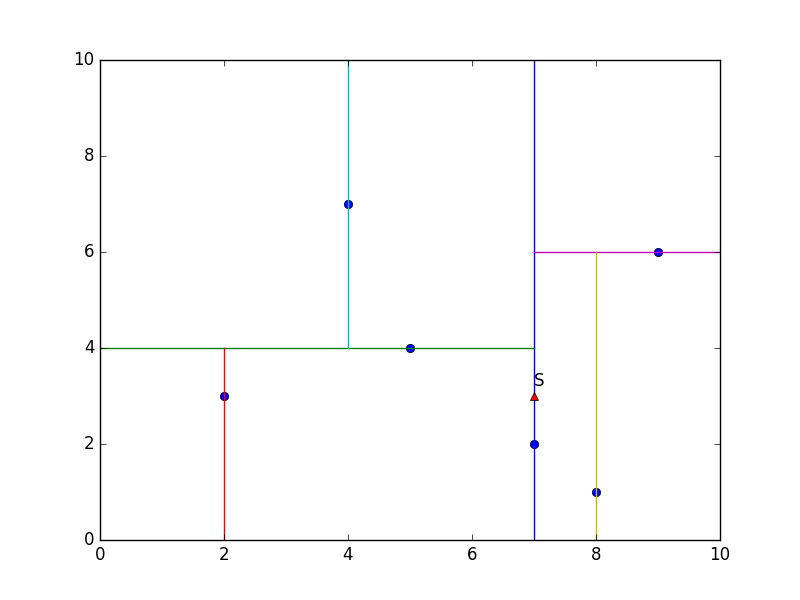
例3.2 给定一个二维空间的数据集:
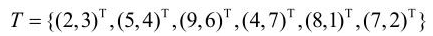
构造一个平衡kd树[3]。
解 根结点对应包含数据集T的矩形,选择x(1)轴,6个数据点的x(1)坐标的中位数是7,以平面x(1)=7将空间分为左、右两个子矩形(子结点);接着,左矩形以x(2)=4分为两个子矩形,右矩形以x(2)=6分为两个子矩形,如此递归,最后得到如图3.3所示的特征空间划分和如图3.4所示的kd树。
下面叙述用kd树的最近邻搜索算法。
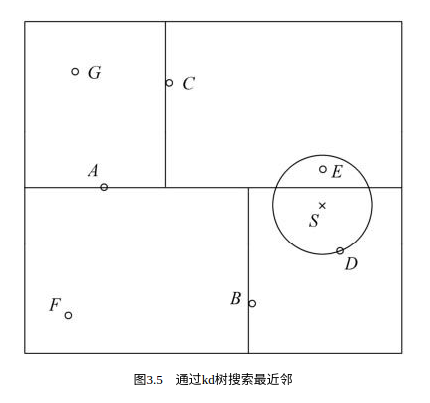
算法3.3(用kd树的最近邻搜索)
输入:已构造的kd树;目标点x;
输出:x的最近邻。
(1)在kd树中找出包含目标点x的叶结点:从根结点出发,递归地向下访问kd树。若目标点x当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点。直到子结点为叶结点为止。
(2)以此叶结点为“当前最近点”。
(3)递归地向上回退,在每个结点进行以下操作:
(a)如果该结点保存的实例点比当前最近点距离目标点更近,则以该实例点为“当前最近点”。
(b)当前最近点一定存在于该结点一个子结点对应的区域。检查该子结点的父结点的另一子结点对应的区域是否有更近的点。具体地,检查另一子结点对应的区域是否与以目标点为球心、以目标点与“当前最近点”间的距离为半径的超球体相交。
如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点。接着,递归地进行最近邻搜索;
如果不相交,向上回退。
(4)当回退到根结点时,搜索结束。最后的“当前最近点”即为x的最近邻点。
如果实例点是随机分布的,kd树搜索的平均计算复杂度是O(logN),这里N是训练实例数。kd树更适用于训练实例数远大于空间维数时的k近邻搜索。当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线性扫描。
1 # coding:utf-8 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 T = [[2, 3], [5, 4], [9, 6], [4, 7], [8, 1], [7, 2]] 6 S=[7, 3] 7 8 class node: 9 def __init__(self, point): 10 self.left = None 11 self.right = None 12 self.point = point 13 self.parent = None 14 pass 15 16 def set_left(self, left): 17 if left == None: pass 18 left.parent = self 19 self.left = left 20 21 def set_right(self, right): 22 if right == None: pass 23 right.parent = self 24 self.right = right 25 26 def median(lst): 27 m = len(lst) / 2 28 return lst[m], m 29 30 def build_kdtree(data, d): 31 data = sorted(data, key=lambda x: x[d]) 32 p, m = median(data) 33 tree = node(p) 34 del data[m] 35 if m > 0: tree.set_left(build_kdtree(data[:m], not d)) 36 if len(data) > 1: tree.set_right(build_kdtree(data[m:], not d)) 37 return tree 38 39 def distance(a, b): 40 return ((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2) ** 0.5 41 42 def search_kdtree(tree, target,best=[]): 43 if len(best)==0: best = [tree.point,distance(tree.point, target)] 44 if target[0] < tree.point[0]: 45 if tree.left != None: 46 return search_kdtree(tree.left, target, best) 47 else: 48 if tree.right != None: 49 return search_kdtree(tree.right, target, best) 50 def update_best(t, best): 51 if t == None: return 52 t = t.point 53 d = distance(t, target) 54 if d < best[1]: 55 best[1] = d 56 best[0] = t 57 while (tree.parent != None): 58 update_best(tree.parent.left, best) 59 update_best(tree.parent.right, best) 60 tree = tree.parent 61 return best[0] 62 63 def showT(tree,d): 64 plt.plot(tree.point[0],tree.point[1],'ob') 65 if tree.parent==None: 66 plt.plot([tree.point[0],tree.point[0]],[0,10]) 67 elif d: 68 if tree.point[0]<tree.parent.point[0]: 69 plt.plot([0,tree.parent.point[0]],[tree.point[1],tree.point[1]]) 70 else: 71 plt.plot([tree.parent.point[0],10],[tree.point[1],tree.point[1]]) 72 else: 73 if tree.point[1]<tree.parent.point[1]: 74 plt.plot([tree.point[0],tree.point[0]],[0,tree.parent.point[1]]) 75 else: 76 plt.plot([tree.point[0],tree.point[0]],[tree.parent.point[1],10]) 77 if tree.left != None: 78 showT(tree.left,not d) 79 if tree.right != None: 80 showT(tree.right,not d) 81 82 kd_tree = build_kdtree(T, 0) 83 showT(kd_tree,0) 84 plt.annotate('S',xy = (S[0],S[1]+0.2)) 85 plt.plot(S[0],S[1],'^r') 86 result=search_kdtree(kd_tree,S) 87 print result #[7, 2] 88 plt.show()