基元线程同步构造
多个线程同时访问共享数据时,线程同步能防止数据损坏。不需要线程同步是最理想的情况,因为线程同步存在许多问题。
第一个问题就是它比较繁琐,而且很容易写错。
第二个问题是,他们会损害性能。获取和释放锁是需要时间的。
第三个问题是,他们一次只允许一个线程访问资源,就可能导致其他线程被阻塞,使用多线程是为了提高效率,而阻塞无疑降低了你的效率。
综上所述,线程同步是一件不好的事情,所以在设计自己的应用程序时,应尽可能避免进行线程同步。具体就是避免使用像静态字段这样的共享数据。线程用new操作符构造对象时,new操作符会返回新对象的引用,如果能避免将这个引用传给可能同时使用对象的另一个线程,就不必同步对该对象进行访问。可试着使用值类型,因为他们总是被赋值,每个我线程操作的都是它自己的副本。最后,多个线程同时对共享数据进行制度访问是没有任何问题的。
基元用户模式和内核模式构造
基元(primitive)是指可以在代码中使用的最简单的构造。有两种基元构造:用户模式(user mode)和内核模式(kernel mode)。
用户模式构造
应尽量使用基元用户模式构造,他们的速度要显著快于内核模式的构造。这是因为他们使用了特殊cpu指令来协调线程。这意味着协调实在硬件中发生的(所以才这么块)。但这也意味着windows操作系统永远检测不到一个线程在纪元用户模式的构造上阻塞了。由于在用户模式的基元构造上阻塞的线程池线程永远不认为已阻塞,所以线程池不会创建新的线程来替换这种临时阻塞的线程。此外,这些cpu指令只阻塞相当短的时间。
这也是我认为较好的构造方式,CLR Via C# 的作者Jeffrey Richter也建议尽量使用用户模式。但用户模式也有一个缺点:只有windows操作系统内核才能停止一个线程的运行(防止它浪费cpu时间)。在用户模式中运行的线程可能被系统抢占(preempted),想要取得资源但暂时无法取到的线程会一直在用户模式中“自旋”。这回浪费大量cpu时间。
内核模式构造
内核模式的构造是是由windows操作系统自身提供的。所以,他们要求在应用程序的线程中调用由操作系统内核实现的函数。将线程从用户模式切换到内核模式(或相反)会导致巨大的性能损失,这正式为什么要避免使用内核模式构造的原因。但它们有一个重要的有点:线程通过内核模式的构造获取其他线程拥有的资源时,windows会阻塞线程以避免它浪费cpu时间。当资源变得可用时,windows会恢复线程,允许它访问资源。
对于一个等待的线程,如果不释放它,它就一直阻塞。如果是用户模式,线程将一直在cpu上运行,我们称为“活锁”。如果是内核模式,线程将一直阻塞,我们称为“死锁”。两种情况都不好,但在两者之间,死锁总是优于活锁,因为活锁既浪费cpu时间,又浪费内存(线程栈等),而死锁只浪费内存。
理想中的模式
构造应该兼具上面两种模式的长处。也就是说,在没有竞争的情况下,应该快而不会阻塞(用户模式)。但如果存在竞争,我希望它被操作系统内核阻塞。这种构造,我们称为混合构造(hybrid construct)。应用程序使用混合构造是很常见的现象。
用户模式构造
易变字段 VOLATILE
静态system.threading.volatile类提供了两个静态方法
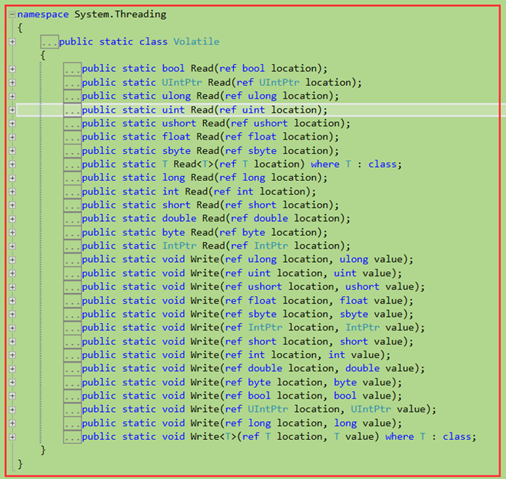
这个方法比较特殊,他们事实上会禁止c#编译器、jit编译器和cpu平常执行的一些优化。下面描述了这些方法是如何工作的。
1 Volatile.Write方法强迫location中的值在调用时写入。此外,按照编码顺序,之前的加载和存储操作必须在调用Volatile.Write之前发生
2 Volatile.Read方法强迫location中的值在调用时读取。此外,按照编码顺序,之后的加载和存储操作必须必须在调用Volatile.Read之后发生。
这样会避免编译器对你的代码进行了过度的优化,提前赋值数据。当然,你也可以使用volatile关键字,不过我并不喜欢这么做,因为大多时候,你的读取或写入顺序都可以按照正常方式进行,这样效率更高。你可以在用必要的时候显示调用Volatile类的方法,这样程序的性能更好。
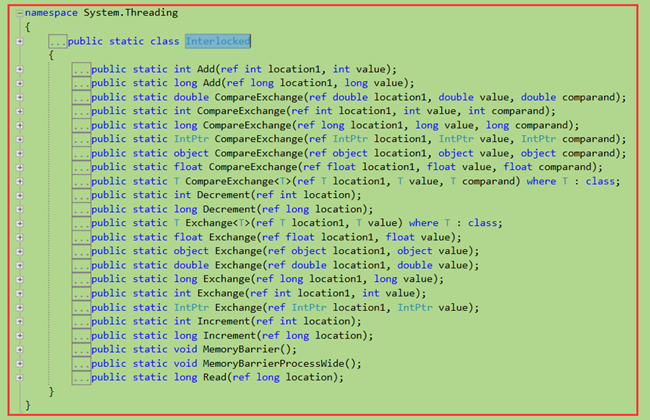
互锁构造 interlocked
volatile的read方法执行一次原子性的读取操作,write方法执行一次原子性的写入操作。本节我们讨论静态system.threading.interlocked类提供的方法。interlocked类中的每个方法都执行一次院子读取以及写入操作。此外,interlocked的所有方法都建立了完整的内存栅栏(memory fence)。换言之,调用某个interlocked方法之前的任何变量写入都在这个interlocked方法调用之前执行;而这个调用之后的任何变量读取都在这个调用之后读取。
interlocked方法的运行速度相当快,而且能做不少事情。下面我们有一个简单的例子,使用interlocked方法异步查询几个web服务器,并同时处理返回数据。代码很短,而且不阻塞任何线程,而且使用线程池来实现自动伸缩。
internal enum CoordinationStatus { AllDone, Timeout, Cancel } internal sealed class MultiWebRequests { //这个辅助类用于协调所有异步操作 private AsyncCoordinator m_ac = new AsyncCoordinator(); //这是想要查询的web服务器及其响应(异常或int32)的集合 //注意:多个线程访问该字典不需要以同步方式进行 //因为构造后键就是只读的 private Dictionary<String, Object> m_servers = new Dictionary<string, object> { {"https://www.baidu.com/" ,null}, {"https://www.microsoft.com/zh-cn/",null}, {"https://www.taobao.com/",null} }; public MultiWebRequests(Int32 timeout=Timeout.Infinite) { var httpClient = new HttpClient(); foreach (var server in m_servers.Keys) { m_ac.AboutToBegin(1); httpClient.GetByteArrayAsync(server).ContinueWith(task => ComputeResult(server, task));//task是Task<byte[]>类型 } //告诉AsyncCoordinator所有操作都已发起,并在所有操作完成 //调用cancel或者发生超时的时候调用AllDone m_ac.AllBegun(AllDone, timeout); } //将结果保存到集合中,然后将完成状态进行通知 private void ComputeResult(string server, Task<Byte[]> task) { object result; if (task.Exception!=null) { result = task.Exception.InnerException; } else { //线程池线程处理I/O完成 //在此添加自己的计算密集型算法。。。。 result = task.Result.Length; } //保存结果(exception/sum),指出一个操作完成 m_servers[server] = result; m_ac.JustEnded(); } //调用这个方法指出结果已无关紧要 public void Cancel() { m_ac.Cancel(); } //所有web服务器都响应、调用了cancel或者发生超时,就调用该方法,显示执行结果 private void AllDone(CoordinationStatus status) { switch (status) { case CoordinationStatus.Cancel: Console.WriteLine("operation canceled"); break; case CoordinationStatus.Timeout: Console.WriteLine("operation time-out"); break; case CoordinationStatus.AllDone: Console.WriteLine("operation completed;results below;"); foreach (var server in m_servers) { Console.WriteLine("{0}",server.Key); object result = server.Value; if (result is Exception) { Console.WriteLine("failed due to {0}",result.GetType().Name); } else { Console.WriteLine("returned {0} bytes",result); } } break; } } }
可以看出,上述代码并没有直接使用interlocked的任何方法,因为我将所有协调代码都放到可重用的AsyncCoordinator类中。如下
internal sealed class AsyncCoordinator { //AllBegun内部调用justended来递减它 private Int32 m_opCount = 1; //0 = false 1= true private Int32 m_statusReported = 0; private Action<CoordinationStatus> m_callback; private Timer m_timer; //该方法必须在发起一个操作之前调用 public void AboutToBegin(Int32 opsToAdd=1) { //返回的是计算之后的m_opCount的值 Interlocked.Add(ref m_opCount, opsToAdd); } //该方法必须在处理好一个操作的结果之后调用 public void JustEnded() { if (Interlocked.Decrement(ref m_opCount)==0) //返回的是计算之后的m_opCount的值 { ReportStatus(CoordinationStatus.AllDone); } } //该方法必须在发起所有操作之后调用 public void AllBegun(Action<CoordinationStatus> callback,Int32 timeout=Timeout.Infinite) { m_callback = callback; if (timeout!=Timeout.Infinite) { m_timer = new Timer(TimeExpired, null, timeout, Timeout.Infinite); } //相当于多减了一次,对冲初始化把m_opCount设置为1的多出来的1 JustEnded(); } private void TimeExpired(object o) { ReportStatus(CoordinationStatus.Timeout); } public void Cancel() { ReportStatus(CoordinationStatus.Cancel); } private void ReportStatus(CoordinationStatus status) { //这个用来判断状态是否是从未报告过;只有第一次调用这个方法的状态才会被记录 if (Interlocked.Exchange(ref m_statusReported,1)==0)//这个将m_statusReported的值变为1,并返回m_statusReported原有的值 { m_callback(status); } } }
执行结果
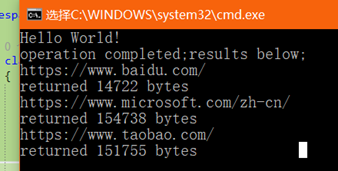
构造一个MultiWebRequests时,会先初始化一个AsyncCoordinator和包含了一组服务器uri的字典。然后,它以异步方式一个接一个地发出所有web请求。为此,他首先调用AsyncCoordinator的AboutToBegin方法,想他传递要发出的请求数量(这里也可以一次把所有要执行请求的数量发给AboutToBegin)。然后,他调用httpClient.GetByteArrayAsync(server)初始化请求,这回返回一个task,ContinueWith执行computeResult方法,它可以并发处理结果。所有请求都发出后,将调用AsyncCoordinator的AllBegun方法,向他传递要在所有操作完成后执行的方法(AllDone)以及一个超时值。每收到一个响应,线程池都会调用computeResult进行后续处理任务,computeResult保存请求结果之后最后会调用JustEnded,使AsyncCoordinator知道一个对象已经执行完成。
JustEnded方法判断出所有任务都已经执行完成后,会调用回调(AllDone)处理来自所有web服务器的结果。执行AllDone方法的线程就是获取最后一个web服务器响应的那个线程池线程。但如果发生超时或者调用cancel方法的那个线程,调用AllDone的线程就是向asyncCoordinator通知超时的那个线程池线程,或者调用cancel方法的那个线程。
注意,这里存在竞态条件,因为以下事情可能恰好同时发生:所有web服务器请求完成、调用Allbegun、发生超时以及调用cancel。这时,AsyncCoordinator会选择1个赢家和3个输家,确保alldone不被多次调用。赢家是通过传给AllDone的status实参来识别的。
AsyncCoordinator类封装了所有线程协调逻辑。他用interlocked提供的方法来操作一切,确保代码以极快速度运行,同时并没有线程会被阻塞。

AsyncCoordinator类最重要的字段就是m_opCount,用于跟踪仍在进行的一步操作的数量。每个异步操作开始前都会调用AboutToBegin。该方法调用interlocked.Add,以院子方式将传给它的数字加到m_opCount字段上,m_opCount上的运算必须以原子方式进行。处理好web服务器的响应之后会调用justEnded,该方法调用interlocked.Decerment,以院子方式从m_opCount上减1.当opCount等于0时,由这个线程调用ReportStatus。
注意:m_opCount字段初始化为1(而非0),这一点很重要。执行构造器方法的线程在发出web服务器请求期间,由于m_opCount字段位1,所以能保证AllDone不会被调用。构造器调用AllBegun之前,m_opCount永远不可能变为0。构造器调用allBegun时,会执行一次justEnded方法来递减m_opCount,所以事实上撤掉了把它初始化为1的效果。
实现简单的自旋锁
Interlocked的方法很好用,但是主要用于操作Int值。如果需要原子性地操作类对象中的一组字段,又该怎么办呢?在这种情况,需要采取一个办法阻止所有线程,只允许其中一个进入对字段进行操作的。可以使用Interlocked的方法构造一个线程同步块。
internal struct SimpleSpinLock { private Int32 m_ResourceInUse;// 0=false(默认) 1 =true public void Enter() { while (true) { //总是将资源设为“正在使用”(1) //只有从“未使用”编程“正在使用”才会返回 if (Interlocked.Exchange(ref m_ResourceInUse,1)==0) { return; } //在这里添加“黑科技” } } public void Leave() { //将资源标记为“未使用” Volatile.Write(ref m_ResourceInUse, 0); } }
下面这个类展示了如何使用SimpleSpinLock
public sealed class SomeResource { private SimpleSpinLock m_sl = new SimpleSpinLock(); public void AccessResource() { m_sl.Enter(); //一次只有一个线程才能进入这里访问资源 m_sl.Leave(); } }
这个锁很简单,他的最大问题是会造成线程“自旋”,自旋会浪费cpu时间。
SpinLock是.net已经实现的自旋锁,他和我们前面举例的SimpleSpinLock类似,只是使用了spinwait结构来增强性能(SpinWait在自旋中加入sleep方法,使他在一段时间内不占用cpu时间),还增加了超时支持。
这篇我们暂时介绍以上概念,下篇文字我们一起了解内核模式。