首先是安装scala插件,可以通过idea内置的自动安装方式进行,也可以手动下载可用的插件包之后再通过idea导入。
scala插件安装完成之后,新建scala项目,右侧使用默认的sbt
点击Next,到这一步就开始踩坑了,scala的可选版本比较多,从2.12到2.10都有,我的环境下用wordcount的例子尝试了几种情况:
先贴上测试代码,以下的测试全都是基于这段代码进行的。
package com.hq import org.apache.spark.SparkConf import org.apache.spark.SparkContext object WordCount { def main(args: Array[String]) { if (args.length < 1) { System.err.println("Usage: <file>") System.exit(1) } val conf = new SparkConf() val sc = new SparkContext("local","wordcount",conf) val line = sc.textFile(args(0)) line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println) sc.stop() } }
1. scala如果用2.12.4的版本,运行时就会报错。可能跟我写的代码有关,scala 2.12.x使用spark的方式可能不一样,后面再看。不过官网上有说spark-2.2.1只能与scala-2.11.x兼容,所以这个就没有再试了

2. scala如果使用2.11.x的版本,我这边最初按照网上的各种教程,一直在尝试使用spark-assembly-1.6.3-hadoop2.6.0.jar,结果也是报错。

然后想着试一下最新的spark-2.2.1-bin-hadoop2.7,但是里面没有spark-assembly-1.6.3-hadoop2.6.0.jar,就索性把jars目录整个加到工程中,运行也是出错,但明显是能运行了。
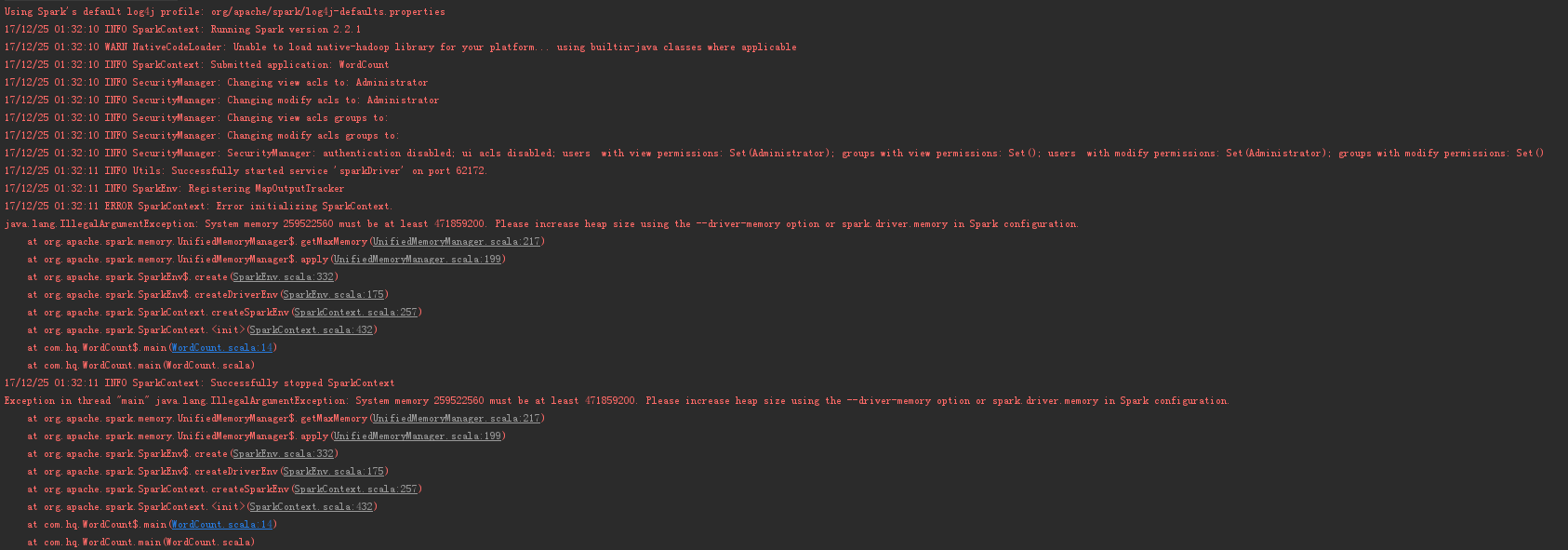
百度之,加上一句设置就可以了
conf.set("spark.testing.memory", "2147480000")
3. scala如果使用2.10.x,根据网上的各种教程,我使用的是2.10.6,只需要在工程中加入spark-assembly-1.6.3-hadoop2.6.0.jar这个包即可,当然,还有内存大小的配置。
另外,在使用2.10.6的时候,idea在下载scala-library, scala-compiler, scala-reflect各种包时都出错,只能手动下载,再放到缓存目录下: "C:UsersAdministrator.ivy2cacheorg.scala-lang"。
顺便收藏一个网址,也许以后还要用: http://mvnrepository.com/artifact/org.scala-lang/scala-library
待处理的问题:
1. 运行时内存大小的设置,应该可以通过修改idea的配置项来做到,就不用在代码里面加这个
2. idea的缓存目录还需要修改,不然用的时间长了,C盘要崩...
3. 虽然wordcount运行成功了,但是会有warning...