subprocess
Python引入subprocess模块来管理子进程,以取代一些旧模块的方法:如 os.system、os.spawn*、os.popen*、popen2.*、commands.*不但可以调用外部的命令作为子进程,而且可以连接到子进程的input/output/error管道,获取相关的返回信息
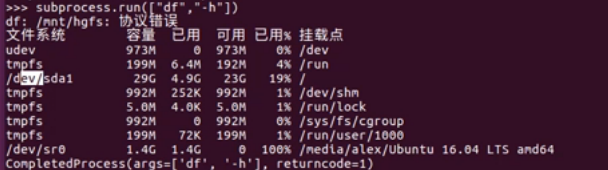
run(['df','-h']) 命令作为参数传递过去
如果有管道符 就不能用上面那种方式了,把整个参数作为字符串,指定shell=True

一、subprocess以及常用的封装函数
运行python的时候,我们都是在创建并运行一个进程。像Linux进程那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序。在Python中,我们通过标准库中的subprocess包来fork一个子进程,并运行一个外部的程序。
subprocess包中定义有数个创建子进程的函数,这些函数分别以不同的方式创建子进程,所以我们可以根据需要来从中选取一个使用。另外subprocess还提供了一些管理标准流(standard stream)和管道(pipe)的工具,从而在进程间使用文本通信。
subprocess.call()
父进程等待子进程完成
返回退出信息(returncode,相当于Linux exit code)
subprocess.check_call()
父进程等待子进程完成
返回0
检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含有returncode属性,可用try…except…来检查
subprocess.check_output()
父进程等待子进程完成
返回子进程向标准输出的输出结果
检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含有returncode属性和output属性,output属性为标准输出的输出结果,可用try…except…来检查。
这三个函数的使用方法相类似,下面来以subprocess.call()举例说明:
>>> import subprocess
>>> retcode = subprocess.call(["ls", "-l"])
#和shell中命令ls -a显示结果一样
>>> print retcode
0
将程序名(ls)和所带的参数(-l)一起放在一个表中传递给subprocess.call()
shell默认为False,在Linux下,shell=False时, Popen调用os.execvp()执行args指定的程序;shell=True时,如果args是字符串,Popen直接调用系统的Shell来执行args指定的程序,如果args是一个序列,则args的第一项是定义程序命令字符串,其它项是调用系统Shell时的附加参数。
上面例子也可以写成如下:
在Windows下,不论shell的值如何,Popen调用CreateProcess()执行args指定的外部程序。如果args是一个序列,则先用list2cmdline()转化为字符串,但需要注意的是,并不是MS Windows下所有的程序都可以用list2cmdline来转化为命令行字符串。
subprocess.Popen()
class Popen(args, bufsize=0, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=False, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0)
实际上,上面的几个函数都是基于Popen()的封装(wrapper)。这些封装的目的在于让我们容易使用子进程。当我们想要更个性化我们的需求的时候,就要转向Popen类,该类生成的对象用来代表子进程。
与上面的封装不同,Popen对象创建后,主程序不会自动等待子进程完成。我们必须调用对象的wait()方法,父进程才会等待 (也就是阻塞block),举例:
>>> child = subprocess.Popen(['ping','-c','4','blog.linuxeye.com'])
>>> print 'parent process'
从运行结果中看到,父进程在开启子进程之后并没有等待child的完成,而是直接运行print。
对比等待的情况:
>>> child = subprocess.Popen('ping -c4 blog.linuxeye.com',shell=True)
>>> child.wait()
>>> print 'parent process'
从运行结果中看到,父进程在开启子进程之后并等待child的完成后,再运行print。
此外,你还可以在父进程中对子进程进行其它操作,比如我们上面例子中的child对象:
child.poll() # 检查子进程状态
child.kill() # 终止子进程
child.send_signal() # 向子进程发送信号
child.terminate() # 终止子进程
子进程的PID存储在child.pid
二、子进程的文本流控制
子进程的标准输入、标准输出和标准错误如下属性分别表示:
child.stdin
child.stdout
child.stderr
可以在Popen()建立子进程的时候改变标准输入、标准输出和标准错误,并可以利用subprocess.PIPE将多个子进程的输入和输出连接在一起,构成管道(pipe),如下2个例子:
>>> child1 = subprocess.Popen(["ls","-l"], stdout=subprocess.PIPE)
>>> print child1.stdout.read(),
#或者child1.communicate()
>>> import subprocess
>>> child1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE)
>>> child2 = subprocess.Popen(["grep","0:0"],stdin=child1.stdout, stdout=subprocess.PIPE)
>>> out = child2.communicate()
subprocess.PIPE实际上为文本流提供一个缓存区。child1的stdout将文本输出到缓存区,随后child2的stdin从该PIPE中将文本读取走。child2的输出文本也被存放在PIPE中,直到communicate()方法从PIPE中读取出PIPE中的文本。
注意:communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成