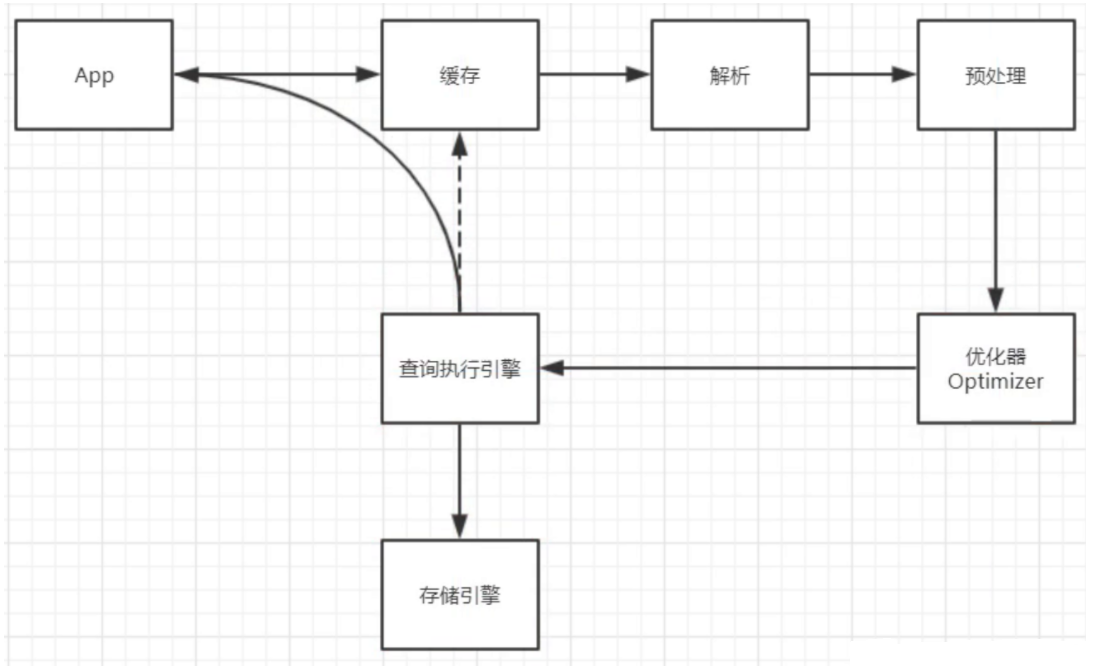
一条查询语句是如何执行的
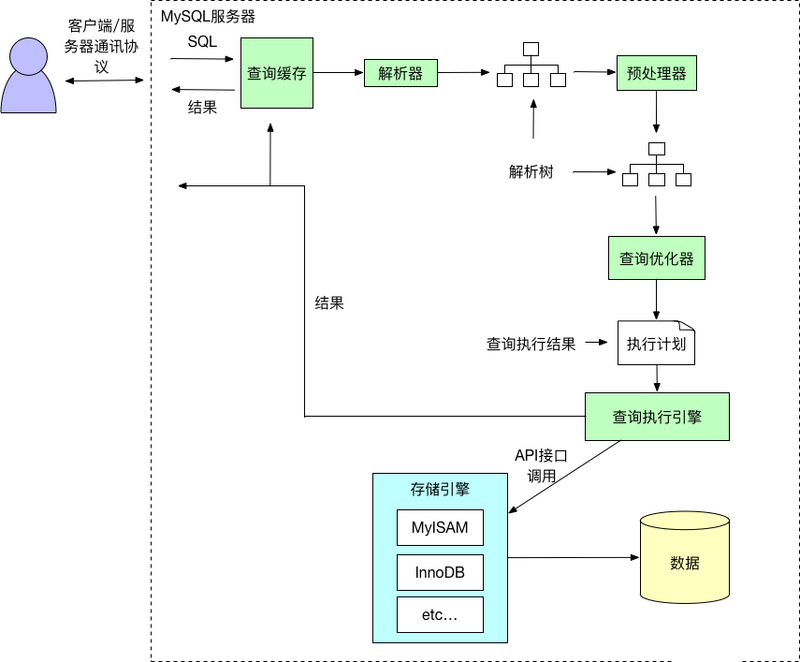
查询语句的执行分为以下几步:
- 查询缓存
- 解析器生成解析树
- 预处理再次生成解析树
- 查询优化器
- 查询执行计划
- 查询执行引擎
- 查询数据返回结果
查询缓存
通过如下语句可查看缓存开关情况(默认关闭):show variables like 'query_cache%';
1.MySQL 拿到一个查询请求后先会在查询缓存中看看是否执行过此语句,之前执行的语句会以 key-value 的形式缓存在内存中,key 是缓存的语句,value 是查询的结果
2.如果命中缓存则直接将结果返回,如果没有命中则继续执行后面
在 MySQL 中默认是关闭的,官方也建议关闭,将缓存交托给第三方如 redis 处理,为啥:
查询缓存的失效特表频繁,对一个表的更新都会失效这个表所有的查询缓存,对于更新频繁的表命中率太低
MySQL 8.0 直接删除查询缓存
解析器生成解析树
- 语法解析
语法解析是解析你的语句是不是满足 MySQL 语法标准,如果不对则会 :
ERROR 1064 (42000): You have an error in your SQL syntax … 关于错误码在官网有说明
- 词法解析
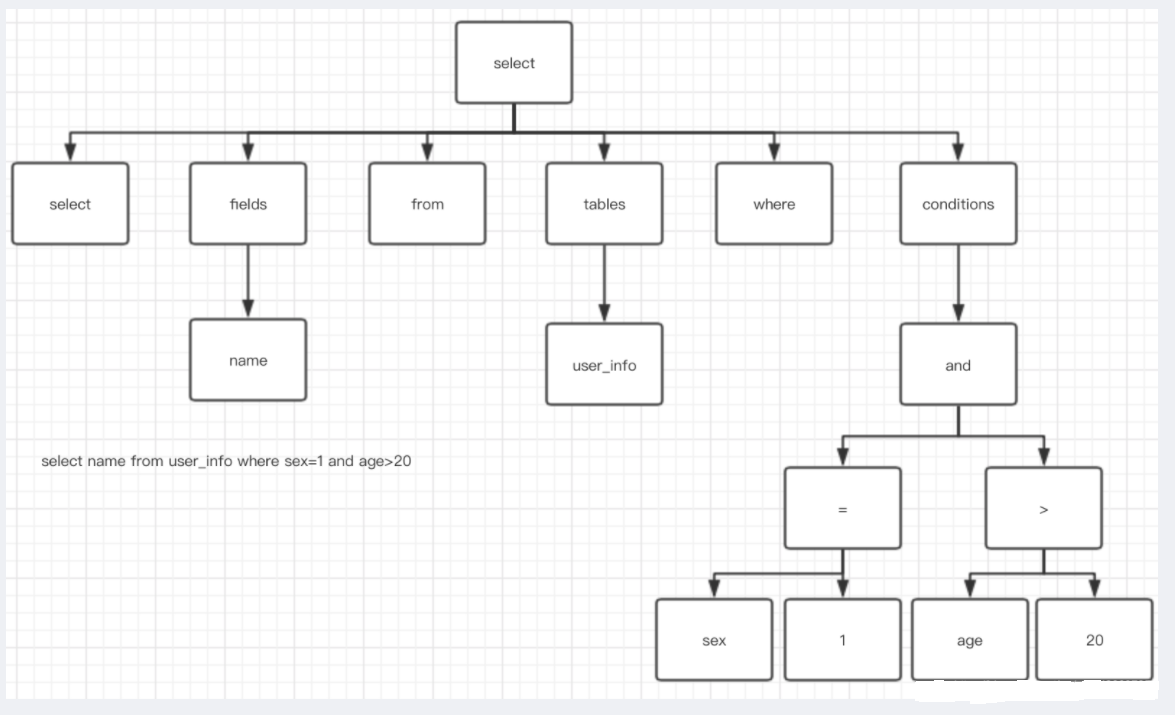
关于解析完生成的解析树类似下图,我以’select name from user_info where sex=1 and age>20’为例:
预处理再次生成解析树
语义解析,在语法及词法解析完之后,进行预处理之后再次生成解析树。
查询优化器
在这一步将前面生成的解析树优化成一个执行计划。
在这步做的事情主要有:
- 选择最合适的索引;
- 选择表扫还是走索引;
- 选择表关联顺序;
- 优化 where 子句;
- 排除管理中无用表;
- 决定 order by 和 group by 是否走索引;
- 尝试使用 inner join 替换 outer join;
- 简化子查询,决定结果缓存;
- 合并试图;
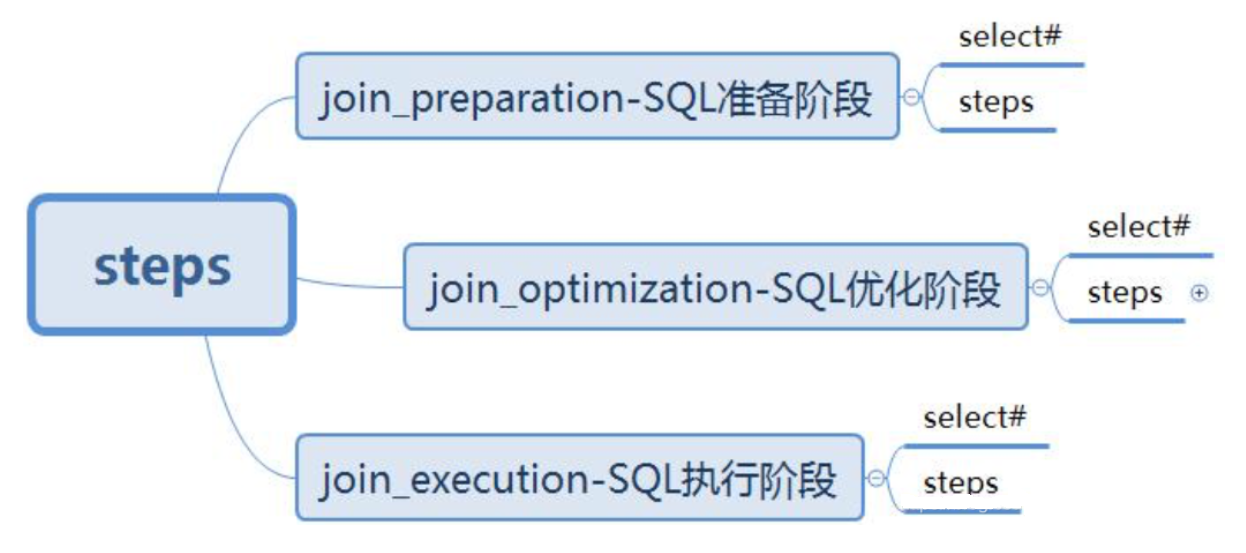
顺便提一下,optimizer_trace 优化器追踪器,在 MySQL 中是默认关闭的(毕竟开启也会消耗性能嘛对吧),可以使用 set 语句修改一下 optimizer_trace的开关,感受一下:set optimizer_trace='enabled=on '
先查询优化器追踪的开关:show variables like 'optimizer_trace%';
执行完一条语句之后执行下面语句查看优化器追踪:select * from information_schema.optimizer_traceG
可以看到一个 json 类型的字符串,主要是语句优化的三个阶段,篇幅有限,这里不展开,对照着看应该可以看懂。
查询执行计划
查询最后一次查询的消耗,用以比较开销:show status like 'Last_query_cost';
在这一步选择开销最小的计划执行
查询执行引擎
这里执行器会先对权限做一个判断,如果有权限,才会执行以下步骤,否则跑出权限异常:
调用 Innodb 引擎接口获取这个表的第一行,判断ID是否为10,如果不是跳过,如果是则存在结果集中;
引擎执行下一行,重复判断相同的逻辑,直到最后一行;
最后将满足结果的结果集返回;
对于有索引的表也差不多,第一次是调用满足结果的第一行接口, 下来是查找满足结果的下一行接口
查询数据返回结果
将查询数据的结果返回给查询的客户端,如果有缓存则返回缓存(前面已经说了默认关闭)。