
每个部门的平均工资是不一样的;
--from子句中使用查询
分析:
1.首先要知道各个部门的平均工资
select avg(sal), deptno from emp group by deptno

2.把上面的查询结果当做一个临时表对待
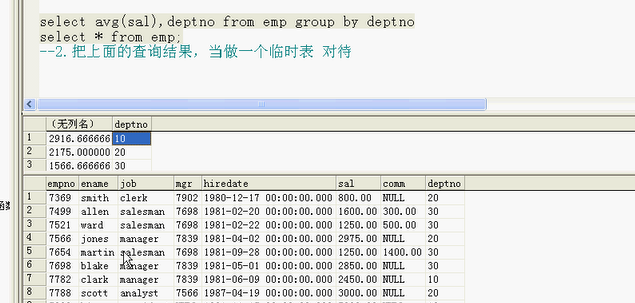
两张表,sal进行比较

tem 临时表
tem表和emp表关联起来:
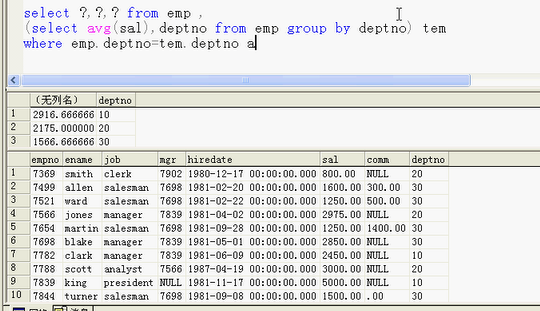
给所在部门的平均工资取别名 myavg

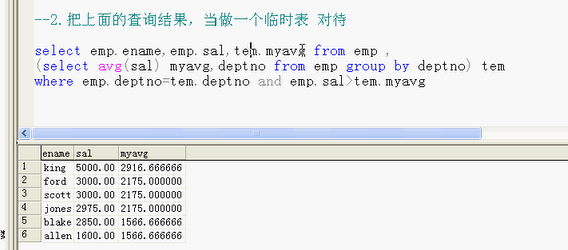

不给子查询取别名,会访问不到需要的字段;
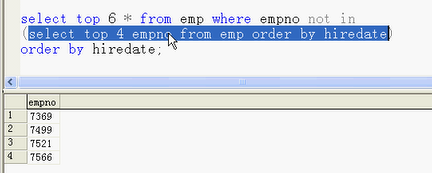
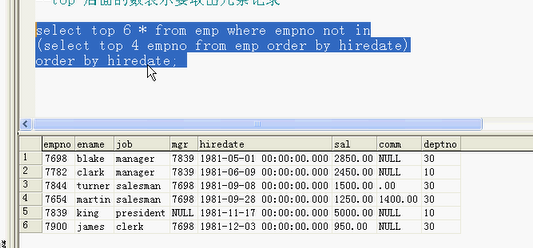
--top ID *
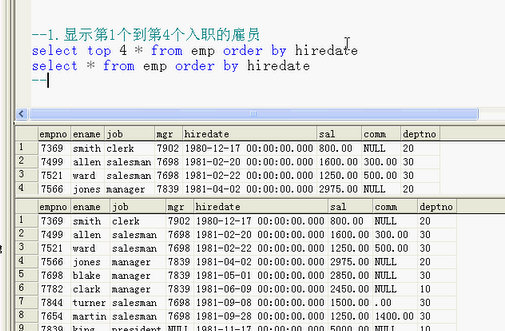
top 取5到10个
top 后面的数表示要取出几条记录;
top挑出6条,从emp表来,编号不能在xxx里面 not in
排除不要的4个人,排除前4个人;


top查询:
100万条记录,1-2秒钟可以出结果
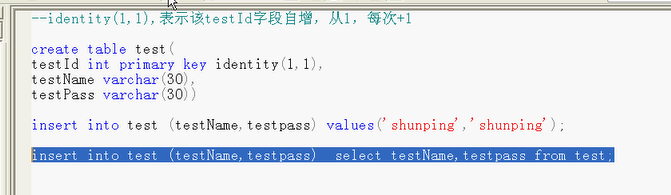
identity(1, 1)表示该字段testID字段自增长,从1,每次+1
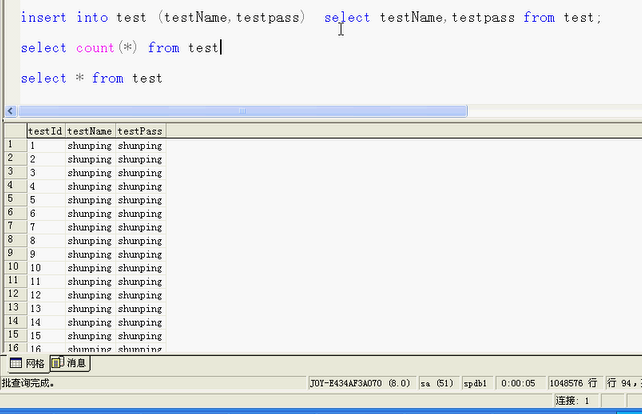
通过这条语句进行疯狂地复制,用于压力测试;
insert into test (testName, testpass)
select testName, testpass
from test;
比如用于邮件服务器的压力测试;
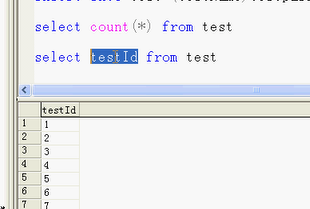
字段越多,速度越慢;上百万的数据,分页查询,越到最后,速度越慢;
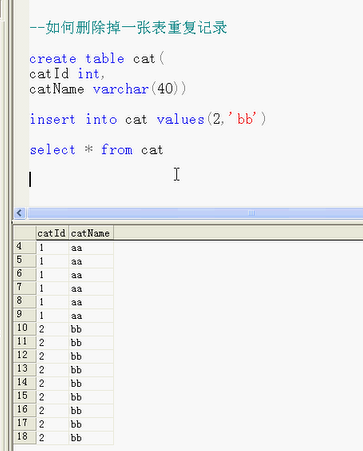
--如何删除一张表中的重复记录
1.select distinct * into #temp3 from cat
2.delete from cat
3.insert into cat select * from #temp3
4.drop table #temp3
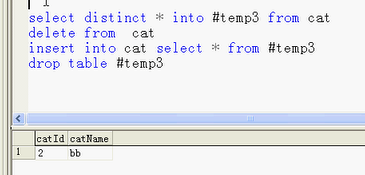
1.把cat表的记录distinct后的结果放入到临时表#temp3中
2.把cat表的记录清空
3.把#temp表的数据(没有重复的记录),插入到cat表中 ;
4.删除临时表#temp3
--左外连接和右外连接

-要求没有上级的人名字也要显示出来null
left join 左外连
where换成on

select w.ename, b.ename
from emp w left join emp b on w.mgr=b.empno
左外连接:
指左边的表的记录全部显示,
如果 没有匹配的记录就用null填
emp w 表的记录全部出现;

--内连接:只有匹配上的才会出现
inner join xx on



--左外连接和右外连接
--思考题:显示公司每个员工和他的上级领导的名字
--内连接的处理方式(内连接只显示匹配的信息)
select worker.ename"员工名字",boss.ename"领导名字" from emp worker,emp boss where worker.mgr=boss.empno
--思考题:显示公司每个员工和他的上级领导的名字,没有上级领导的也要显示出来
--左外连接:指如果左边的表记录全部显示,如果没有匹配的记录,就用null填写
select worker.ename"员工名字",boss.ename"领导名字" from emp worker left join emp boss on worker.mgr=boss.empno
--右外连接:指如果右边的表记录全部显示,如果没有匹配的记录,就用null填写
select worker.ename"员工名字",boss.ename"领导名字" from emp worker right join emp boss on worker.mgr=boss.empno