背景
疫情初期某地政府决定发放一批免费口罩面向该市市民,该市市民均可免费预约领取,预约时间为早上9点-12点,因此该场景为限时抢购类型场景,会面临非常大的定时超大流量超大并发问题,在该项目的落地过程中,涉及的架构演变,做了一些记录和思考。
架构图&分析-V1
原始架构图示&分析(2月2号晚上22点左右的原始架构)
2月2号晚上22点左右的原始架构
客户端走 HTTPS 协议直接访问 ECS;
ECS 上使用 Nginx 监听 HTTPS 443 端口;
Nginx 反代 Tomcat,Nginx 处理静态文件,Tomcat 处理动态请求;
程序先去 Redis 查缓存,如未命中则去数据库查询数据,同时Redis 与 Mysql 之间的数据同步靠程序控制。
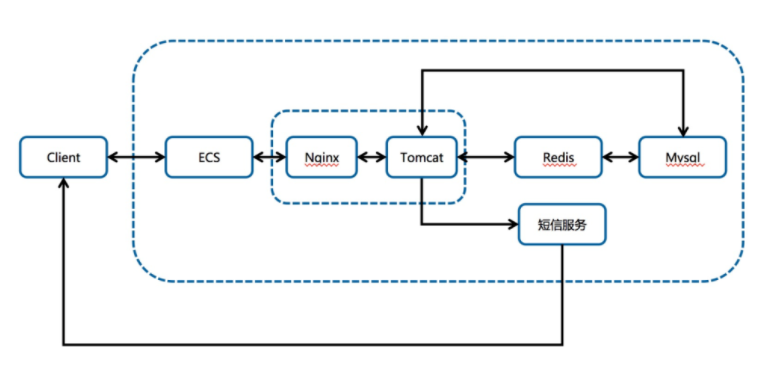
这样架构设计:
优点:易管理,易部署;
缺点:性能差,无扩展性,存在单点风险;
结果:事实证明该应用一经上线就立刻被打挂了,因未知原因预约页面被泄露,导致还未到预约时间,服务即被打挂。
架构图&分析-V2
随后我方介入,进行架构调整,24点左右找的我们,早上9点要开服,时间太紧,任务太重,程序不能动的情况下,几十万的并发架构如何做?
2月3号早上9点左右的架构,4号也恢复了这个架构)
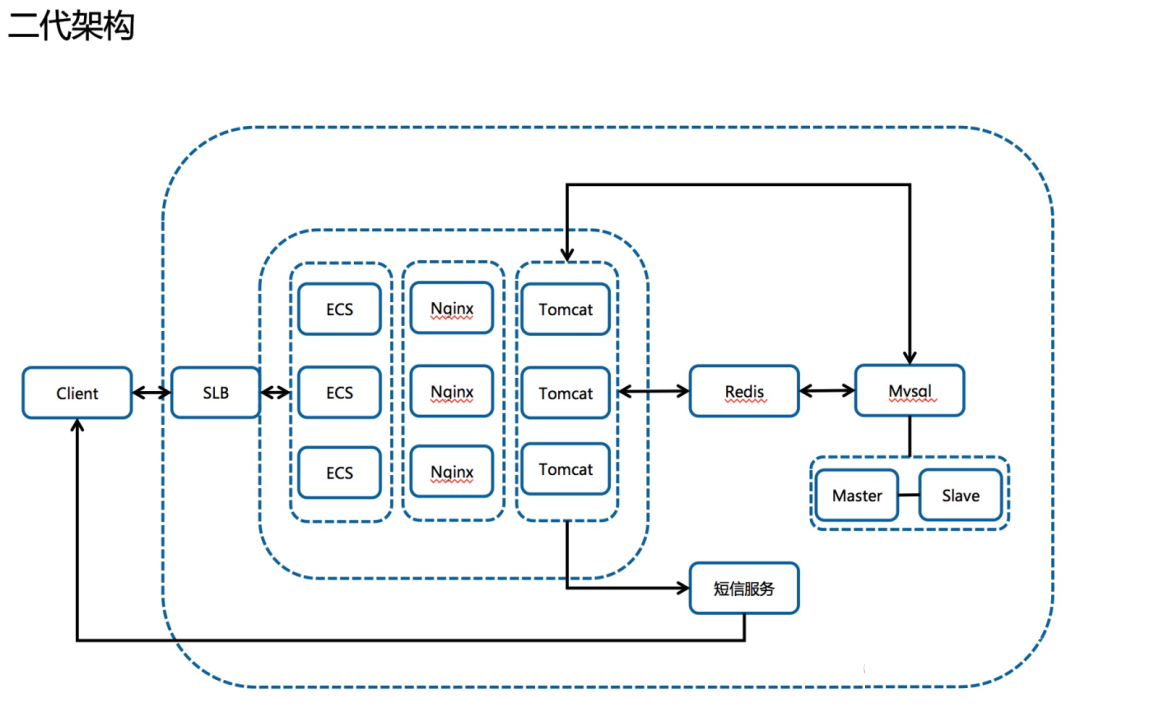
2月3号早上9点左右的架构
接入 SLB,通过镜像横向扩展负载能力;
接入读写分离数据库架构,通过阿里云数据库自动进行读写分离,自动同步数据;
调整 Nginx 协议;
同架构备集群启用(域名解析做了两个A记录);
分析访问日志发现失败原因在获取短信和登陆初始化 Cookie 的点上。
这样架构设计:
优点:增加了高可用性,扩展了负载能力;
缺点:对流量预估不足,静态页面也在 ECS 上,因此 SLB 的出带宽一度达到最大值 5.X G,并发高达 22w+。
结果:因为流量太大导致用户一度打不开页面,同时由于域名服务商 XX 的限制,客户无法自助添加解析,且当晚联系不到域名服务商客服,导致 CDN 方案搁浅。
架构图&分析-V3
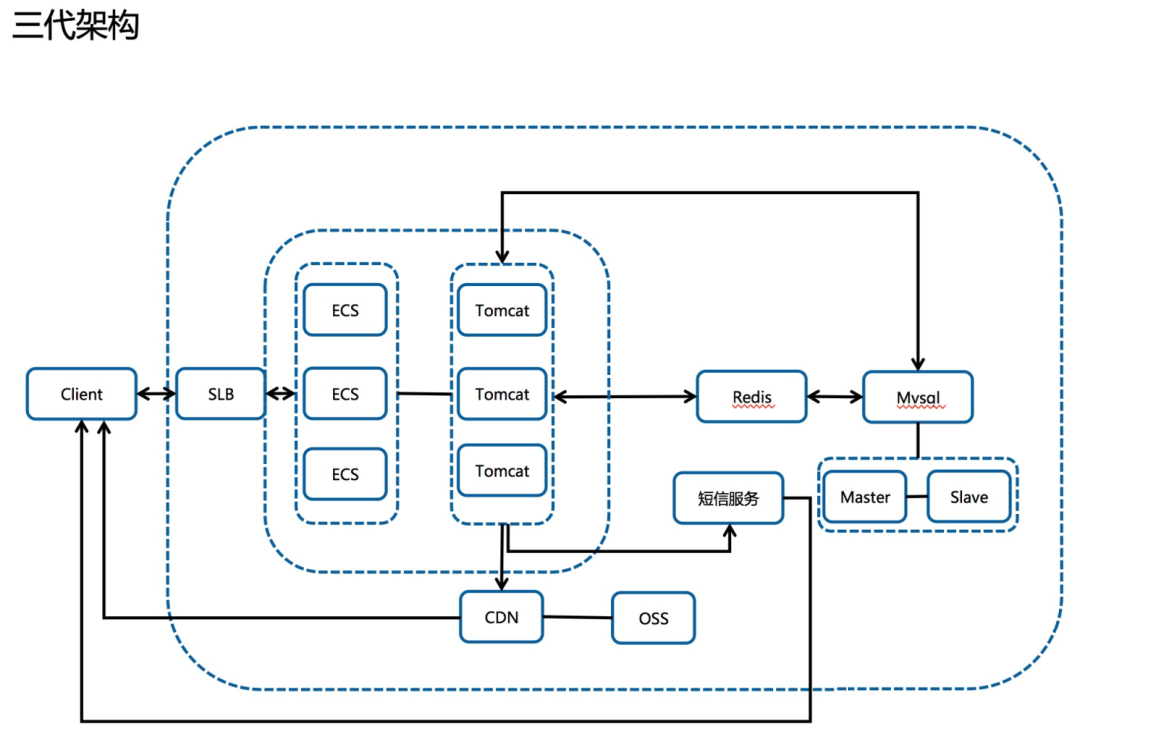
2月5号的架构
接入 CDN 分流超大带宽;
取消 Nginx 的代理;
做了新程序无法准时上线的灾备切换方案(没想到还真用到了);
使用虚拟服务器组做新老程序的切换,但是缺点是一个七层监听的 SLB 后端只能挂 200 个机器,再多 SLB 也扛不住了,导致老程序刚承接的时候再度挂掉;
5 号使用这个架构上线,7 分钟库存售罄,且体验极度流程,丝般顺滑,健康同学开发的新程序真是太爽的。
这样架构设计:
优点:CDN 负担静态资源的流量降低了 SLB 的出带宽,压测的效果也非常理想;
缺点:需要多一个独立的域名在页面里面,涉及跨域,4 号临开服之际测试发现入库&预约短信乱码返回,紧急切换回了老程序,即二代架构。
理想架构图&分析-V4
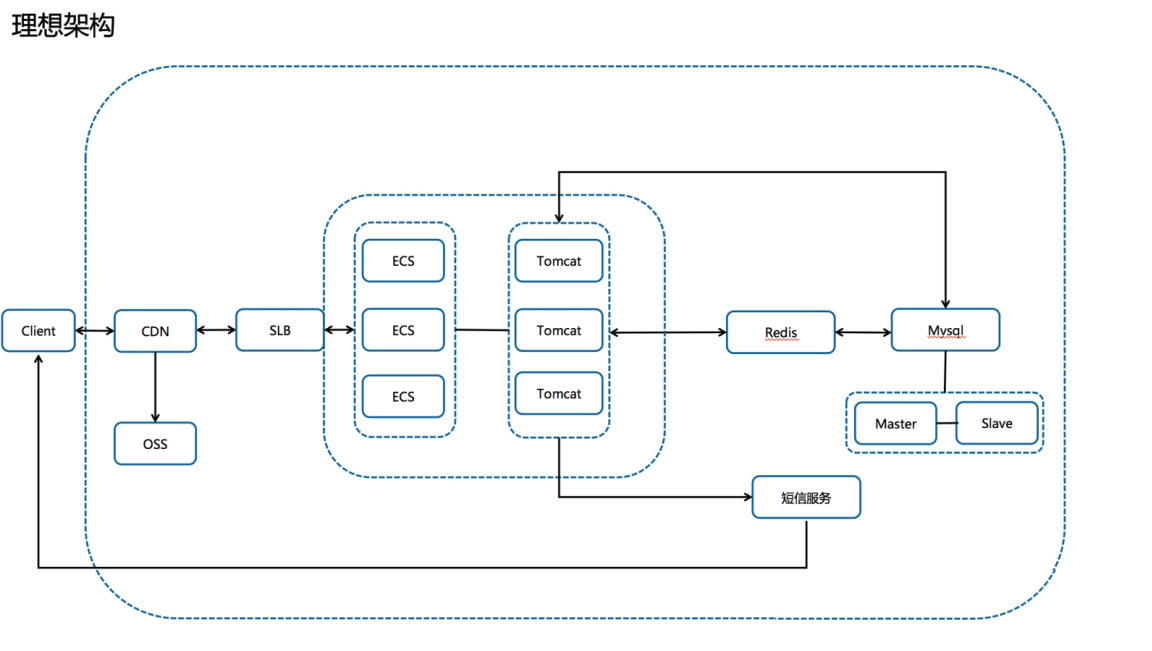
理想架构
主域名接入CDN;
CDN通过设置回源 Http、Https 协议去访问 SLB 的不同监听实现新老程序之间的切换,具体实现为回源协议对应。不同监听,监听对应不同的程序。
这样架构设计:
优点:静态加速降低SLB带宽,动态回源,无跨域问题,切换方便;
缺点:仍需手工设置,镜像部署ecs不方便,如果时间充足,可以直接上容器的架构该有多美好呢,一个 scale 可以扩出来几十上百的 pod,也可以做节点自动扩容。
总结
时间紧任务重,遇到了N多的坑:
vcpu 购买额度;
SLB 后端挂载额度;
客户余额不足欠费停机;
域名服务商解析需要联系客服才能添加;
第一次考虑 CDN 架构的时候未考虑跨域问题;
新程序开发期间未连接主库测试,导致上线失败(主库乱码);
第一次(3号)被打挂的时候只关注了 SLB 的流量,未详细分析失败最多的环节;
上线前压测缺失,纯靠人工测试功能;
压测靠人手一台 Jmeter(4号晚上到5号早上引入了 PTS 进行压测);
突然想起来客户原始的程序是放在 Windows上的,Windows + 烂程序性能真的极差;
这个“小项目”前后竟然耗费了小十万,如果一开始就给我们做的话,应该可以减少一半的成本。
最后的成果统计(采样分析,实际数据比这个还大):
| 一树数据统计 | UA | 并发 | QPS | 带宽 | ECS集群数量 | 程序版本 | 备注 |
|---|---|---|---|---|---|---|---|
| 20200203 | 348966 | 221947 | 18534 | 5G | 293 | 老程序 | 持续五小时,崩溃堆积 |
| 20200204 | 157830 | 123143 | 14141 | 4G | 284 | 老程序 | 持续五小时,崩溃堆积 |
| 20200205 | 144893 | 63434 | 4248 | 1.3G | 150 | 老程序 | 7分钟库存售罄,体验非常流畅 |
最后上线的三代架构,为了保险起见上了 150 台机器,但是根据活动期间的观察,以及对压测结果的评估,上 50 台机器应该就可以抗住了,从持续 5 小时一直崩溃被终端用户骂街,到 7 分钟库存售罄的领导赞赏,虽然经历了 3 个通宵的戮战,依然可以隐隐约约感觉到身心都得到了升华。
各种优化笔记
参数优化
网络调参
net.ipv4.tcp_max_tw_buckets = 5000 --> 50000
net.ipv4.tcp_max_syn_backlog = 1024 --> 4096
net.core.somaxconn = 128 --> 4096
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_timestamps = 1(5和6同时开启可能会导致nat上网环境建联概率失败)
net.ipv4.tcp_tw_recycle = 1
/etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
nginx参数优化
worker_connections 1024-->10240;
worker_processes 1-->16;(根据实际情况设置,可以设置成auto)
worker_rlimit_nofile 1024-->102400;
listen 80 backlog 511-->65533;
部分场景也可以考虑nginx开启长连接来优化短链接带来的开销
架构优化
扩容SLB后端ECS数量,ECS 配置统一;
Nginx 反代后端 upstream 无效端口去除;
云助手批量处理服务,参数优化,添加实例标识;(划重点,大家批量使用 ECS,可以考虑利用云助手这个产品)
云监控大盘监控,ECS、SLB、DCDN、Redis等;
调整 SLB 为 7 层监听模式,前 7 后 4 关闭会话保持导致登录状态失效。
程序优化
添加 GC log,捕捉 GC 分析问题,设置进程内存;
/usr/bin/java -server -Xmx8g -verbose:gc -XX:+PrintGCDetails -Xloggc:/var/log/xxxx.gc.log -Dserver.port=xxxx -jar /home/app/we.*****.com/serverboot-0.0.1-SNAPSHOT.jar
优化短信发送逻辑,登陆先查询 Redis 免登 Session,无免登 Session 再允许发送短信验证码(降短信的量,优化登陆体验);
jedis连接池优化;
maxTotal 8-->20
acceptcount优化(对标somaxconn)
bug:springboot1.5 带的 jedis2.9.1 的 Redis 连接泄漏的问题,导致 Tomcat 800 进程用满后都无限等待 Redis 连接。后来进一步调研发现这个问题在 2.10.2 已经修复,而且 2.10.2 向后兼容 2.9.1。
数据库优化
Redis 公网地址变更为内网地址;
Redis Session 超时设置缩短,用于释放 Redis 连接;
慢SQL优化(RDS的 CloudDBA 非常好用);
添加只读实例,自动读写分离;
优化 backlog;
添加读写分离实例数量。