TiDB在特来电的探索
一、 为什么研究TiDB
特来电大数据平台通过开源与自研相结合的方式,目前已经上线多套集群满足不同的业务需求.目前在大数据存储和计算方面主要使用了Hbase、Elasticsearch、Druid、Spark、Flink.大数据技术可谓是百花齐放,百花齐放 百家争鸣,不同的技术都有针对性的场景.结合实际情况,选择合适的技术不是一件容易的事情.
随着接入大数据平台的核心业务的增加,伴我们在OLAP上主要遇到以下痛点问题.
- 随着基于大数据分析计算的深入应用,使用sql进行分析的需求越来越旺盛,但目前已经上线的大数据集群对sql的支持度都比较弱
- 目前进入大数据集群的数据主要以宽表方式进行,导致在数据归集和后期基础数据放生变化时 应用成本较高
- 数据仓库业务有些还是基于复杂的T+1模式的ETL过程,延时较高,不能实时的反应业务变化
- 由于每个大数据集群主要针对特定的场景,数据重复存储的情况较多,这就造成了存储成本的增加,同时也会导致数据的不一致性
- 目前进入HDFSDruidES的数据,在历史数据更新时,成本较高.灵活性降低
大数据技术发展迅速,我们也一直希望采用新的技术可以解决我们以上问题,我们关注到目前NewSql技术已经有落地产品,并且不少企业在使用。决定在我们平台内部尝试引入NewSql技术解决我们的痛点问题.我们先了解一下NewSql.

图1
如图1所示,数据库的发展经历了RDBMS、NoSql 以及现在的NewSql.每种不同的技术都有对应的产品.每种数据库的技术背后,都有典型的理论支撑.2003 年Google GFS 开创了分布式文件系统、2006年的BigTable 论文催生了Hadoop 生态,在2012年的Spanner和2013年的F1论文发表后,被业界认为指明了未来关系型数据库的发展.
随着大数据技术的发展,实际上Sql和NoSql 的界限逐渐模糊,比如现在hbase 之上有phoenix,HiveSql,SparkSql等。也有一些观点认为NewSql=Sql+NoSql. 不同的技术都有各自的最佳适应场景.Spanner和F1 被认为是第一个NewSql 在生产环境提供服务的分布式系统技术,基于该理念的开源产品主要为CockroachDB、TiDB.结合社区活跃度以及相关案例、技术支持。我们决定NewSql 技术上引入TiDB.
二、 TiDB介绍
a) 简介
TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式 HTAP 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。
b) 整体架构
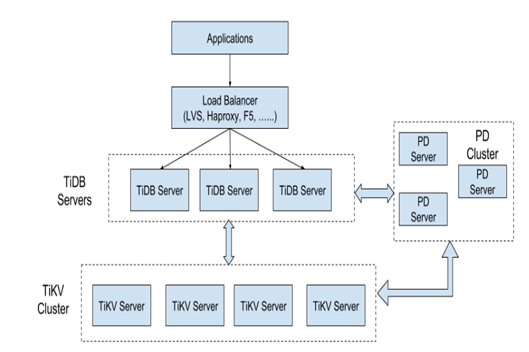
- TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
- PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
- TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
² 核心特性
p 高度兼容 MySQL --无需修改代码即可从 MySQL 轻松迁移至 TiDB
p 水平弹性扩展 --轻松应对高并发、海量数据场景
p 分布式事务 -- TiDB 100% 支持标准的 ACID 事务
p 高可用 --基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证
p 一站式 HTAP 解决方案 --一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
其中涉及到的分布式存储和分布式计算,大家可以参考TIDB的官方网站.在这里就不再进行论述.
c) TiSpark
在处理大型复杂的计算时,PingCAP 结合上图说的Tikv 以及目前大数据生态的Spark,提供了另外一个开源产品TiSpark.不得不说这是一个巧妙的设计,充分利用了现在企业已有的Spark 集群的资源,不需要另外在新建集群.TiSpark 架构以及核心原理简单描述如下
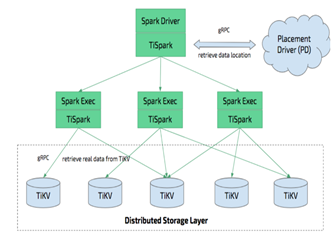
图2
- TiSpark 深度整合了 Spark Catalyst 引擎, 可以对计算提供精确的控制,使 Spark 能够高效的读取 TiKV 中的数据,提供索引支持以实现高速的点查。
- 通过多种计算下推减少 Spark SQL 需要处理的数据大小,以加速查询;利用 TiDB 的内建的统计信息选择更优的查询计划。
- 从数据集群的角度看,TiSpark + TiDB 可以让用户无需进行脆弱和难以维护的 ETL,直接在同一个平台进行事务和分析两种工作,简化了系统架构和运维。
- 除此之外,用户借助 TiSpark 项目可以在 TiDB 上使用 Spark 生态圈提供的多种工具进行数据处理。例如使用 TiSpark 进行数据分析和 ETL;使用 TiKV 作为机器学习的数据源;借助调度系统产生定时报表等等。
三、 目前的应用情况
由于很多用户已经部署了生产系统,我们没有在测试上再次投入比较大的精力,经过了简单的性能测试以后,搭建了我们的第一个TIDB集群,尝试在我们的业务上进行使用.目前主要用于我们的离线计算,以及部分即系查询场景,后续根据使用情况,主键调整我们的集群规模以及增加我们的线上应用.
l 目前的集群配置
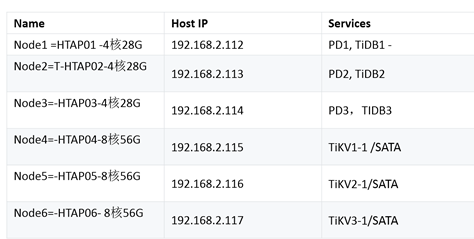
图3
l 规划的应用架构

基于TiDB 我们规划了完整的数据流处理逻辑,从数据接入到数据展现,由于TIDB 高度兼容MySql,因此在数据源接入和UI展现就有很多成熟的工具可以使用,比如Flume、Grafana、Saiku 等.
l 应用简介
² 充电功率的分时统计
每个用户使用特来电的充电桩进行充电时,车辆的BMS数据、充电桩数据、环境温度等数据是实时的保存到大数据库中。我们基于保存的用户充电数据,需要按照一定的时间展示全国的充电功率 比如展示过去一天,全国的充电功率变化曲线,每隔15分钟或者30分钟进行一次汇总。随着我们业务规模的增加,此场景的计算也逐步进行了更新换代.
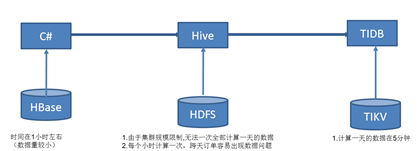
目前我们单表数据量接近20亿,每天的增量接近800万左右.使用tidb后,在进行离线计算分析时,我们的业务逻辑转成了直接在我们的离线计算平台通过sql的方式进行定义和维护,极大的提高了维护效率,同时计算速度也得到了大幅提升.
² 充电过程分析
上面我们讲了,我们已经有了充电过程中的宝贵的海量数据,如何让数据发挥价值,我们基于充电数据进行充电过程的分析就是其中的一个方式,比如分析不同的车型在不同的环境(自然、电池等)下,充电的最大电压和电流的变化情况,以及我们充电桩的需求功率满足率等.
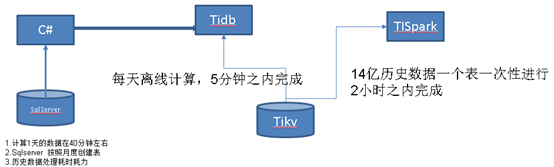
针对海量的历史数据计算我们使用了TiSpark进行计算,直接使用了我们现有的spark集群,在使用spark进行计算时,由于分配的资源比较少,时间多一些,后来和tidb技术人员交流了解到,提升配置和调整部分参数后,性能还会提升不少。这个场景中我们充分利用了tidb和tispark 进行协同工作,满足了我们的业务需求。
四、 总结及问题
² 最佳应用场景
结合我们的线上验证,我们认为使用tidb,主要有以下几个优势
p Sql支持度相对于现有的集群支持度较好,灵活性和功能性大大增强
p 可以进行表之间的join运算,降低了构造宽边的复杂度以及因此带来的维护成本
p 历史数据方便修改
p 高度兼容Mysql 生态下对应的成熟软件较多(开发工具、展现、数据接入)
p 基于索引的sql性能在离线计算上基本可以满足我们需求,在即系查询上最适合海量数据下进行多维度的精确查询,类似与“万里挑一”的场景.
p 使用TiSpark 进行复杂的离线计算,充分利用了现有的集群,数据存储做到了一份,同时也降低了运维成本
² 目前的定位
结合我们的实际现状,现阶段我们主要用于进行离线计算和部分即系查询的场景,后期随着应用的深入,我们逐步考虑增加更多的应用以及部分oltp场景.
² 发现的问题
在进行线上验证的时候,我们也发现了目前几个问题
p TiDB在高并发下海量数据的聚合查询时,性能需要提升
p 由于TiDB 目前还没有充分利用查询缓存,同一个连续多次执行时,执行效率没有变化
p 目前发现部分即系查询场景在数据量增加时,性能有所下降,联合TiDB技术人员诊断后(作为开源产品,TIDB的技术支持很给力),确定是由于目前没有采用SSD硬盘导致,考虑到目前的应用还比较少,后续应用丰富后,考虑SSD