java IO 操作的类在java.io 包中,大概可以分为以下几组:
- 基于字节操作的接口:InputStream 和 OutputStream
- 基于字符操作的接口:Writer 和 Reader
- 基于磁盘操作的接口:File 相关
- 基于网络操作的接口:Socket 相关
前两个是数据格式区分,后两个是传输方式区分。IO 只是人机交互的手段,除了完成交互功能,我们关注的就是如何提高他的运行效率了,而数据格式和传输方式是影响效率的最关键的因素。
基于字节操作的接口
以下是 InputStream 的类层次关系图
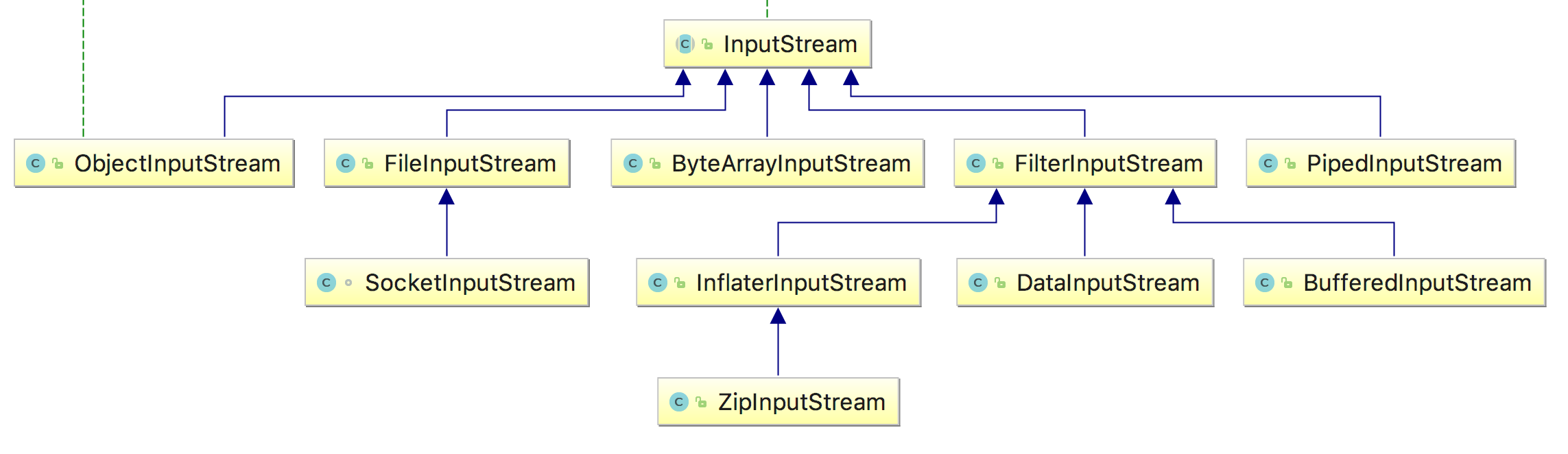
其实还有很多子类没有展示出来,每个子类对应处理不同的操作类型。
以下是 OutputStream 的类层次关系图

两个要点:
- 1、操作数据的方式可以组合使用
- 2、必须制定流最终写到什么地方:要么是磁盘,要么是网络中。其实写网络也是写磁盘,只是需要让操作系统再将数据传送到其他地方,而不是本地磁盘。
基于字符操作的接口
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符,所以IO操作的都是字节而不是字符,但是为什么有操作字符的IO接口呢?
这是因为我们程序操作的数据都是字符形式的,为了方便操作当然要提供直接写字符的IO接口。
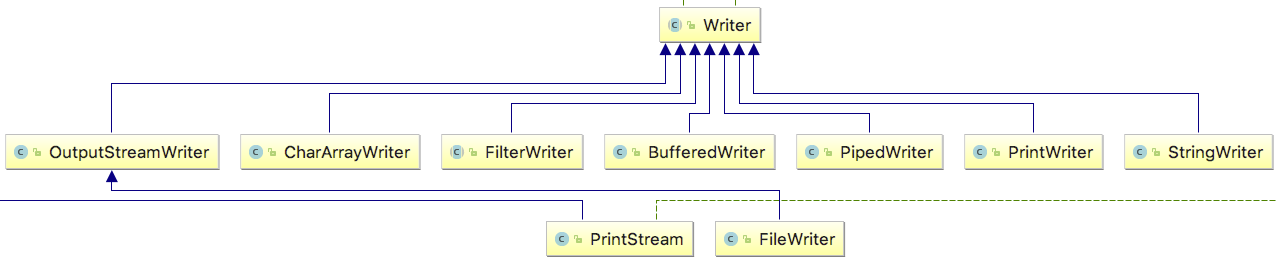
Writer 类层次结构
Reader 类层次结构
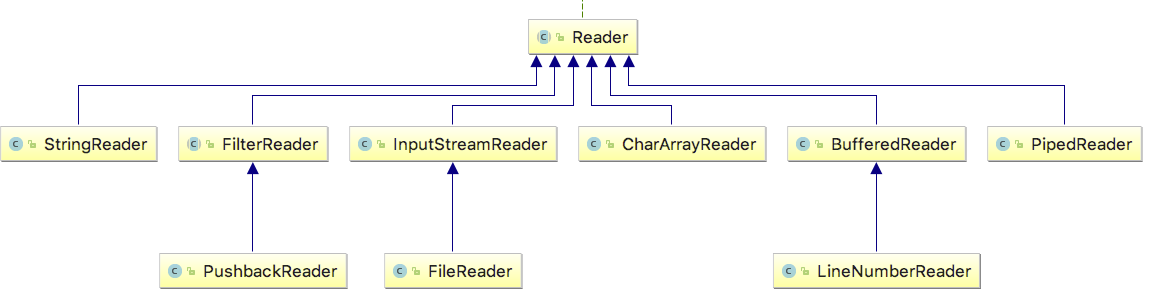
Reader 和 Writer 接口都只定义了读取或写入数据字符的方式,也就是怎么读或写,但是没有指明数据要写到哪里,这里就涉及到磁盘或网络的工作机制。
字节和字符转化接口
前面说过,数据持久化或网络传输都是以字节为单位进行,所以必须有字符字节转化工具。
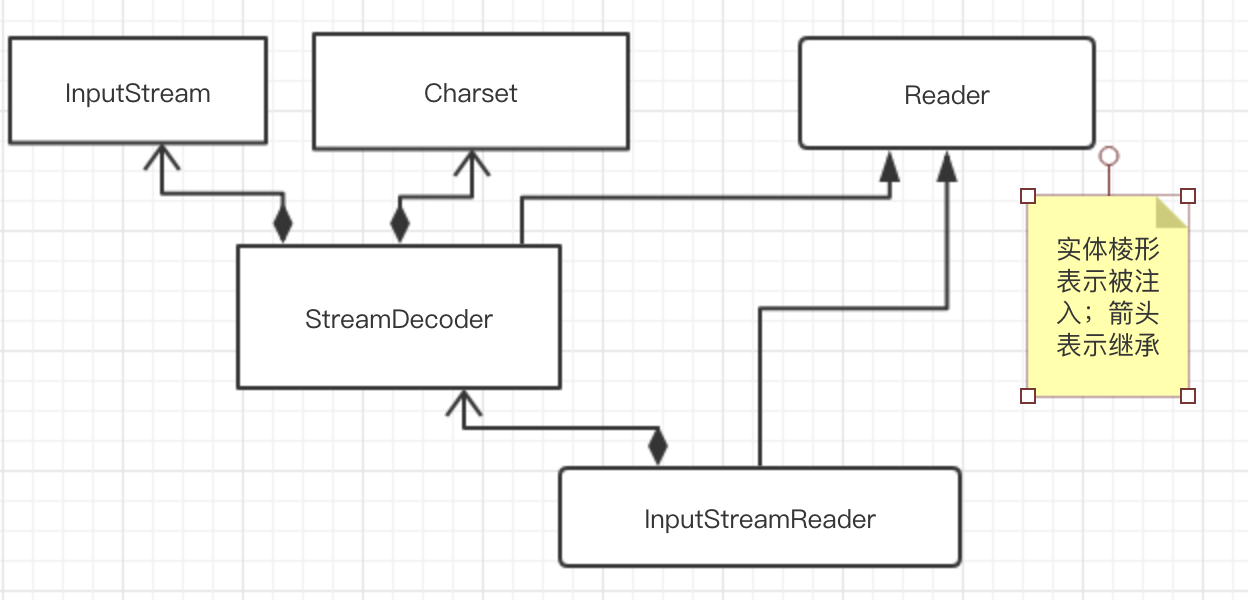
字符编码类结构如图,解码有类似的结构;
从InputStream 到 Reader 的过程要指定编码字符集,否则使用系统默认的字符集,很可能会出现乱码问题。StreamDecoder 正是完成从字节到字符的解码的实现类。
try {
StringBuffer buffer = new StringBuffer();
char[] buf = new char[1024];
FileReader reader = new FileReader("file");
while (reader.read(buf) > 0) {
buffer.append(buf);
}
buffer.toString();
} catch (Exception e) {
}
FileReader 就是按照上面的工作方式读取文件的,FileReader 继承了 InputStreamReader ,实际上是读取文件流,然后通过StreamDecoder 解码成 char,只不过这里的解码字符集是默认字符集。
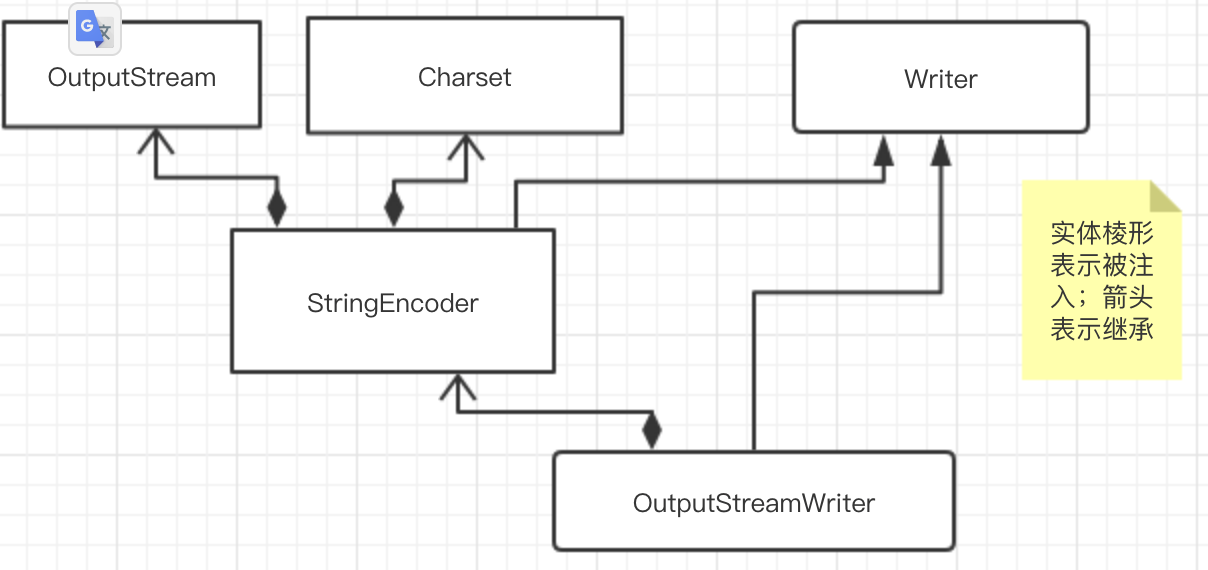
通过 OutputStreamWriter 类完成了从字符到字节的编码过程,由 StreamEncoder 完成编码过程。