如今,缓存系统的应用非常广泛,能够用来提高并发数、数据吞吐量,提高快速响应能力。那么当数据量达到一定程度,单机环境可能就显得有些力不从心了,就需要一个分布式缓存系统。
1. 缓存系统的选择
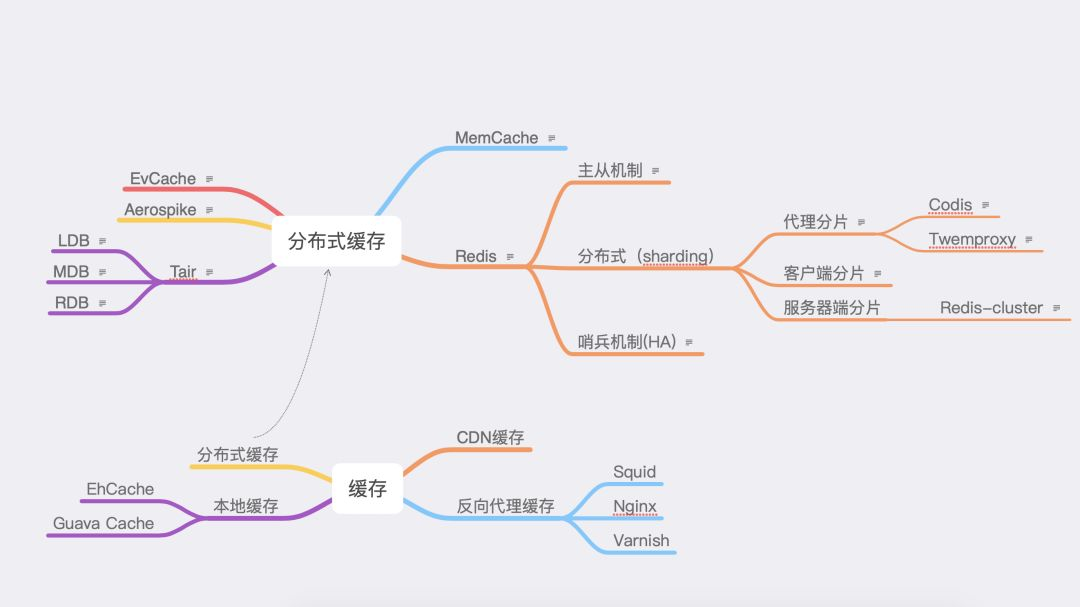
1.1 缓存分类
如上图所示,首先缓存大致可以分为四大类。
- CDN 缓存:CDN 即内容分发网络,CDN 边缘节点将数据缓存起来。
- 反向代理缓存:如 Nginx 的缓存。
- 本地缓存:代表的有 EhCache 和 Guava Cache。
- 分布式缓存:各缓存系统。
1.2 分布式缓存
本文主要探讨各分布式缓存系统,如图 1-1 所示,列出了五种:
其中 EvCache 和 Aerospike 使用场景不是那么通用和广泛。
- EvCache:是 Netflix 的基于 Memcached & Spymemcached 的缓存方案。
- Aerospike:是可基于 SSD 的 KV NoSQL 数据库。
除此之外,还有三种常见缓存系统。
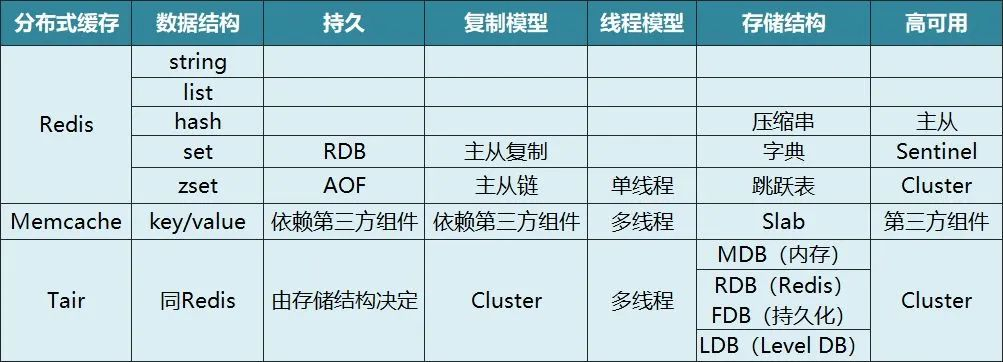
-
Tair:阿里开源,跨机房、性能随结点添加线性上升、适用大数据量。Tair 还有三种引擎。
-
- LDB: 基于 google levelDB,支持 KV和类 HashMap 结构,性能稍低,持久化可靠性最高。
- MDB: 基于 Memcache,支持 KV 和类 HashMap,性能最优,不支持持久化存储。
- RDB: 基于 Redis。
-
Memcache: 不支持数据同步、分布式支持较差。
-
Redis: 社区活跃、使用最多。
综上所述,在一般情况下,考虑到适用性和稳定性,Redis 是搭建缓存系统的最优选择。以下将基于 Redis 介绍。
2. Redis 集群缓存方案
如顶部图 1-1 所示,列出了 Redis 的集群高可用的方案,基本可以分为三种。
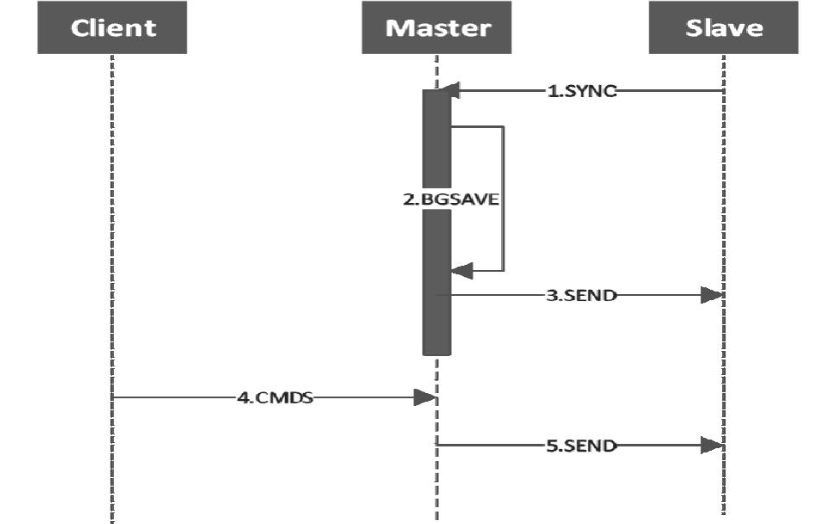
2.1 主从机制
常见的集群架构,搭建简单,主要实现读写分离和备份,可以由 Master 负责读写,Slave 负责备份。但存在故障恢复复杂、水平拓展难、写能力受限等问题。结构图如下:
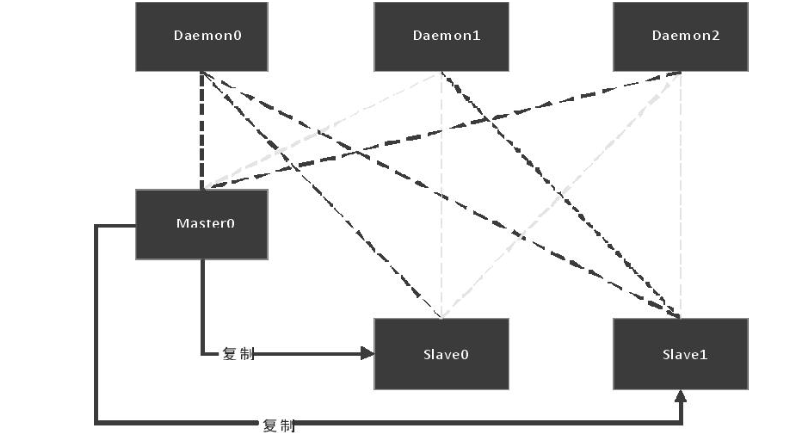
2.2 哨兵机制
Redis Sentinel 是社区版本推出的原生高可用解决方案。由一或多个哨兵实例监视任意个主从服务器,且在 Master 宕机时,自动将宕机服务器属下的 Slave 服务器升级为 主服务器,从而保证系统的可用性。较主从实现的监控、选主。但问题主要是要保证 Master 的 HA 切换。结构图如下:
2.3 "分布式"
到这里以上两种机制其实只能算作“集群”,并非严格意义上的“分布式”。接着来看看分布式方案。
集群强调高可用,分布式在集群的基础上又强调协作。
3. Redis分布式缓存方案
任何分布式存储系统,首先面临的就是 sharding(分片)问题,如顶部图 1-1 所示该问题有为三种解决方法。
3.1 客户端分片
顾名思义,将数据分片的路由功能交给客户端,但这是一种静态分片,维护性差。基本是不予考虑的。
3.2 代理分片
通过代理分发到具体的 redis 实例。有两个常用解决方案。
- Twemproxy:Twitter 开源,轻量级,不再维护,无法平滑地扩容/缩容,运维也不是很友好,性能一般。
- Codis:豌豆荚开源,支持水平拓展,运维平台完善,性能较 Twemproxy 快。Codis 在国内使用的较多,同时代理分片的思路也有很多公司在此基础开发了自己的二次方案。不过 Codis 也不再维护。
其实,这两种代理分片的方案,都是在 Redis 官方未推出良好的分布式方案时的产生的,在官方更新提供更优策略后都不再维护。
3.3 服务器端分片
这就要谈到 Redis 官方方案 Redis-cluster 。
在 Redis 3.0 之前是没有较好的分布式方案的,这也是第三方方案出现的原因。3.0 开始,官方推出了去中心化的分布式方案。集群中包含 16384 个散列槽,每个节点负责其中一部分。
先看下拓扑图:
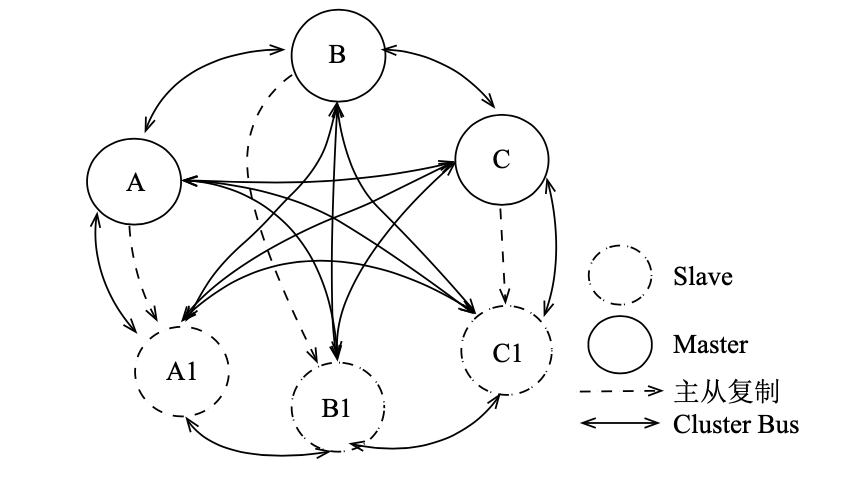
每个节点打开两个 TCP 连接,一个负责给客户端提供服务,一个负责节点间通信。
此刻要说说 CAP 了 :Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性) 。对分布式系统而言,CAP 必须牺牲一者。Redis Cluster 的设计目标主要是高性能、高可用和高扩展,只好抛弃一部分数据一致性。
-
数据一致性:由于Redis Cluster 使用异步复制, 在某些情况下如 Master 宕机但未同步至 Slave,可能会导致丢失写入。在绝对需要支持同步写入时,可通过 WAIT 命令实现,可使得丢失写入的可能性大大降低。
-
可用性:当集群中一部分节点故障后,集群整体能响应客户端读写请求。
-
- 节点间定时互 ping ,当超过一半 Master 判定某节点失败,则标记为 FAIL,且会向集群广播节点下线的消息。如下线节点是带有槽的主节点,则要从它的从节点选出一个替换。
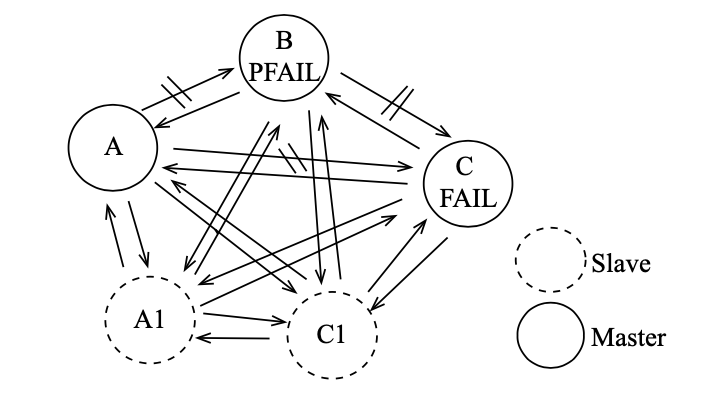
-
高性能和拓展:操作某个 key 时,不会先找到节点再处理,而是直接直接重定向到该节点,同时相较代理分片也少了 proxy 的连接损耗。
-
- 但是在进行 multiple key 操作时需要 keys 位于同一个 slot 上,需要使用 hash tags,使用 {} 强制将某些 key 映射到每个 slot,以便进行 multiple 。
- 在拓展方面,Redis Cluster 最大支持线性拓展 1000 个节点,将新节点加入集群后可以通过命令指定和平均的从已有节点分配 slot。
4. 缓存常见问题
以上介绍了简单介绍了常见缓存系统,并具体列出了基于 Redis 的集群方案。下面谈一谈缓存系统常见的问题。
如下图所示,列出七个常见问题。
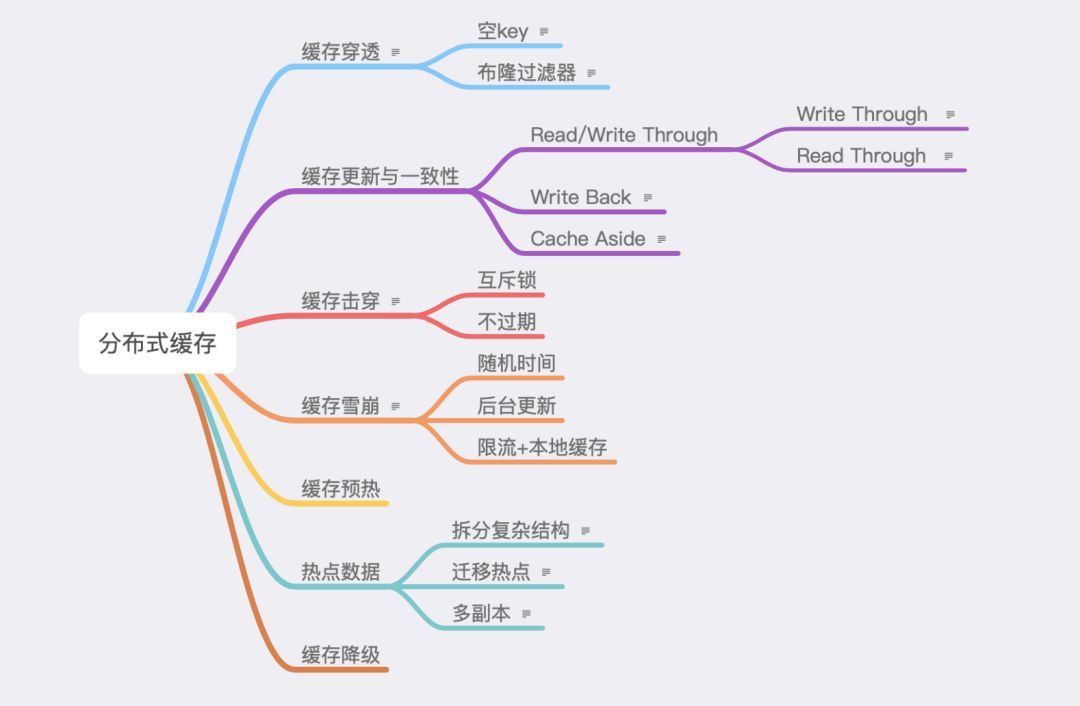
4.1. 缓存穿透
指访问不存在的数据,从而绕过缓存,直接请求到了数据源,当请求过多,就会对 DB 造成压力。
- 空 key:指对于不存在的数据也将 key 存空值入缓存系统,这样下次访问也会得到返回。但只适用于空数据 key 有限、key 重复请求概率高,如果量大且不重复,就会造成很多无用 key 的创建。
- 布隆过滤器:布隆过滤器是一个很长的二进制向量和一系列随机映射函数。可用于检索一个元素是否在一个集合中加一层对空值的过滤器,空间和时间效率都很高。但由于 hash 产生的碰撞可能存在误判,以及因不存储 key 导致的无法删除。适用于空数据 key 各不同、重复请求概率低。
4.2. 缓存击穿
缓存击穿实际是缓存雪崩的一个特例。指当某些热点 key 过期时,就会有大量的请求击穿到 DB。
-
互斥锁:在缓存失效的时候,不立即 load db,可以先用如 SETNX 等命令去 set 一个 mutex key,当操作返回成功时,说明拿到锁,此刻该线程进行 load db 的操作并更新缓存;否则未拿到锁就(可休眠一段)重试 get 缓存的方法。但要注意死锁风险。
-
不过期
-
- 这里的不过期有两个概念,一个指未设过期时间,那是真的不过期,那没事了。
- 另一个是指通过业务逻辑,将 key 的过期时间进行存储,请求是判断是否小于值,是则后台异步更新。
4.3. 缓存雪崩
同一时刻大量缓存失效(故障), 请求到了 DB。
- 随机时间:在设置过期时间时,可以在基础时间上 + 一个随机的时间,等于实现了分批过期。
- 后台更新:将更新失效的工作交给后台定时线程。
- 限流 + 本地缓存:如 ehcache 本地缓存 + Hystrix 限流。
- 双缓存:类似于设置主从缓存,从 key 不过期。
4.4. 缓存更新与一致性
如果保证数据一致性。列出四种更新策略:
-
Cache Aside :最常用的。失效时回源取数据,更新;命中时,返回缓存数据;更新时先数据源更新,再更新缓存。
-
Write Back :更新数据时,只更新缓存,不更新数据源。缓存异步批量更新数据库。
-
Read/Write Through
-
- Write Through :当有数据更新时,如未命中缓存,直接更新数据库,并返回。如命中缓存,则更新缓存,再由 Cache 自己更新数据库。
- Read Through :更新数据源由缓存系统操作,读取数据时如缓存失效,则取回源数据更新缓存。
4.5. 热点数据
对于热点数据的处理方法。
- 拆分复杂结构:如二级数据结构,进行拆分,这样热点 key 就被拆为若干个的 key 分布到不同节点。
- 迁移热点:对于 Redis Cluster 而言可以将热点 key 所在的 slot 单独迁移到一个节点,降低其他节点压力。
- 多副本:复制多份缓存副本,将请求分散到多个节点上,减轻单台缓存服务器压力,适合多读少写。
4.6. 缓存预热
指可以将某些的缓存数据提前加载到缓存系统,提前避免在如热点数据大量请求到库。
4.7. 缓存降级
指当访问量剧增、服务出现问题或非核心服务影响到核心流程的性能时,仍需保证主服务可用。可根据一些关键数据自动降级,也可配置开关人工降级。
5. Redis Cluster 使用
对于 Redis Cluster 环境的搭建和基础使用非常简单。
无论基于何种方式,只要搭建好 n 台 redis 服务并保证各服务间可以互相通讯后,任意进入一个 redis 服务键入:
redis-cli --cluster create IP1:port1 IP2:port2 IP3:port3 IP4:port4 IP5:port5 IP6:port6 ... --cluster-replicas 1
即可。之后可以使用 cluster node 和 cluster info 命令查看集群、节点信息。
而对于广大 JAVA 开发,Spring Data Redis 从 1.7 起即支持 Redis Cluster,只需配置 Master 节点地址(和密码)。
spring.redis.cluster.nodes=ip1:port1,ip2:port2,ip3:port3
加入依赖
compile("org.springframework.boot:spring-boot-starter-data-redis")
即可通过 RedisTemplate 使用。
6. 总结
本文从缓存系统的选择出发,基于 Redis 介绍了几种集群方案并重点说明了 Redis Cluster 方案。之后列出缓存系统常见问题及常见解决方案,最后对使用做了简单说明。
当然,如何去落地,如何解决这些问题还需要根据实际场景具体分析和处理。
参考资料
- Redis Cluster Specification:https://redis.io/topics/cluster-spec
- 深入理解分布式系统中的缓存架构:https://juejin.im/entry/5b514768f265da0fa21a800f
- 缓存更新的套路:https://coolshell.cn/articles/17416.html
- 一种高效的Redis Cluster的分布式缓存系统[J].计算机系统应用,2018,27(10):91-98 :https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CJFQ&dbname=CJFDLAST2018&filename=XTYY201810014
原文链接:https://mp.weixin.qq.com/s/cONKlGQze1WzyC2yzbZ0RA
欢迎关注公众号 【码农开花】一起学习成长
我会一直分享Java干货,也会分享免费的学习资料课程和面试宝典
回复:【计算机】【设计模式】【面试】有惊喜哦