转载自:http://ganeshtiwaridotcomdotnp.blogspot.com/2010/12/text-prompted-remote-speaker.html
Biometrics is, in the simplest definition, something you are. It is a physical characteristic unique to each individual such as fingerprint, retina, iris, speech. Biometrics has a very useful application in security; it can be used to authenticate a person’s identity and control access to a restricted area, based on the premise that the set of these physical characteristics can be used to uniquely identify individuals.
Speech signal conveys two important types of information, the primarily the speech content and on the secondary level, the speaker identity. Speech recognizers aim to extract the lexical information from the speech signal independently of the speaker by reducing the inter-speaker variability. On the other hand, speaker recognition is concerned with extracting the identity of the person speaking the utterance. So both speech recognition and speaker recognition system is possible from same voice input.
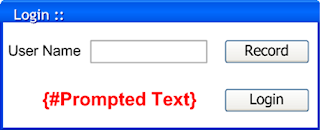
Desired Output of the Combined System
Text Prompted Remote Speaker Authentication is a voice biometric system that authenticates a user before permitting the user to log into a system on the basis of the user’s input voice. It is a web application. Voice signal acquisition and feature extraction is done on the client. Training and Authentication task based on the voice feature obtained from client side is done on Server. The authentication task is based on text-prompted version of speaker recognition, which incorporates both speaker recognition and speech recognition. This joint implementation of speech and speaker recognition includes text-independent speaker recognition and speaker-independent speech recognition. Speaker Recognition verifies whether the speaker is claimed one or not while Speech Recognition verifies whether or not spoken word matches the prompted word.
The client side is realized in Adobe Flex whereas the server side is realized in Java. The communication between these two cross-platforms is made possible with the help of Blaze DS’s RPC remote object.

System Architecture
Mel Filter Cepstral Coefficient (MFCC) is used as feature for both speech and speaker recognition task. We also combined energy features and delta and delta-delta features of energy and MFCC. The feature extraction module is same for both speech and speaker recognition. And these recognition systems are implemented independent of each other.
For speaker recognition, GMM(Gaussian Mixture Model) parameters for registered users and a universal background model (UBM) were trained using Expectation Maximization algorithm. Log likelihood ratio between claimed speaker and UBM were compared against threshold to verify the user.
For speech recognition, Codebook is created by k-means clustering of the all feature vector from training speech data. Vector Quantization (VQ) is used to get discrete observation sequence from input feature vector by applying distance metric to Codebook. Left to Right Discrete HMM(Hidden Markov Model) for each word is trained by Baum-Welch algorithm. Viterbi decoding is used for finding best match from the HMM models.
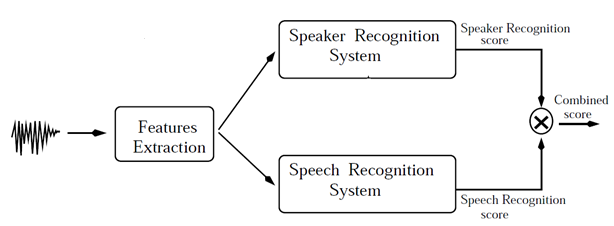
Combining speech and speaker recognition systems
Based on the speech model the system decides whether or not the uttered speech matches what was prompted to utter. Similarly, based on the speaker model, the system decides whether or not the speaker is claimed one.
Finally for verification, the score of both speaker and speech recognition is combined to get combined score, to accept or reject the user’s claim.