上一个章节,简要说了以下分片下载的几个特性。今天主要用示例说明一下pdf.js分片下载。
服务器环境:
php7.2
nginx 1.14
ubuntu 18.04
测试浏览器:谷歌浏览器 70.0.3538.110(
第一个场景,直接使用pdf 文件
1.1 代码如下:注意路径使用的是pdf 文件的物理路径
$filePath = ‘…/doc/big.pdf’;
这里是举例,这样作有一个明显的缺点,就是容易被盗链
getDocument 方法中的 rangeChunkSize 参数,就是设置分块大小,默认是64k,可以修改这个数字,来改变
这个例子使用的 1664k ,1m 左右来分片,方便测试。您可以根据具体情况,来调整
PDFJS.getDocument({url:url,rangeChunkSize:6553616,disableAutoFetch:0}).
<html>
<head><title>pdf.js展示1,上一页,下一页</title></head>
<h1>PDF.js Previous/Next example</h1>
<div>
<button id="prev">Previous</button>
<button id="next">Next</button> <span>Page: <span id="page_num"></span> / <span
id="page_count"></span></span></div>
<canvas id="the-canvas"></canvas>
<script src="../js/pdfjs/pdf.js"></script>
<script src="../js/pdfjs/pdf.worker.js"></script>
<script>
var url = '../doc/big.pdf';
var pdfDoc = null,
pageNum = 1,
pageRendering = false,
pageNumPending = null,
scale = 0.8,
canvas = document.getElementById('the-canvas'),
ctx = canvas.getContext('2d');
/**
* Get page info from document, resize canvas accordingly, and render page.
* @param num Page number.
*/
function renderPage(num) {
pageRendering = true;
// Using promise to fetch the page
pdfDoc.getPage(num).then(function (page) {
var viewport = page.getViewport(scale);
canvas.height = viewport.height;
canvas.width = viewport.width;
// Render PDF page into canvas context
var renderContext = {
canvasContext: ctx,
viewport: viewport
};
var renderTask = page.render(renderContext);
// Wait for rendering to finish
renderTask.promise.then(function () {
pageRendering = false;
if (pageNumPending !== null) {
// New page rendering is pending
renderPage(pageNumPending);
pageNumPending = null;
}
});
});
// Update page counters
document.getElementById('page_num').textContent = num;
}
/**
* If another page rendering in progress, waits until the rendering is
* finised. Otherwise, executes rendering immediately.
*/
function queueRenderPage(num) {
if (pageRendering) {
pageNumPending = num;
} else {
renderPage(num);
}
}
/**
* Displays previous page.
*/
function onPrevPage() {
if (pageNum <= 1) {
return;
}
pageNum--;
queueRenderPage(pageNum);
}
document.getElementById('prev').addEventListener('click', onPrevPage);
/**
* Displays next page.
*/
function onNextPage() {
if (pageNum >= pdfDoc.numPages) {
return;
}
pageNum++;
queueRenderPage(pageNum);
}
document.getElementById('next').addEventListener('click', onNextPage);
/**
* Asynchronously downloads PDF.
*/
PDFJS.getDocument({url:url,rangeChunkSize:65536*16,disableAutoFetch:0}).then(function(pdfDoc_) {
pdfDoc = pdfDoc_;
document.getElementById('page_count').textContent = pdfDoc.numPages;
// Initial/first page rendering
renderPage(pageNum);
});
</script>
</html>
1.2今天第一加载:发现没有出现分片效果。如果您也遇到这种情况,不要着急,很大程度是因为浏览器缓存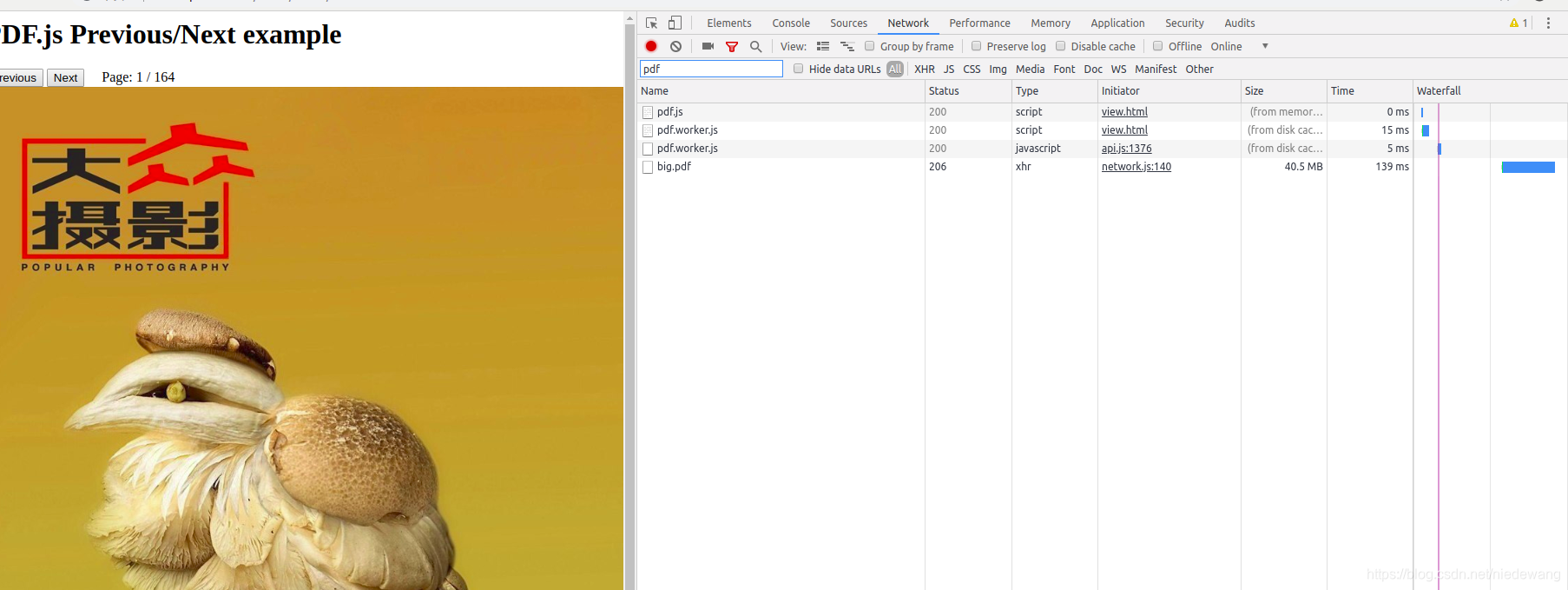
1.3 在浏览器中,安Ctrl+alt+delte 键,清除缓存
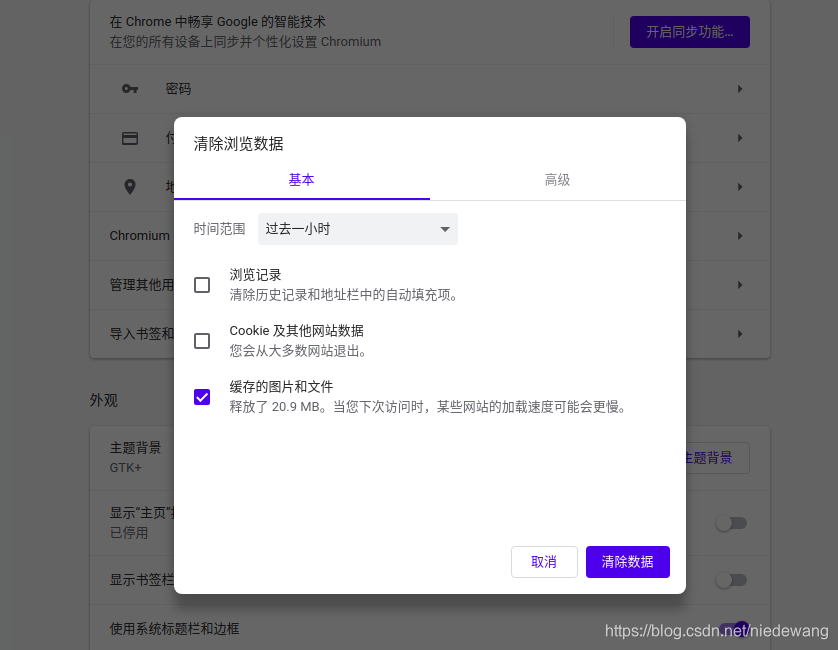
1.4 清除缓存后,再次刷新页面,发现分片下载功能出现了。
后台代码
<?php
$filePath = '../doc/big.pdf';
//普通的方式处理包装pdf文件
download_file($filePath);
function download_file($file, $fname = 'chunk.pdf')
{
header("Content-Type: application/octet-stream");
header("Content-Disposition: attachment;filename=$fname");
echo(file_get_contents($file));
}
前台js 调用代码
。。。。。
var url = 'download.php';
var pdfDoc = null,
pageNum = 1,
pageRendering = false,
pageNumPending = null,
scale = 0.8,
canvas = document.getElementById('the-canvas'),
ctx = canvas.getContext('2d');
。。。。
2.2 经过清理缓存,发现无法达到分片的效果。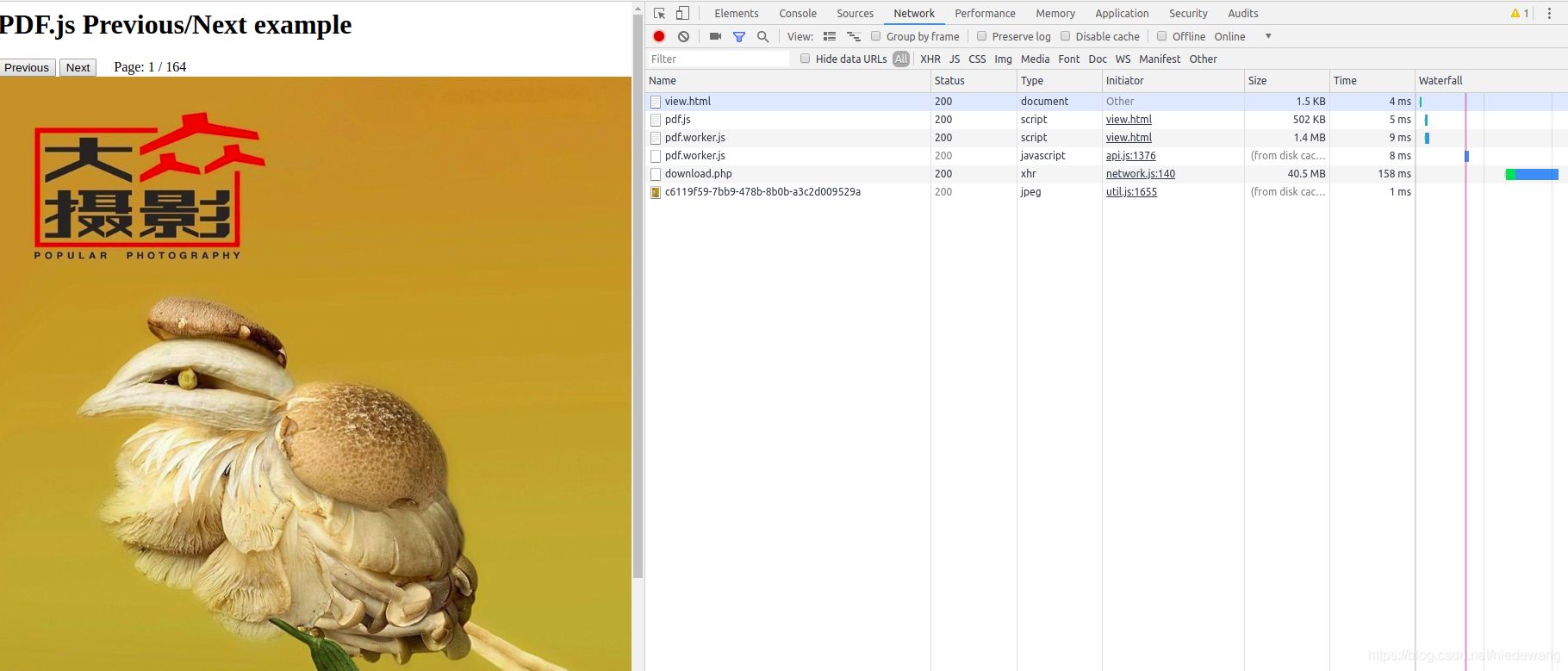
初步总结如下,常规的附件处理方式,会影响分片下载的效果
场景3:使用php 结合httprange,实现分片的效果
3.1 这里是从网上搜集到的分片下载php 函数
代码的核心是,增加head 头,开启分片 Header("Accept-Ranges: bytes"); 至于 Http range 如何计算,就比较繁琐了,这里就不详细介绍了。有兴趣的可以去百度
<?php
$filePath = '../doc/big.pdf';
//分片下载
chunk_download_file($filePath);
/**
* 分篇下载的汉书
*
* @param $file
* @param $fname
*/
function chunk_download_file($file, $fname = 'chunk.pdf')
{
$fhandle = fopen($file, 'rb');//文件句柄
$fsize = filesize($file);//文件大小
//断点续传和整个文件下载的判断,支持多段下载
if (!empty($_SERVER['HTTP_RANGE'])) {
$range = str_replace("=", "-", $_SERVER['HTTP_RANGE']);
$match = explode("-", $range);
$start = $match[1];
$end = !empty($match[2]) ? $match[2] : $fsize - 1;
} else {
$start = 0;
$end = $fsize - 1;
}
if (($end - $start) < ($fsize - 1)) {
fseek($fhandle, $start);
header("HTTP/1.1 206 Partial Content");
header("Content-Length: " . ($end - $start + 1));
header("Content-Range: bytes " . $start . "-" . $end . "/" . $fsize);
} else {
header("HTTP/1.1 200 OK");
header("Content-Length: $fsize");
Header("Accept-Ranges: bytes");
header("Content-Range: bytes " . $start . "-" . $end . "/" . $fsize);
}
header("Content-Type: application/octet-stream");
header("Content-Disposition: attachment;filename=$fname");
if (!feof($fhandle)) {
set_time_limit(0);
$buffer = fread($fhandle, $end - $start + 1);
echo $buffer;
flush();
ob_flush();
}
}
demo 下载路径:
https://download.csdn.net/download/niedewang/10804164
3.2 清理调浏览器缓存,发现这种方式可以达到分片下载的效果
经过测试,谷歌浏览器支持的很好,如上图所示,截图就是使用的谷歌浏览器。
但是firefox 在这种场景下,分片效果不理想。具体原因未知
简要的总结
1:前期承诺的demo 放出来了,blog貌似会清理连接地址,不知道是否会删除
2:使用pdf 真实文件路径,分片兼容性最好。但是地址容易泄漏
3:如果使用php 处理,一般的处理程序,不能达到分片效果。需要结合http range特性,但是不知道什么原因,firefox测试下来,效果不好。谷歌浏览器支持的较好,好消息是谷歌浏览器现在占用量是最大的。
4:后面有时间了,会介绍以下使用 x-sendfile 的方式处理附件,无论性能还是兼容性都比php 处理要好
---------------------
作者:只看远方
来源:CSDN
原文:https://blog.csdn.net/niedewang/article/details/84576969
版权声明:本文为博主原创文章,转载请附上博文链接!