简称SD,顾名思义,在采集的语音信号流中,分辨出不同说话人的说话时长并标注,即以时间为索引,检测出每段语音所对应的说话人身份,其通常由说话人分割和聚类两步组成。
参照2010年8月的文献[1]中的一张图:

又称说话人分割等,在语音信号处理的多种场景下均有应用需求,近年来也被多来越多的研究者所关注。SD的方法分为以下两种:1)无监督方法,比如谱聚类以及k均值等;2)监督方法,深度神经网络,比如RNN等方法。
原理
Diarisation是一个生造的词,可以翻译为“分割和聚类”,在一些场景中,如一段电话对话、一场会议、一段广播语音或者是一个电视节目等等日常生活中的语音场景,对语音信息进行切分,找到每个人说的语音,即对整个语音信息的分割和聚类。
Speaker diarisation is the task to find “who spoke when”, while speech recognition is to find “what was spoken”. 这个在语音识别系统中,是作为一个对对话、会议和电视节目识别前的进行预处理的部分,同时在带有语音信息的视频理解等任务中,也是一个很重要的组成部分。
Speaker diarization consists of segmenting and clustering a speech recording into speaker-homogenous regions, using an unsupervised algorithm. In other words, given an audio track of a meeting, a speaker-diarization system will automatically discriminate between and label the different speakers (“Who spoke when?”). This involves speech/non-speech detection (“When is there speech?”) and overlap detection and resolution (“Who is overlapping with whom?”), as well as speaker identification.
所以事实上,SD不能简单的被翻译为说话人分割或者说话人分类。但是为了方便以及辨识性,大部分会如此称呼。
pipeline
参考http://pyannote.github.io/pyannote-metrics/reference.html,下图为SD的典型pipeline:

参考[3],首先一段语音信息流,通过VAD模块(Voice Activity Detection, 语音活跃性检测),检测出哪些帧是有语音的,哪些帧是没有语音的(无声音或者只有背景声)。接着通过CPD模块(Change Point Detection,变更点检测)来检测出说话人的变更点。最后对分割后的每一段语音,提取特征,进行聚类(Speaker Clustering),得到每一段的语音属于哪个人说的。当然最后,会使用迭代的方法,对上述过程进行反复优化迭代,即refine过程,来获得更好的diarisation的结果。
- VAD模块(Voice Activity Detection, 语音活跃性检测),任务就是找到,什么时候有语音,也可叫“端点检测”或者”End Point Detection”。传统方法基于信号处理(Model-free),如时域处理或者频域能量分析,这些方法很不鲁棒。比较好的是基于Model-based的方法。
- CPD模块(Change Point Detection,变更点检测),任务就是寻找说话人变更点,找到这些点,对语音信息进行分割。比如可以使用滑动窗,在语音流上滑动,当提取的特征对应的分数发生一定阈值以上的变更,就认为发生了说话人身份变更现象。也可以使用神经网络,对每个点进行一个分类,分出变更点和非变更点。
- 说话人聚类(Speaker Clustering)模块,就是对CPD模块的分割输出,进行聚类,将同一个人说的话聚类到一起。常用的方法如IAC、AHC、k-means以及谱聚类等,或者基于每个人的说话特点,提取特征进行聚类等。
- 最后对上述的流程进行反复迭代,refine结果。常用的方法如iterative Variational Bayes,以及不同迭代次数中,改变滑动窗的长度,甚至也有使用语音识别结果,来迭代修正前面的流程。
challenges
1、一个端到端模型?
2、说话人数目不确定、无上限,如何聚类?
3、CPD模块是否必要,如何改进适用?
基于聚类的无监督方法
基于RNN的监督方法
UIS-RNN[2]
这是谷歌2019年发表的一篇文章,研究了实时处理的说话人分类,不限制说话人数目,基于d-vector特征,为每一个说话人建立了一个RNN模型,并且持续更新。文中表示实时说话人分割的准确率可以达到92%,并且DER降低至7.6%,超过了其先前基于聚类方法(8.8%)和深度网络嵌入方法(9.9%)。
文章主要提出了无界间隔状态(Unbounded Interleaved-State) RNN,一个可以通过监督学习训练的对于时变数据分割和聚类的算法。
首先看一张图,这是文中的SD results show:
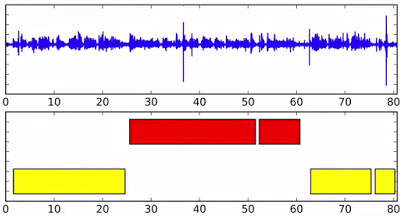
不同颜色表示不同的说话人,横轴为时间索引。
这一方法与通常聚类方法的主要区别在于研究人员使用了参数共享的循环神经网络为所有的说话人(embeddings)建模,并通过循环神经网络的不同状态来识别说话人,这就能将不同的语音片段与不同的人对应起来。
具体来看,每一个人的语音都可以看做权值共享的RNN的一个实例,由于生成的实例不受限所以可以适应多个说话人的场景。将RNN在不同输入下的状态对应到不同的说话人即可实现通过监督学习来实现语音片段的归并。通过完整的监督模型,可以得到语音中说话人的数量,并可以通过RNN携带时变的信息,这将会对在线系统的性能带来质的提升。
系统的baseline结构为:
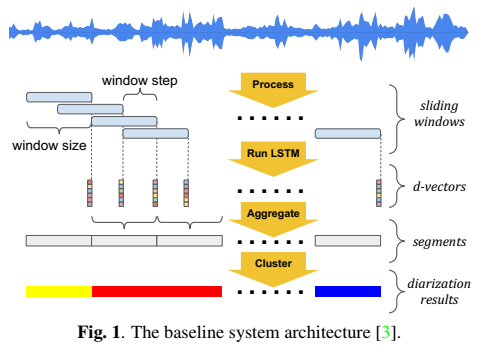
UIS-RNN是一个整句(X,Y)的在线生成处理过程,提出的算法结构为:
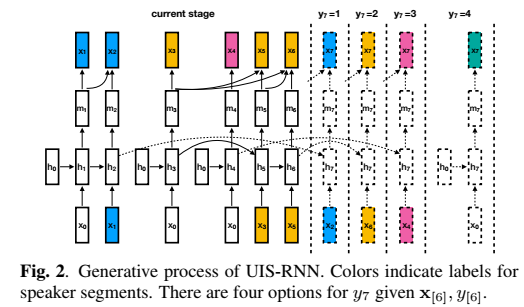
解码过程中采用最大后验概率准则解码,采用beam search方法处理。
同时,在speaker segment建模中,采用了一个贝叶斯非参数模型:distance dependent Chinese restaurant process (ddCRP)的loss,用来估计number of clusters。
为验证模型,作者们选用数据集CALLHOME(2000 NIST SRE,disk-8),5折交叉验证,模型效果采用DER评价参数衡量。此外,又使用了两个off-domain数据集:Switchboard(2000 NIST SRE,disk-6) 和 ICSI会议语料库。最终DER可以低至7.6%,分割性能超过现有的SOTA算法。
在未来研究人员将会改进这一模型用于离线解码上下文信息的整合;同时还希望直接利用声学特征代替d-vectors作为音频特征,这样就能实现完整的端到端模型了。
参考
[1] Speaker Diarization: A Review of Recent Research
[2] Fully Supervised Speaker Diarization, 2019 ICASSP accepted.
[3] https://mp.weixin.qq.com/s/VzahF0-TQ_SrIqziRLfq1A