1.Algorithm
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4) 输出:7 -> 0 -> 8 原因:342 + 465 = 807
对两数相加方法的可视化: 342 + 465 = 807342+465=807, 每个结点都包含一个数字,并且数字按位逆序存储
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode dummyHead = new ListNode(0);
ListNode p = l1, q = l2, curr = dummyHead;
int carry = 0;
while (p != null || q != null) {
int x = (p != null) ? p.val : 0;
int y = (q != null) ? q.val : 0;
int sum = carry + x + y;
carry = sum / 10;
curr.next = new ListNode(sum % 10);
curr = curr.next;
if (p != null) p = p.next;
if (q != null) q = q.next;
}
if (carry > 0) {
curr.next = new ListNode(carry);
}
return dummyHead.next;
}
2.Review
阅读 redis 技术文档 LUA 脚本
使用 lua 可以很明显的提升 redis 的效率
可以使用两个不同的Lua函数从Lua脚本调用Redis命令:
redis.call()redis.pcall()
redis.call()类似于redis.pcall(),唯一的区别是如果Redis命令调用将导致错误,redis.call()将引发Lua错误,反过来将强制EVAL向命令调用者返回错误,同时redis.pcall将陷阱错误并返回Lua表代表错误。
lua 的命令
EVAL执行Lua脚本EVALSHA执行Lua脚本的sha1SCRIPT LOAD加载Lua脚本到Redis ScriptSCRIPT FLUSH清空Redis ScriptSCRIPT EXISTS判断是否存在Rdis Script中
Lua和Redis数据类型之间的转换
Redis到Lua转换表。
- Redis整数回复 - > Lua号
- Redis批量回复 - > Lua字符串
- Redis多批量回复 - > Lua表(可能有其他Redis数据类型嵌套)
- Redis状态回复 - > Lua表,
ok其中包含一个包含状态的字段 - Redis错误回复 - >
err包含错误的单个字段的Lua表 - Redis Nil批量回复和Nil多批量回复 - > Lua false布尔类型
Lua到Redis转换表。
- Lua number - > Redis整数回复(数字转换为整数)
- Lua字符串 - > Redis批量回复
- Lua表(数组) - > Redis多批量回复(如果有的话,截断到Lua数组中的第一个nil)
- Lua表有单个
ok字段 - > Redis状态回复 - Lua表有单个
err字段 - > Redis错误回复 - Lua boolean false - > Redis Nil批量回复。
还有一个额外的Lua-to-Redis转换规则没有相应的Redis到Lua转换规则:
- Lua boolean true - > Redis整数回复,值为1。
还有两个重要的规则需要注意:
- Lua有一个数字类型,Lua数字。整数和浮点数之间没有区别。所以我们总是将Lua数转换成整数回复,删除数字的小数部分(如果有的话)。如果你想从Lua返回一个浮点数,你应该将它作为一个字符串返回,就像Redis本身一样(参见例如ZSCORE命令)。
- 有没有简单的方法有lua阵内尼尔斯,这是的Lua表语义的结果,所以当Redis的一个Lua阵列转换成Redis的协议如果遇到零的转换停止
Helper函数返回Redis类型
脚本的原子性
3.TIPS
having 字段
“Where” 是一个约束声明,使用Where来约束来之数据库的数据,Where是在结果返回之前起作用的,且Where中不能使用聚合函数。
“Having”是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在Having中可以使用聚合函数。
SELECT region, SUM(population), SUM(area) FROM bbc GROUP BY region HAVING SUM(population)>1000000
1》当分组筛选的时候 用having
2》其它情况用where
用having就一定要和group by连用,
用group by不一有having (它只是一个筛选条件用的)
只要条件里面的字段, 不是表里面原先有的字段就需要用having. SQL在查询表的时候先把查询的字段放到了内存里,而where查询的时候是从表里面查的,其余需要用having。
4.Share
阅读了 极客时间 的 深入拆解虚拟机 Java 基本类型
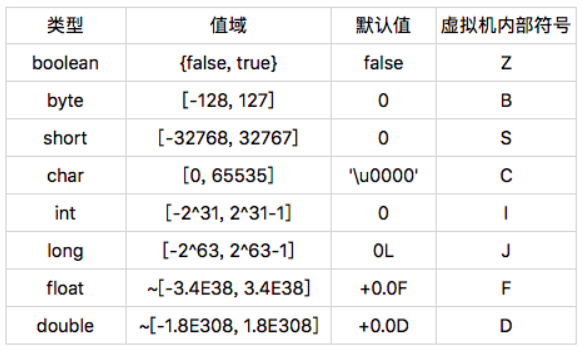
Java的基本类型都有对应的值域和默认值. 从图上看值域
依次扩大,前面的值域被后面的值域所包含,前面的值域转后面的无需强转,反之.在内存中默认值都是0.
除longhedouble外,其他基本类型与引用类型在解释执行栈帧中占用的大小是一致的,单数在对中占用的大小不同.