作者|Rashida Nasrin Sucky
编译|VK
来源|Towards Data Science
KNN分类器是一种非常流行的监督机器学习技术。本文将用一个例子来解释KNN分类器
什么是监督学习?
以下是百度百科:
监督学习是指:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
监督学习是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为向量)和一个期望的输出值(也称为监督信号)组成。监督学习算法是分析该训练数据,并产生一个推断的功能,其可以用于映射出新的实例。一个最佳的方案将允许该算法来正确地决定那些看不见的实例的类标签。
举个例子会更清楚
这是一个数据集,包含一些水果样本的质量、宽度、高度和颜色分数。
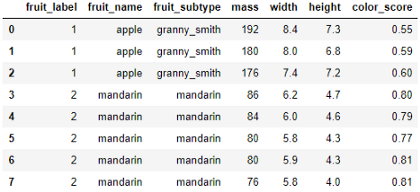
目的是训练一个模型,如果我们在模型中输入质量、宽度、高度和颜色分数,模型就可以让我们知道水果的名称。例如,如果我们输入一个水果的质量、宽度、高度和颜色分数分别设置为175、7.3、7.2、0.61,模型应该将水果的名称输出为苹果。
在这里,质量、宽度、高度和颜色分数是输入特征(X)。水果的名称是输出变量或标签(y)。
这个例子对你来说可能听起来很傻。但这是在监督机器学习模型中使用的机制。
稍后我将用一个真实的数据集展示一个实际的例子。
KNN分类器
KNN分类器是基于记忆的机器学习模型的一个例子。
这意味着这个模型会记住训练示例,然后他们用它来分类以前从未见过的对象。
KNN分类器的k是为了预测一个新的测试实例而检索的训练样本数。
KNN分类器分三步工作:
-
当给它一个新的实例或实例进行分类时,它将检索之前记忆的训练样本,并从中找出最近的样本的k个数。
-
然后分类器查找最近的例子的k个数字的标签(上面例子中水果的名称)。
-
最后,该模型结合这些标签进行预测。通常,它会预测标签最多的那个。例如,如果我们选择k为5,在最近的5个例子中,如果我们有3个橘子和2个苹果,那么新实例的预测值将是橘子。
资料准备
在开始之前,我建议你检查计算机中是否有以下可用资源:
- Numpy 库
- Pandas 库
- Matplotlib 库
- Scikit-Learn 库
- Jupyter Notebook
如果你没有安装Jupyter Notebook,你可以选择其他笔记本。我建议你可以使用谷歌公司的Colab。按此链接开始:https://colab.research.google.com/notebooks/intro.ipynb#recent=true
谷歌Colab Notebook不是私有的。所以,不要在那里做任何专业或敏感的工作。但对练习来说很棒。因为很多常用的软件包已经安装在里面了。
我建议下载数据集。我在页面底部提供了链接。你可以自己运行每一行代码。
首先,导入必要的库:
%matplotlib notebook
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
在本教程中,我将使用来自Kaggle的泰坦尼克号数据集。我已将此数据集上传到与我的笔记本相同的文件夹中。
下面是如何使用pandas导入数据集。
titanic = pd.read_csv('titanic_data.csv')
titanic.head()
#titaninc.head() 给出数据集的前五行。我们只打印前五行以检查数据集。

看第二列。它包含的信息,如果人活了下来。0表示该人幸存,1表示该人没有存活。
在本教程中,我们的目标是预测“幸存”特征。
为了简单起见,我将保留一些对算法更重要的关键特征,并去掉其余的。
这个数据集非常简单。仅仅凭直觉,我们可以看到有些列对于预测“幸存”特征并不重要。
例如,“PassengerId”、“Name”、“Ticket”和“Cabin”似乎对预测乘客是否存活没有帮助。
我将制作一个具有一些关键特征的新数据帧,并将其命名为titanic1。
titanic1 = titanic[['Pclass', 'Sex', 'Fare', 'Survived']]
“Sex”列具有字符串值,需要更改该值。因为计算机不懂单词。它只懂数字。我将把“男”改为0,“女”改为1。
titanic1['Sex'] = titanic1.Sex.replace({'male':0, 'female':1})
以下是titanic1数据帧的外观:
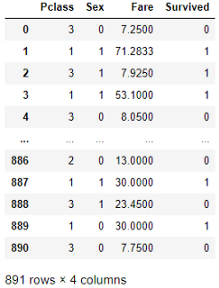
我们的目标是根据泰坦尼克1号数据帧中的其他信息预测“幸存”参数。因此,输出变量或标签(y)是“幸存”。输入特征(X)是'P-class'、'Sex'和'Fare'。
X = titanic1[['Pclass', 'Sex', 'Fare']]
y = titanic1['Survived']
开发KNN分类器
首先,我们需要将数据集分成两个集:训练集和测试集。
我们将使用训练集来训练模型,其中模型将同时记忆输入特征和输出变量。
然后,我们将使用测试集来检验模型是否能够使用“P-class”、“Sex”和“Fare”来预测乘客是否幸存。
“train_test_split”方法将有助于分割数据。默认情况下,此函数使用75%的数据得到训练集,使用25%的数据得到测试集。你可以改变它,你可以指定“train_size”或“test_size ”。
如果将train_size设置为0.8,则拆分为80%的训练数据和20%的测试数据。但对我来说,默认值75%是好的。所以,我没有使用train_size或test_size 参数。
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
记住对“random_state”使用相同的值。这样,每次进行这种拆分时,训练集和测试集的数据都是相同的。
我选择随机状态为0。你可以选择一个数字。
Python的scikit-learn库已经有了KNN分类器模型。进行导入。
from sklearn.neighbors import KNeighborsClassifier
将此分类器保存在变量中。
knn = KNeighborsClassifier(n_neighbors = 5)
在这里,n_neighbors是5。
这意味着,当我们要求我们的训练模型来预测一个新实例的生存概率时,它需要5个最近的训练数据。
基于这5个训练数据的标签,模型将预测新实例的标签。
现在,我将把训练数据拟合到模型中,以便模型能够记住它们。
knn.fit(X_train, y_train)
你可能会认为,当它记住训练数据时,它可以100%正确地预测训练特征的标签。但不一定,为什么?
每当我们给出输入并要求它预测标签时,它都会从5个最近的邻居那里投票,即使它记忆了完全相同的特征。
让我们看看它在训练数据上能给我们多大的准确度
knn.score(X_test, y_test)
训练数据的准确率为0.83或83%。
记住,我们有一个模型从未见过的测试数据集。现在检查一下,它能在多大程度上准确地预测测试数据集的标签。
knn.score(X_test, y_test)
准确率为0.78%或78%。
结合以上代码,下面是4行代码,它们构成了分类器:
knn = KNeighborsClassifier(n_neighbors = 5)
knn.fit(X_train, y_train)
knn.score(X_train, y_train)
knn.score(X_test, y_test)
恭喜!你学习了KNN分类器!
注意,训练集的准确度比测试集的准确度高一点。
什么是过拟合?
有时,模型对训练集的学习非常好,可以很好地预测训练数据集的标签。但是,当我们要求模型使用测试数据集或它以前没有看到的数据集进行预测时,它的性能如果远远不如训练集,这种现象称为过拟合。
用一句话来说,当训练集的准确度远远高于测试集的准确度时,我们称之为过拟合。
预测
如果要查看测试数据集的预测输出,请执行以下操作:
输入:
y_pred = knn.predict(X_test)
y_pred
输出:
array([0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0,
0, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0,
1, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1,
1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1,
0, 1, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0,
0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0,
1, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0,
1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1,
1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1,
0, 1, 1], dtype=int64)
或者你可以只输入一个例子,然后找到标签。
我想知道,当一个人乘坐“P-class”=3旅行时,“Sex”是女性,也就是说Sex=1,而且,付了25英镑的“车费”,她是否能按照我们的模型生存下来。
输入:
knn.predict([[3, 1, 25]])
记住使用两个括号,因为它需要一个二维数组
输出:
array([0], dtype=int64)
输出为零。这意味着按照我们训练过的模型,这个人无法生存。
请随时尝试更多不同的输入,就像这一个一样。
如果你想进一步分析KNN分类器
KNN分类器对k和n_neighbors的选择非常敏感。在上面的例子中,我使用了n_neighbors=5。
对于不同的n_neighbors,分类器的性能会有所不同。
让我们检查一下它在训练数据集和测试数据集上对不同n_neighbors的执行情况。我选1到20。
现在,我们将计算从1到20的每个n_neighbors的训练集准确率和测试集准确率
training_accuracy = []
test_accuracy = []
for i in range(1, 21):
knn = KNeighborsClassifier(n_neighbors = i)
knn.fit(X_train, y_train)
training_accuracy.append(knn.score(X_train, y_train))
test_accuracy.append(knn.score(X_test, y_test))
在运行了这个代码片段之后,我得到了针对不同n_neighbors的训练和测试准确度。
现在,让我们将训练和测试集的精确度在同一图中进行比较。
plt.figure()
plt.plot(range(1, 21), training_accuracy, label='Training Accuarcy')
plt.plot(range(1, 21), test_accuracy, label='Testing Accuarcy')
plt.title('Training Accuracy vs Test Accuracy')
plt.xlabel('n_neighbors')
plt.ylabel('Accuracy')
plt.ylim([0.7, 0.9])
plt.legend(loc='best')
plt.show()
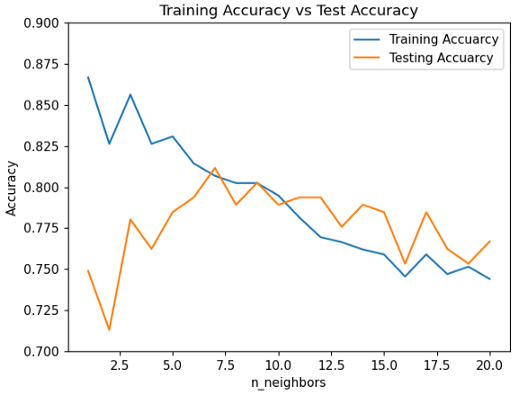
分析上面的图表
在一开始,当n_neighbors 为1、2或3时,训练准确率远远高于测试准确率。所以,这个模型正遭受着过拟合的困扰。
在那之后,训练和测试的准确性变得更接近了。这是最佳选择。我们想要这个。
但当n_neighbors变得更多时,训练和测试集的精确度都在下降。我们不需要这个。
从上面的图中可以看出,这个特定数据集和模型的理想n_neighbors 应该是6或7。
这是一个很好的分类器!
看上面的图表!当n_neighbors 为7时,训练和测试的准确率均在80%以上。
以下是完整代码的链接:
https://github.com/rashida048/Few-Machine-Learning-projects/blob/master/knn_with_titanic_data.ipynb
结论
我希望你学会了构建一个很好的KNN分类器,并将在不同的数据集上进行尝试。
非常感谢你阅读这篇文章!以下是我在本教程中使用的泰坦尼克号数据集:
https://github.com/rashida048/Few-Machine-Learning-projects/blob/master/knn_with_titanic_data.ipynb
推荐阅读
-
https://towardsdatascience.com/polynomial-regression-from-scratch-in-python-1f34a3a5f373
-
https://towardsdatascience.com/logistic-regression-in-python-to-detect-heart-disease-2892b138d0c0
-
https://towardsdatascience.com/series-of-free-courses-to-become-a-data-scientist-3cb9fd591739
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/