作者 | Revolver
一、具体代码和步骤
可视化我们的决策树模型的第一步是把模型训练出来。下面这个例子是在鸢尾花数据上,采用随机森林的方法训练出来的包含多棵决策树的模型,我们对其中一棵决策树进行可视化。
from sklearn.datasetsimport load_iris
iris = load_iris()
# 导入随机森林模型 (此处也可换成决策树模型)
from sklearn.ensembleimport RandomForestClassifier
model =RandomForestClassifier(n_estimators=10)
# 训练
model.fit(iris.data,iris.target)
# 提取单棵决策树
tree =model.estimators_[5]
训练好我们的模型之后,我们就可以用sklearn自带的export_graphviz函数将决策树模型转换成Graphviz格式。
from sklearn.treeimport export_graphviz
# 输出一个.dot格式的文件
export_graphviz(tree,out_file='tree.dot',
feature_names =iris.feature_names,
class_names =iris.target_names,
rounded = True, proportion =False,
precision = 2, filled = True)
参数含义:
precision 设置输出的纯度指标的数值精度
filled 指定是否为节点上色
max_depth 指定展示出来的树的深度,可以用来控制图像大小
需要下载Graphviz(一款图像可视化软件)来将 .dot文件转成 .png。下载地址见链接:https://graphviz.gitlab.io/download/。
有两种方式使用Graphviz这个工具,一种是执行pip install graphviz,然后可以在pyhton调用,另一种是使用命令行,这里我们采用第二种,但是是在python里调用的外部命令行。
# 临时将Graphviz添加到环境变量中
import os
os.environ["PATH"]+= os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/
# 将tree.dot文件转化为tree.png
from subprocess importcall
call(['dot', '-Tpng','tree.dot', '-o', 'tree.png', '-Gdpi=600'])
# 在jupyter notebook中查看决策树图像
from IPython.displayimport Image
Image(filename ='tree.png')
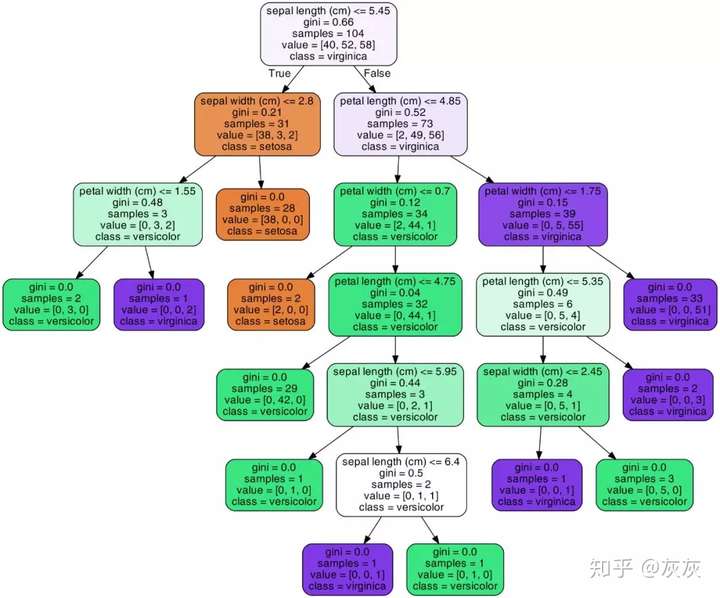
上图就是我们将决策树可视化之后的结果,根据每个节点中的文字内容,我们就可以知道,这个节点包含的数据纯度大小(基尼指数或熵值),选用了哪个属性以及属性值对数据进行再划分,样本量多少,还可以根据节点颜色的深浅来推断类别,不同颜色代表不同类别,颜色深度越浅说明各个类别的混杂程度高,颜色越深说明纯度越高。上图中绿、紫、土黄三个颜色就表示了鸢尾花的三种类别。
通过这样的图,我们可以直观的展示随机森林中的每棵树,甚至推断每棵树形成背后的原因。
二、一个例子
这里我再举一个应用决策树可视化的例子。比如你想知道基于最小熵选择划分属性生成决策树这种方法不能产生一棵最小规模的决策树,即基于最大信息增益的原则去选择最优划分属性。这里我就用可视化决策树的方法来向大家说明这种方法是否可行。现在有下面这样一份数据:
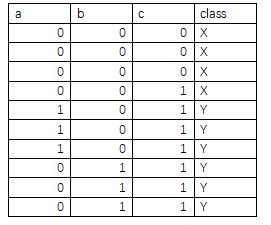
其中a,b,c为三个属性,class为类别,分X,Y两种。在第一次对数据集进行划分时,根据
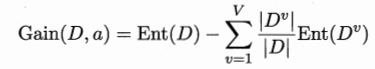
计算属性的信息增益,得
Gain(D,c)=0.557,Gain(D,a)= Gain(D,b)= 0.2816
这里若基于熵最小方法首先应选择c作为划分属性,最后可得决策树可视化如下图。
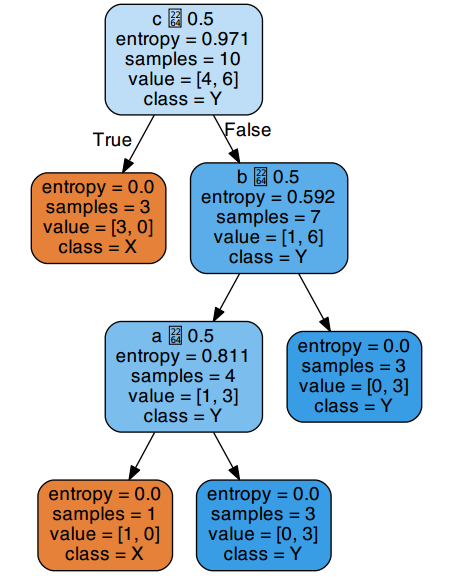
在这棵树中,a,b,c三个属性全部被用来进行划分,产生了三个分支节点。但如果我们采用属性a作为第一个划分属性,会得到一棵这样的决策树:
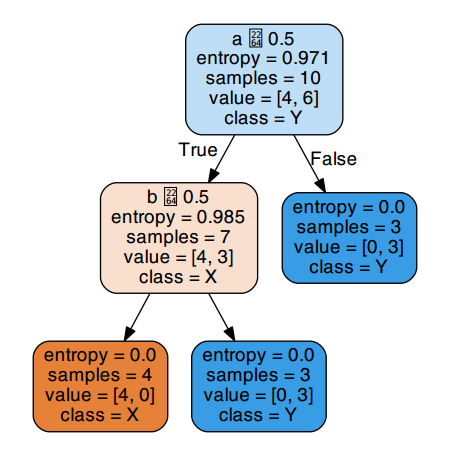
由图可知,其实仅仅用到a,b两个属性即可将数据集完全划分为一颗叶子节点熵为0的完整决策树,这棵树只有两个分支节点,三个叶子结点,其规模显然小于上面的决策树。这个例子说明了基于最小熵的方法生成的决策树规模不一定就是最小的。它只能在局部范围内取得纯度最高的类别划分,是局部最优,从整个生成整棵决策树所有节点的过程来看,它并不能保证生成的节点数是最少的。
怎么样,上面这些例子中,决策树可视化是不是让一切看起来简单明了!
三、总结
现阶段机器学习模型仍然存在着黑盒问题,一张图片并不能彻底解决此问题。尽管如此,观察决策树图的过程还是向我们展示了这个模型并非一个不可解释的方法,而是一系列被提出的逻辑问题和答案,正如我们平时进行预测时所采用的步骤那样。所以,你可以直接复制上面的代码,尽情把这个工具用到你自己的数据集上,解决你的问题吧。