之前的都是用区域建议算法来产生候选框,还是挺耗时间的,所以Faster R-CNN使用CNN来产生候选框。

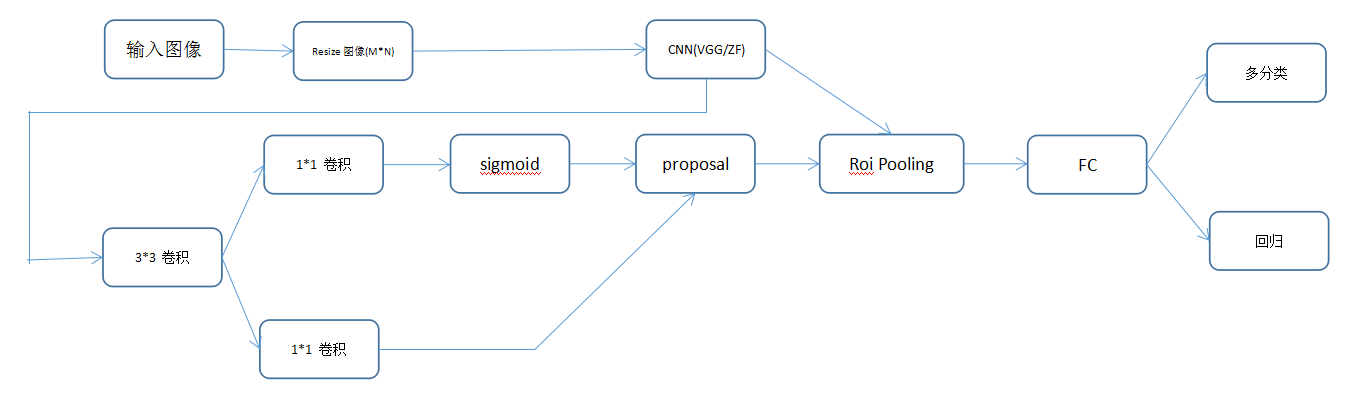
Faster-R-CNN算法由两大模块组成:
1.RPN候选框提取模块;
2.Fast R-CNN检测模块。
其中,RPN是全卷积神经网络,用于提取候选框;Fast R-CNN基于RPN提取的proposal检测并识别proposal中的目标。
思路:
1、输入图像,将图像固定最小边为600的大小(保证图像不发生变形);
2、经过一个训练好的网络,比如VGG等,得到特征图;
3、两条路:(1)输入到RPN网络中,(2)输入到ROI Pooling层中用于将anchor映射到原图中。
4、ROI
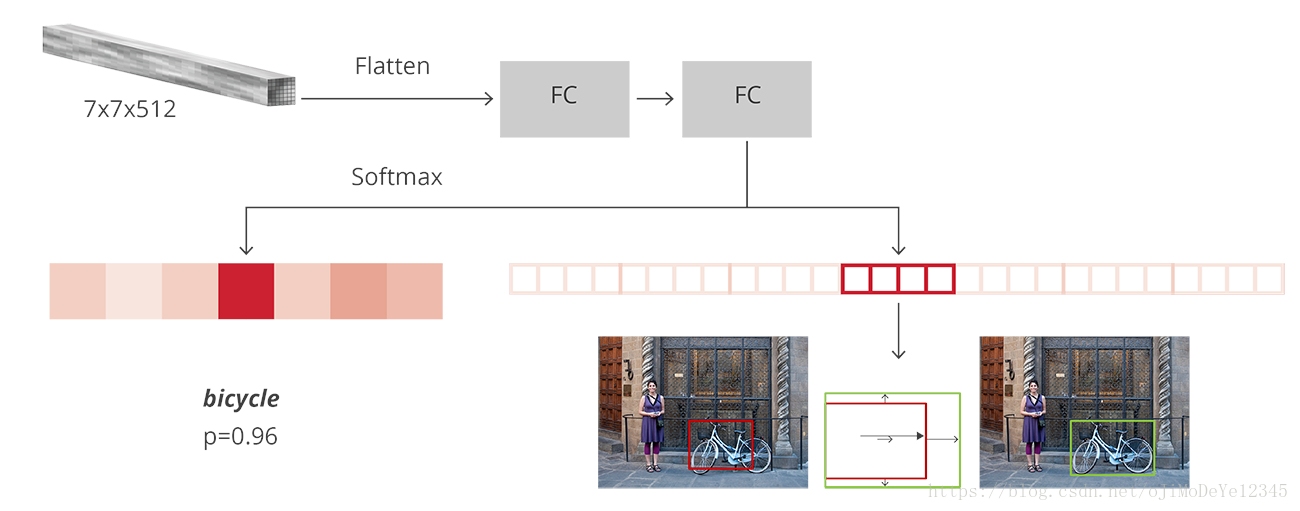
根据映射关系,提取框里的图像(在原图中),然后图像切分为7*7的小块,每一个小块使用max pooling,那么最后输出大小就是7*7,这样就统一了输入大小不一致得问题。
5、分类和回归网络。
损失函数:
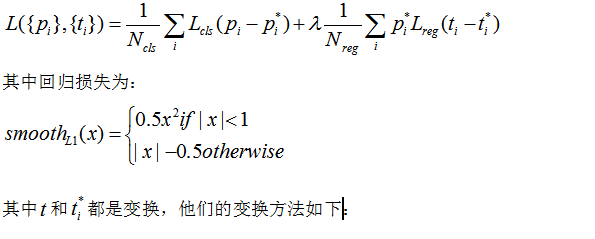

i 是每个小批量中锚点的序号;
p是锚点i是目标的概率
p*是标签(只能是0或1),
t是预测框的4个参数,
t*是标定框的参数
Lcls是分类损失函数,
Lreg是回归损失函数
p*i*Lreg表示回归只对正样本进行(负样本p*i=0)。
cls和reg分别输出pi和ti。
这两部分由Ncls(小批量的大小决定,这里是256)和Nreg(锚点位置数量决定,这里是2400)进行规范化,并通过一个平衡参数λ进行加权。
默认情况下,我们设置=10,因此cls和reg部分的权重大致相同。我们通过实验证明,结果对在大范围内λ的值不敏感。我们还注意到,上面的标准化是不需要的,可以被简化。
训练
1、预训练VGG,生成特征图
2、训练RPN
3、训练分类回归网络
评价:
评价准则:指定 IoU 阈值对应的 Mean Average Precision (mAP),如 mAP@0.5.