# -*- coding:utf-8 -*-
"""
1. 网页的解析方式
1) xpath(简单)
2) 正则(最难)
3) css(需要懂网页的css)
4) bs4(比xpath难一点点)
2. xpath的基本用法
1) 环境准备:
火狐浏览器(版本49.0以下)
firebug
firexpath
2) 基本操作
//元素标签名
例如: //div,查找网页内的所有div
//元素标签名[@属性名='具体内容']
例如: //div[@class='box'],查找class为box的div
//元素标签名[第几个]
例如: //div[@class='box'][2],查找符合条件的第2个div
//元素1/元素2/元素3...
例如: //ul/li/div/a/img,查找ul下的li下的div下的a下的img标签
//元素1/@属性名
例如://ul/li/div/a/img/@src, 查找ul下的li下的div下的a下的img标签的src属性
//元素/text()
例如://a/text(), 获取a标签之间的文本(一级文本)
//元素//text()
例如://div[@class='box']//text(), 获取class为div下的所有文本
//元素[contains(@属性名,'相关属性值')]
例如://div[contains(@class,'zhangsan')] 查找class中包含zhangsan的div
//*[@属性='值']
例如://*[@name='lisi']查找所有name为lisi的元素
"""
****************************(二)***********************************************
https://www.cnblogs.com/feng0815/p/8280581.html
由于最新版火狐不在支持FireBug等开发工具,可以通过https://ftp.mozilla.org/pub/firefox/releases/ 下载49版本以下的火狐就可以增加Firebug等扩展了。
什么是Xpath?
XPath是XML的路径语言,通俗一点讲就是通过元素的路径来查找到这个标签元素。
工具
Xpath的练习建议大家安装火狐浏览器后,下载插件,FireBug。
Xpath使用方法
注:默认死格式 先写 //* 代表定位页面下所有元素
1、Xpath支持ID、Class、Name定位功能
2、如果标签没有ID、Class、Name三总属性,Xpath还支持属性定位功能
3、当标签的属性重复时,Xpath提供了通过标签来进行过滤
4、当标签页重复时,Xpath提供了层级过滤
例如:找不到儿子,那么就先找他的爸爸,实在不行可以再找他的爷爷
5、一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。Xpath提供了索引过滤
6、上面几种如果都用上了之后还重复的话,我们就可以使用Xpath提供的终极神器,逻辑运算定位。and 或 or
******************************(三)*********************************************************
https://www.cnblogs.com/chenshaoping/p/5540434.html
1.xpath较复杂的定位方法:
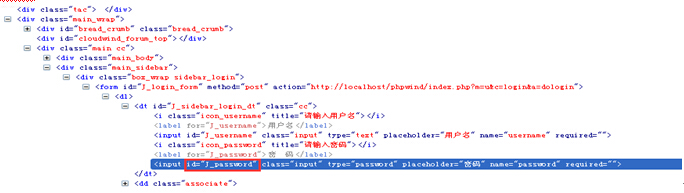
现在要引用id为“J_password”的input元素,可以像下面这样写:
WebElement password = driver.findElement(By.xpath("//*[@id='J_login_form']/dl/dt/input[@id='J_password']"));
其中//*[@id=’ J_login_form’]这一段是指在根元素下查找任意id为J_login_form的元素,此时相当于引用到了form元素。后面的路径必须按照源码的层级依次往下写。按照图所示代码中,我们要找的input元素包含在一个dt标签内,而dt又包含在dl标签内,所以中间必须写上dl和dt两层,才到input这层。当然我们也可以用*号省略具体的标签名称,但元素的层级关系必须体现出来,比如我们不能写成//*[@id='J_login_form']/input[@id='J_password'],这样肯定会报错的。
另外一种写法:WebElement password = driver.findElement(By.xpath("//*[@id='J_login_form']/*/*/input[@id='J_password']"));
2.xpath的模糊定位方法:
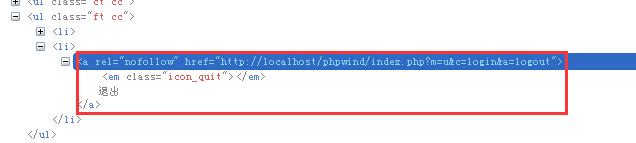
这段代码中的“退出”这个超链接,没有标准id元素,只有一个rel和href,不是很好定位。用xpath的几种模糊匹配模式来定位它,主要有四种方式:
a. 用contains关键字,定位代码如下:
driver.findElement(By.xpath(“//a[contains(@href, ‘logout’)]”));
这句话的意思是寻找页面中href属性值包含有logout这个单词的所有a元素,由于这个退出按钮的href属性里肯定会包含logout,所以这种方式是可行的,也会经常用到。其中@后面可以跟该元素任意的属性名。
b. 用start-with,定位代码如下:
driver.findElement(By.xpath(“//a[starts-with(@rel, ‘nofo’)]));
这种方式一般用于知道超链接上显示的部分或全部文本信息时,可以使用。
这句的意思是寻找rel属性以nofo开头的a元素。其中@后面的rel可以替换成元素的任意其他属性
c. 用Text关键字,定位代码如下:
driver.findElement(By.xpath(“//a[contains(text(), ’退出’)]));
直接查找页面当中所有的退出二字,根本就不用知道它是个a元素了。这种方法也经常用于纯文字的查找
d.如果知道超链接元素的文本内容,也可以用
driver.findElement(By.xpath(“//a[contains(text(), ’退出’)]));
3.XPath 关于网页中的动态属性的定位,例如,ASP.NET 应用程序中动态生成 id 属性值,可以有以下四种方法:
a.starts-with 例子: input[starts-with(@id,'ctrl')] 解析:匹配以 ctrl开始的属性值
b.ends-with 例子:input[ends-with(@id,'_userName')] 解析:匹配以 userName 结尾的属性值
c.contains() 例子:Input[contains(@id,'userName')] 解析:匹配含有 userName 属性值
参考网址:http://www.cnblogs.com/qingchunjun/p/4208159.html
xpath详解:http://www.cnblogs.com/ktgu/archive/2009/04/16/1353246.html
******************************(四)*****************************************************
http://www.w3school.com.cn/xpath/xpath_syntax.asp
/bookstore/book[1]
| 选取属于 bookstore 子元素的第一个 book 元素。 | |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
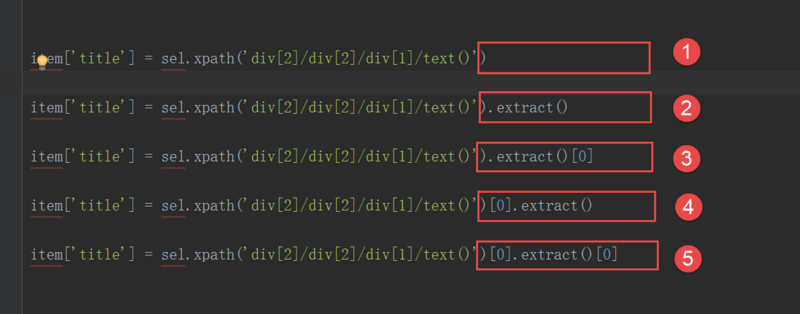
返回一个SelectorList 对象 http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/selectors.html#selectorlist
- SelectorList 类是内建 list 类的子类,提供了一些额外的方法:
- xpath(query)
- css(query)
- extract()
- re()
- __nonzero__()
返回一个list(就是系统自带的那个) 里面是一些你提取的内容
返回2中list的第一个元素(如果list为空抛出异常)
返回1中SelectorList里的第一个元素(如果list为空抛出异常),和3达成的效果一致
返回的是一个str(如果Python2为unicode应该), 所以5会返回str的第一个字符
hrefs = response.xpath('//div[@class="el"]/p/span/a/@href') print(hrefs) for url in hrefs: href = url.extract()