1. TCP报文结构
先把TCP报文段的格式放在这里,然后我们看图说话
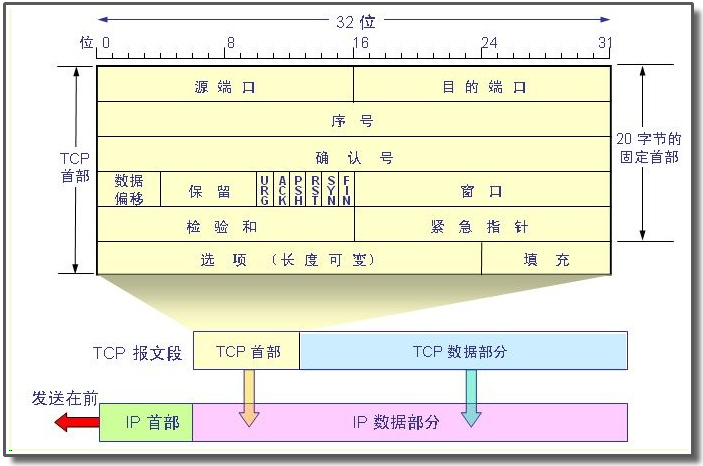
TCP报文段也分为首部和数据两部分,首部默认情况下一般是20字节长度,但在一些需求情况下,
会使用“可选字段”,这时,首部长度会有所增加。
说明:20字节是怎么出来的,不懂呀?
根据图中显示每段或者说每层是0-31bit,即每层长度是32位,字节和比特的换算公式应该都清楚
1字节=8bit,因此一层所占用的字节是32/8=4字节,根据图中所示,不算可选字段那层,
正好是5层,即5*4=20字节
2. TCP报文结构详细说明
表示网络访问来源处的端口号;即指定了发送端的端口
②.【目的端口】 <- 字段说明- (占用 16bit,即2字节)
表示网络访问目的处的端口号;即指定了接受端的端口号
说明:由上可以看出,源端口和目标端口都是占用了16bit/2字节,因此也可以通过计算得知源目端口号
的范围是2的16次方=65536,没错,是65536个。
但是为什么我们经常看到网上说可用端口最大65535个呢,也就是2^16-1个。
因为端口号是从0开始算的,0-65535那就是65536个。
而0端口是保留端口,无论是TCP还是UDP都是不用使用的
③.【序号】 <- 字段说明- (占用32bit,即4字节)
每一个TCP报文段都会有一个序号,序号字段的值其实是本报文段所发送的数据的第一个字节的序号。
这是因为TCP是面向连接的可靠服务,其每一个字节都会对应一个序号,
通过序号来确保服务的可靠性和有序性。
④.【确认号】 <- 字段说明- (占用32bit,即4字节)
确认号,是期望收到对方的下一个报文段的数据的第一个字节的序号。
说明:序号和确认号感觉根据说明似懂又非懂的感觉,还是有点晕,以我的个人理解进行一下说明
简单理解就是
发送端发送一个seq序列号x,接收端需要回复一个确认号x+1,并发送一个序列号Y
发送端接收一个seq序列号y,接收端需要回复一个确认号y+1
⑤.【数据偏移】 <-字段说明- (占用 4bit)
其实它本质上就是“首部长度”,因为“数据偏移”是指TCP报文段的数据部分的起始处距离
TCP报文段的起始处的距离。
数据偏移总共占4bit,因此最大能表示的数值为15。而数据偏移的单位是“4字节”,
此处的设计和IP数据报的设计是完全相同的,所以说TCP报文段首部的长度最长为15×4=60字节,
且首部长度必须为4字节的整数倍。
⑥.【保留字段】 <-字段说明-(占用 6bit)
这6bit在标准中是保留字段,我猜测,有两个目的,
第一个是预留除URG/ACK/PSH/RST/SYN/FIN/之外的冗余功能位;
第二个是为了对其字节位。
⑦.【控制字段】 <- 字段说明-(占用6bit)
✔【紧急字段URG】- 1bit
此字段告诉系统此报文段中有紧急数据,应尽快传送。当URG=1时
✔【确认字段ACK】- 1bit ★★★★
当ACK=1时,表示确认,且确认号有效;当ACK=0时,确认号字段无效。
✔【推送字段PSH】- 1bit
当PSH=1时,则报文段会被尽快地交付给目的方,不会对这样的报文段使用缓存策略。
✔【复位字段RST】- 1bit
当RST为1时,表明TCP连接中出现了严重的差错,必须释放连接,然后再重新建立连接。
✔【同步字段SYN】- 1bit ★★★★
当SYN=1时,表示发起一个连接请求。
✔【终止字段FIN】- 1bit
用来释放连接。当FIN=1时,表明此报文段的发送端的数据已发送完成,并要求释放连接。
⑧.【窗口字段】 <-字段说明-(占用16bit,即4字节)
此字段用来控制对方发送的数据量,单位为字节。
一般TCP连接的其中一端会根据自身的缓存空间大小来确定自己的接收窗口大小,
然后告知另一端以确定另一端的发送窗口大小。
⑨.【校验和字段】 <-字段说明-(占用16bit,即4字节)
这个校验和是针对首部和数据两部分的。
⑩.【紧急指针字段】 <- 字段说明-(占用16bit,即4字节)
紧急指针指出在本报文段中的紧急数据的最后一个字节的序号。
1 vim /etc/oldboy.txt 2 hosts name