个人项目-数独
Github地址
https://github.com/ZhaoYi1031/Sudoku
花费时间
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| ·Estimate | ·估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| ·Analysis | ·需求分析(包括学习新技术) | 60 | 120 |
| ·Design spec | ·生成设计文档 | 0 | 0 |
| ·Design Review | ·设计复审 | 0 | 0 |
| ·Coding Standard | ·代码规范 | 60 | 70 |
| ·Design | ·具体设计 | 120 | 180 |
| ·Coding | ·具体编码 | 180 | 900 |
| ·Code Review | ·代码复审 | 120 | 120 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 60 | 180 |
| Reporting | 报告 | 120 | 180 |
| ·Test Report | ·测试报告 | 5 | 5 |
| ·Size Measurement | ·计算工作量 | 10 | 10 |
| ·Postmortem & Process Improvement Plan | ·事后总结,并提出过程改进计划 | 10 | 20 |
| 合计 | 755 | 1795 |
思路描述
第一部分的生成数独,我第一感觉是上学期的学的离散数学3的生成排列与生成组合。比如通过引入逆序来确定唯一的排列给我的启发就是引入二维矩阵的类似逆序的概念来确定可以符合的二维矩阵再进行格式判定;比如反射格雷码法以一个规则不断变化当前01序列,来确定排列。因此我们也可以对一个初始的数独进行变化,比如矩阵的行变换列变换等等。
不过分析之后,我还是选择了最容易想到的方法,回溯按顺序来找出合法的数独。这样的选择是因为不管是随机产生、还是通过矩阵变换或者其它,当需要生成的矩阵数目比较多的时候,可能碰到后期出解的概率减少,而且判重的时间消耗会增加这样的问题。而回溯暴力寻找的好处此时就体现:
- 不需要判重。因为按顺序找出来的肯定是不同解
- 时空复杂度相对都不错。而且稳定性好,不会有随机化带来的不均衡问题
- 编程复杂度低
具体的回溯做法就是从第一行第二列(因为第一行第一列已被填掉)往右来填,来寻找1-9中能填的数字来填到这个方格里。每填一个各自就把该行/列/九宫格的这个数字标记为不可填。每次到行末就调到下一行继续执行。
第二部分求解数独。之前看《挑战程序设计》时看过搜索的剪枝问题就提到了数独,也以前刷poj的时候被一道数独题给卡住,当时那道题网上的标算清一色都是dancing link,用交叉十字循环双向链来做一个精确覆盖。虽然我知道dancing link肯定效率上会比搜索会高,但是这次我却固执地想要通过搜索来解决这次的数独问题。搜索优化的策略自己之前看书的时候有点印象,就是改变搜索的次序。然后自己主要想了想用什么数据结构来存储81个顶点的信息、实现起来会比较好。
优先队列
一开始我想起它的原因是因为每次我们要取出限制最多的点来填,这正好与优先队列这种最小的始终保持在队首的性质是一致的。pass的原因是我每次填完一个点需要对这一列、这一行以及这个九宫格的这20个点进行信息更新,要先取出这些点删掉再插入进去。取的复杂度是O(81)太高。
二叉排序树/平衡二叉树
考虑过c++的set。优缺点基本同priority_queue,扔掉。
考虑过关联容器multimap。key值是限制数,里面存放的是满足限制数等于key的顶点。由于我们每次需要取出限制大的点来填,而按照索引建好之后我们正好可以从key最大的来取。但由于实现起来相对编程复杂度较高,最终我还是选择了用数组来存取。
实现过程
第一部分初始版就是裸的回溯,用了很多的小优化,具体见下一点改进程序性能上。这部分写的时间相对也较短。
主要时间都花在了第二部分的求解数独上。本来按照原来的设计,自己也很快就实现了,但是为了死磕一道OJ题,愣是苦战了3天才调的不超时。每次在本地一测1.2s,1.1s然后被OJ卡一个“Time Limit Exceeded”真是崩溃。当时那三天基本都是下图这种节奏。最终发现当增加了一个小优化后,不再超时了。
一个主要的概念是每个点的限制数。已经填好元素的限制为8(代表只有1个元素可以填) 然后每填一个位置的元素后,我们都去更新该行、该列、该九宫格的其它元素的限制数,如果某一点的限制数达到了8,我们继续更新这个点(这样重复操作就使得我们能够将先期不需要回溯就解决的点全部填掉,避免后期回溯在这些点上浪费时间)
主体的流程图如下:
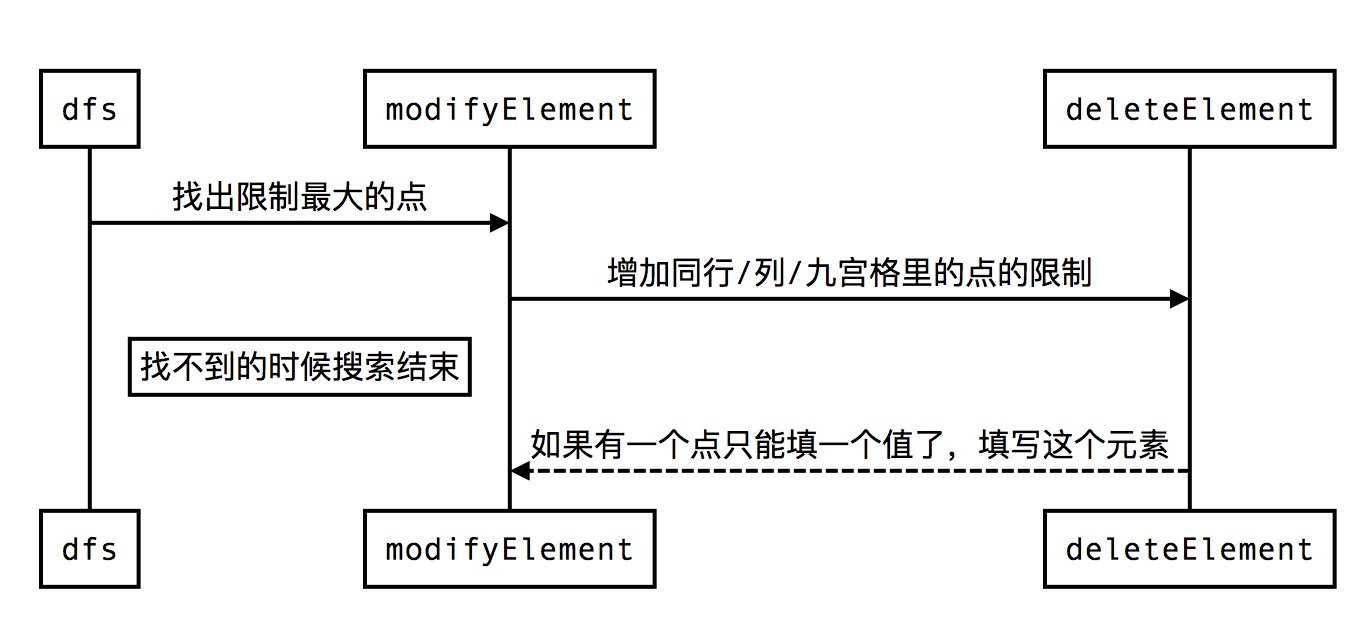
在这里必须提下最后这个从deleteElement指回的这条虚线,这就是我上文提到的那个小优化。之前写的时候我忽视了这一点,但在实际的运行中这是非常有效的。尤其是当0的个数不是很多的时候,我们每次填完一个元素更新的时候都可能在删除时发现另外一个点的限制达到了8,也就是只剩一个元素可以填了,这是我们应当立即来填这个元素。另外,当我们试图填一个元素,却发现不能填的时候,显然这种修改或者说回溯的策略是有问题的,需要我们回溯修改。
单元测试主要包括两部分,是否是合法的数独以及是否与题意是一致的。第二点只有第二部分求解数独有。针对这两个判断我写了如下两个函数,并对第一部分进行了1、10、100、1000、10000的检测数独以及几个参数,第二部分进行了几个不同类型数独的测试。两个主要检测的函数的代码如下:
bool check(int a[M]) {//判断终盘是不是一个数独
rep(i, 0, 80) {
a[i] -= '0';
if (a[i] < 0 || a[i] > 9)
return false;
}
bool vis_col[N][N], vis_row[N][N], vis_magic[N][N];
memset(vis_col, false, sizeof(vis_col));
memset(vis_magic, false, sizeof(vis_magic));
memset(vis_row, false, sizeof(vis_row));
int x, y;
rep(i, 0, 80) {
x = i / 9;
y = i % 9;
if (vis_col[x][a[i]] || vis_row[y][a[i]] || vis_magic[belonging(x, y)][a[i]])
return false;
vis_col[x][a[i]] = true;
vis_row[y][a[i]] = true;
vis_magic[belonging(x, y)][a[i]] = true;
}
return true;
}
bool check2(int a[M], int b[M]) {
rep(i, 0, 80) {
if (b[i] > 0 && a[i] != b[i])
return false;
}
return true;
}
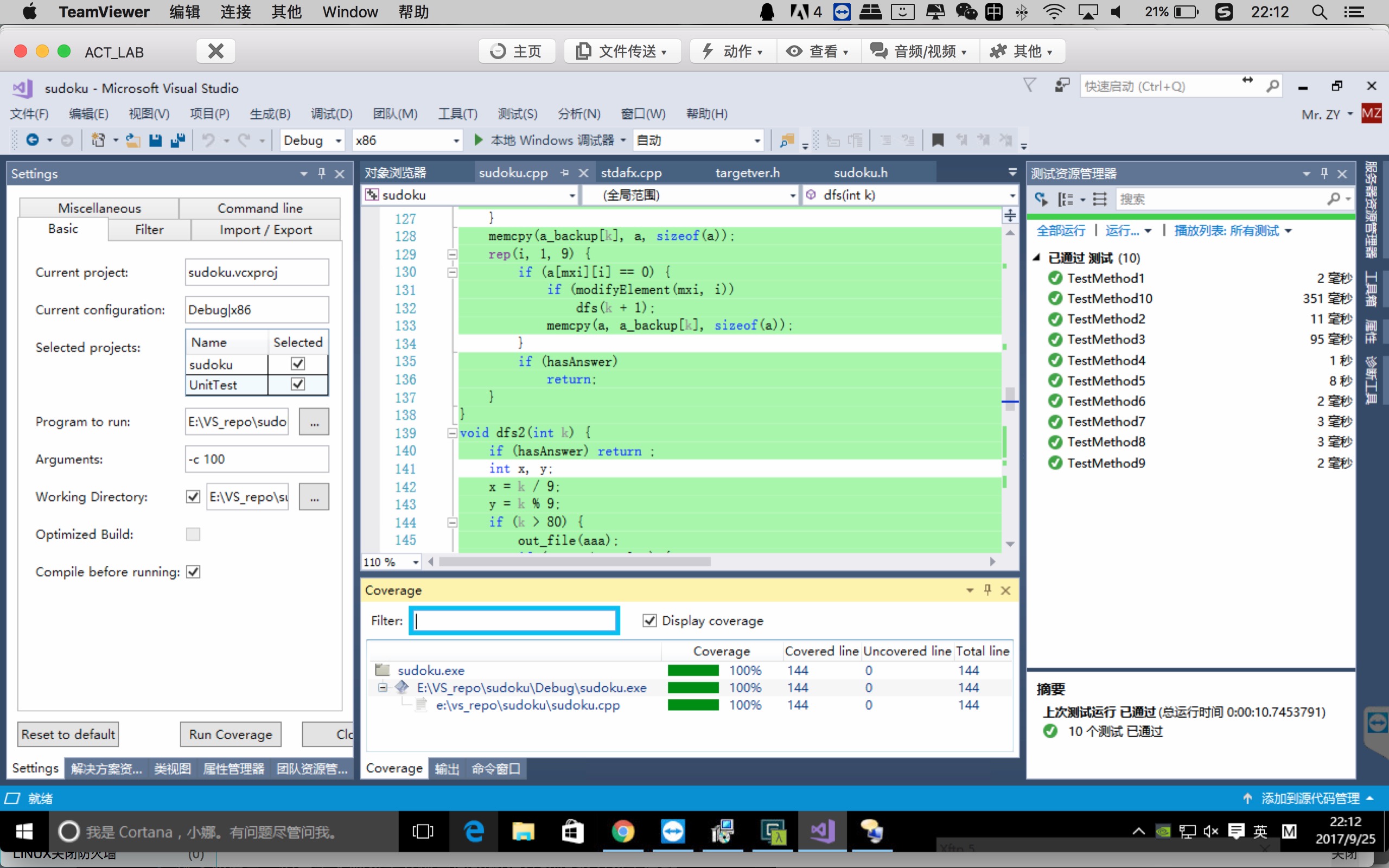
测试及代码覆盖率如下图:
改进程序,优化性能
代码1的改进主要在IO的优化上。根据实测,输出的时间速度上,流输出 < fputs < fprintf < fwrite. 另外,在输出的时候,我们要尽可能地拼在一起输出,而不是一个个的数字进行输出。用到的其它的小优化包括:
- 用一维数组a[81]取代a[9][9]
- 所有的下标从0开始而不是从1开始。这样的优势在于计算相应的行号和列号的时候,直接用pos/9, pos%9就行了,避免了从1开始需要的判断和加法操作
- 尽可能减少数组的拷贝,因为回溯需要记录状态而需要拷贝状态,而拷贝数组是一个比较耗时的操作,因此需要减少,在第二部分中最终我只精简到拷贝了那个存放顶点限制数的数组
- 尽管将所有数独的输出拼到一个字符数组输出会更节约时间,但是由于这样会牺牲非常大的空间(因为100w的数独大概需要2e8这么大空间)因此最终我还是只是算出一个数独就输出,时间上稍微慢了点(大概在0.5s),但空间上瞬间从1e8下降为1e4的级别
- 针对几个使用频繁的简单函数,例如计算属于第几个方格,采用内联函数避免多次编译
在这里我主要举一个我通过性能分析发现的瓶颈并进行改进的例子,发现了STL的string的+操作是一个非常耗时的操作。通过下图可以看到,string的+操作占了1933毫秒。可以说是非常耗时了!
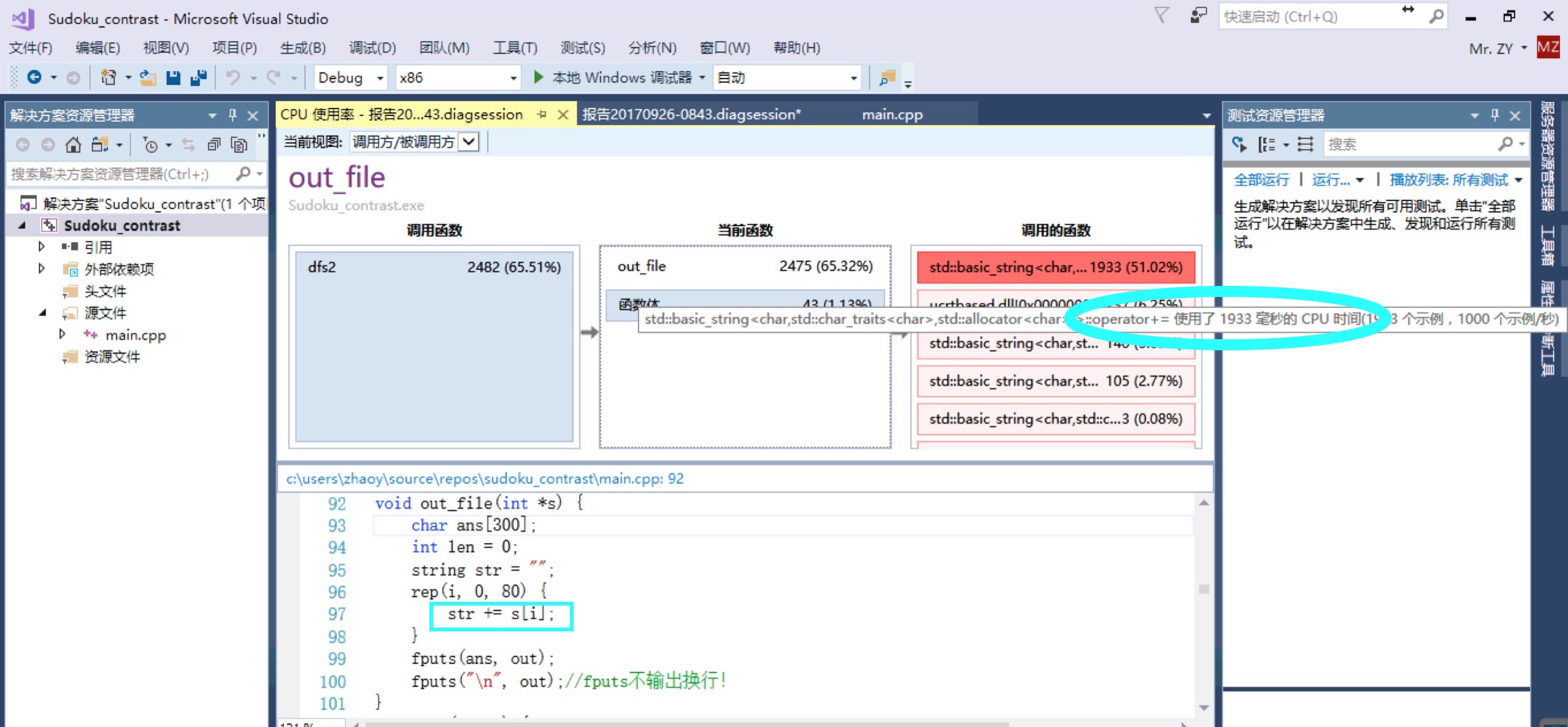
当我们将string改成字符数组直接赋值后,速度立马就上去了,输出的out_file时间只剩下54ms了,如图:
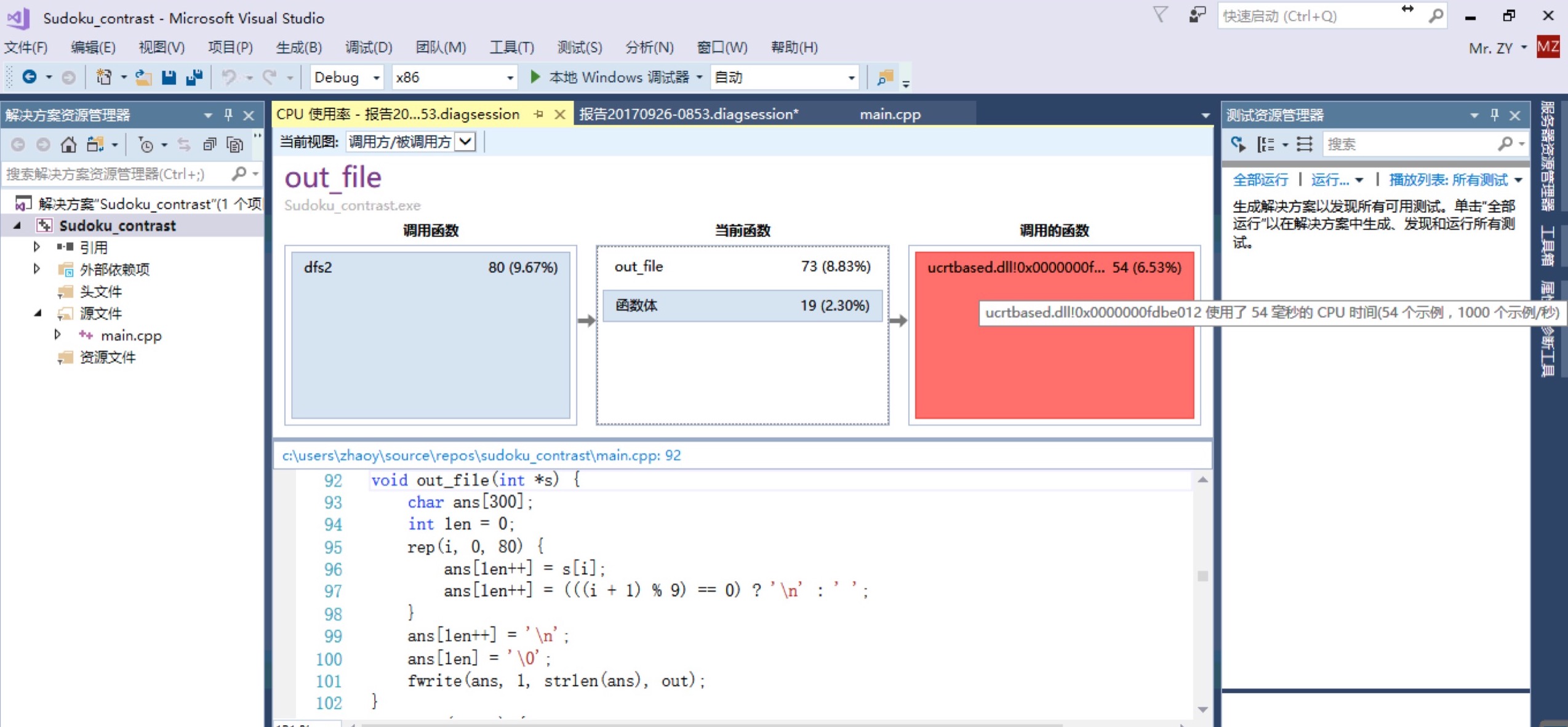
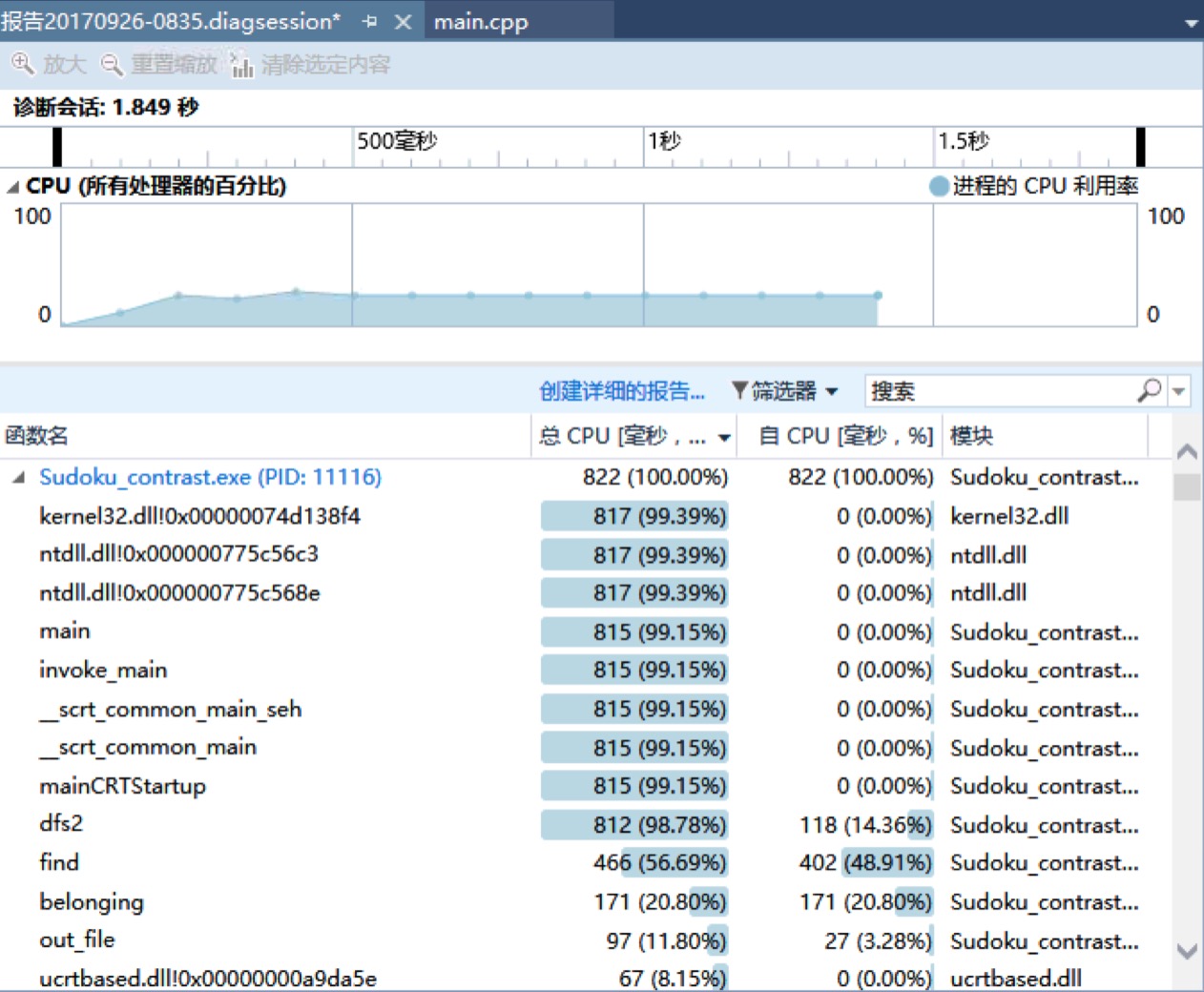
最终的性能分析表如下,输出100万个数独的总时间是1.849秒,可以看到main函数占比都很小了:
代码说明
主要列举部分2的两个主要函数modifyElement和deleteElement来分析说明,其中a[i][j]代表数独中第i位置有没有j的限制,1代表限制即不能填,0代表能填。初始的时候都是0代表每一个位置可以填1~9。两个函数返回true代表可以修改/删除,否则就是和现有的情况矛盾。
bool modifyElement(int pos, int r) {//把pos位置填上r
int p = pos / 9;//行号
int q = pos % 9;//列号
int h;
x[pos] = r;
rep(i, 1, 9)
a[pos][i] = 1;
a[pos][0] = 8;//限制数为8代表只有r一个值可以填
a[pos][r] = 0;//除了r可以填其它都标记为不能填
rep(j, 0, 8) {//同行的元素增加限制
h = Position(p, j);
if (h != pos && !deleteElement(h, r))
return false;
}
rep(i, 0, 8) {//同列的元素增加限制
h = Position(i, q);
if (h != pos && !deleteElement(h, r))
return false;
}
rep(i, 0, 2)//同九宫格的元素增加限制
rep(j, 0, 2)
{
h = (3 * (p / 3) + i) * 9 + (3 * (q / 3) + j);//简单推导可得
if (h != pos && !deleteElement(h, r))
return false;
}
return true;
}
bool deleteElement(int pos, int r) {
int i;
if (a[pos][r] == 1)//如果这个pos位置不能填i,代表之前已经删除过,直接返回true
return true;
a[pos][r] = 1;
if (++a[pos][0] == 9)//增加了一个限制后,没有可填的元素了,直接返回false
return false;
if (a[pos][0] == 8)//优化!某一个点只剩一个元素可以填,那么这个点的值也就固定,我们应当立即去modify这个点的值。
{
for (i = 1; i <= 9; ++i)
if (a[pos][i] == 0)//找到是哪个值可以填
break;
if (!modifyElement(pos, i))
return false;
}
return true;
}
GUI
与partner的合作下,基本造完轮子了
功能暂时还比较少owo
效果图如下:
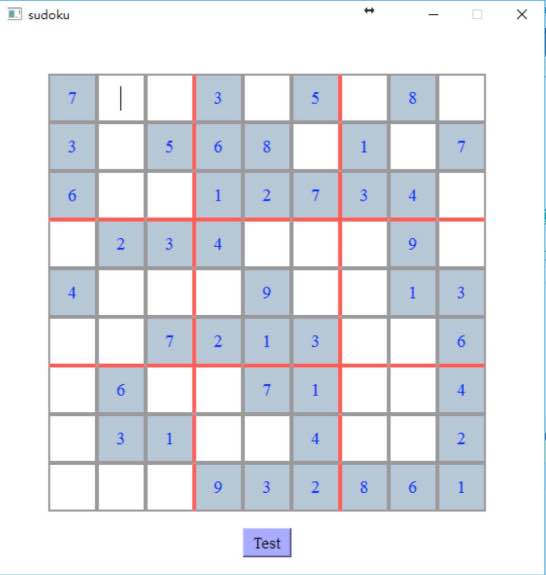
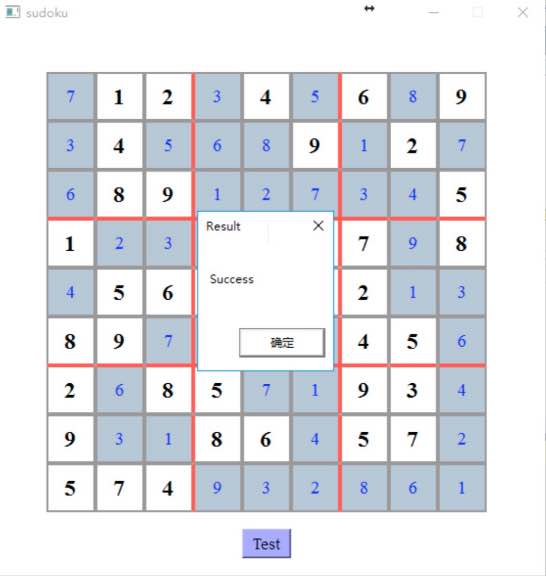
填完之后可以进行检测:
总结
"倔强"地没有选择dancing link而是搜索优化让我在前期的优化性能上耗费了太多时间。以及从mac上习惯的xcode转战到visuo studio也是折腾了好一番(主要Teamviewer远程连着实验室的Windows在操作,有些不方便),因此最后想实现的GUI一直被拖。不过算是自己的一个一周内一直在写的一个小项目吧,希望后面能继续改进一些优化以及单元测试,还有希望能更熟悉一下git的托管(我现在主要还是习惯写好了再一起commit导致基本都是到最后才一起git) 以及虽然现在功能不复杂,还是用类封装一下比较好吧。
路漫漫其修远兮,吾将上下而求索